A coding agent that can read your repository, run shell commands, edit files, install packages, build containers, talk to external APIs, and open browser sessions is not just a better autocomplete. It is an execution environment with a language model attached. Claude Code’s own docs describe it as an agentic coding tool that reads your codebase, edits files, runs commands, and integrates with development tools. LangChain’s Deep Agents docs describe sandbox backends as the place where agents execute shell commands, manipulate filesystems, and delegate work to subagents. Docker now ships Sandboxes specifically for AI coding agents, and Freestyle puts the phrase “Sandboxes for Coding Agents” directly on its home page. (Claude API Docs)
That change matters because once the model can act, the main security question stops being “How accurate is the model?” and becomes “What can this thing touch when it is wrong, manipulated, or overconfident?” OpenAI’s agent safety guidance calls prompt injection a common and dangerous risk and explicitly warns that malicious text can push agents toward unintended actions, including data exfiltration through downstream tool calls. NIST frames the same class of problem as agent hijacking, a form of indirect prompt injection in which malicious instructions are hidden in content an agent consumes. (OpenAI Developers)
That is why sandboxes matter. Not because they make models trustworthy, and not because they solve prompt injection, but because they define the blast radius when a coding agent inevitably does something you did not mean to authorize.
Why coding agents need sandboxes
The first mistake teams make is treating coding agents as if they were simply chatbots with stronger file access. The major coding-agent platforms do not behave that way. Claude Code is documented as a tool that can inspect a codebase, edit files, run commands, and work across development tasks. LangChain’s Deep Agents can execute shell commands through sandbox backends, persist memory, swap filesystem backends, and delegate subtasks to specialized subagents for context isolation. Docker Sandboxes supports out-of-the-box agent templates for Claude Code, Codex, Copilot, Gemini, Kiro, OpenCode, and Docker Agent. (Claude API Docs)
That capability set is exactly what makes these systems useful. It is also what makes them operationally dangerous. Once an agent can run pytest, install npm packages, open a branch, or inspect a build failure, it is only a few tool calls away from doing something with much higher consequence: editing a deployment script, leaking a token to a remote service, modifying a Git hook, or standing up a container that runs code you did not audit.
The intuitive answer is often “just require approvals.” That helps, but it does not hold up well as the only control. Anthropic’s quickstart says Claude Code asks for permission before modifying files, and Anthropic’s March 2026 write-up on auto mode says users approved 93 percent of permission prompts. That number is telling. If nearly every prompt is approved, permission dialogs are serving partly as ceremony, not as a reliable boundary. Docker’s sandbox template for Claude Code goes even further and documents that its base image launches Claude Code with --dangerously-skip-permissions by default, effectively replacing fine-grained interactive prompts with runtime isolation and surrounding controls. (Claude API Docs)
OpenAI’s guidance lands on the same practical conclusion from a different direction. Its agent safety documentation argues that the goal cannot be perfect detection of malicious input. The more reliable strategy is to design systems so the impact of manipulation is constrained even when the manipulation succeeds. In other words, the model can remain fallible if the environment is bounded well enough. (OpenAI)
A sandbox is the engineering expression of that idea.
What a coding agent sandbox actually isolates
A real sandbox is not just “somewhere else to run code.” It is a bundle of boundaries.
The first boundary is the filesystem boundary. The agent should be able to read and write only the working tree or volumes explicitly mounted for it. Anything outside that scope should not be reachable. LangChain describes sandboxes as the boundary that prevents the agent from reaching host files. Docker’s security model is even more concrete: the primary trust boundary is the microVM, and only the explicitly shared workspace crosses into it. (LangChain Docs)
The second boundary is the process and kernel boundary. If the agent installs packages, launches services, starts containers, or spawns subprocesses, those actions must stay inside an execution environment that does not share host processes or an unguarded host kernel. Docker’s isolation docs emphasize that each sandbox has its own microVM and Linux kernel. Firecracker’s design docs describe the virtualization boundary as the first layer of isolation, then add seccomp, cgroups, namespaces, and jailing for defense in depth. (Docker Documentation)
The third boundary is the network boundary. Coding agents are unusually network-hungry. They want to install dependencies, fetch docs, call LLM APIs, query GitHub, and sometimes scrape the web or talk to MCP endpoints. Without a network policy, “sandboxed” can still mean “free to exfiltrate.” Docker’s default posture blocks outbound HTTP and HTTPS unless rules allow it, blocks all raw TCP, UDP, and ICMP, and also blocks traffic to private IP ranges and host-local addresses. GKE Agent Sandbox frames the same issue as strong process, storage, and network isolation for untrusted code. (Docker Documentation)
The fourth boundary is the credential boundary. A sandbox is not much of a boundary if the agent can simply read the API keys you meant to protect. Docker’s design avoids passing raw provider secrets into the VM by using a host-side proxy that injects credentials into outbound HTTP headers. Its docs are explicit that the raw credential values never enter the VM. (Docker Documentation)
The fifth boundary is the lifecycle boundary. Agent work is rarely one shot. A useful sandbox has to support a start state, a working state, a paused state, and a deleted state. It has to preserve the right things and destroy the right things. E2B documents isolated filesystems, background commands, mounted volumes, and the ability to connect to running sandboxes. Freestyle documents suspend, stop, snapshot, fork, idle timeout, and deletion. Daytona documents creating sandboxes from snapshots and controlling auto-stop, auto-archive, and auto-delete intervals. (E2B)
That distinction matters because an agent runtime that cannot preserve state is slow and clumsy, while an agent runtime that preserves everything forever becomes a long-lived target.
Isolation models for coding agents
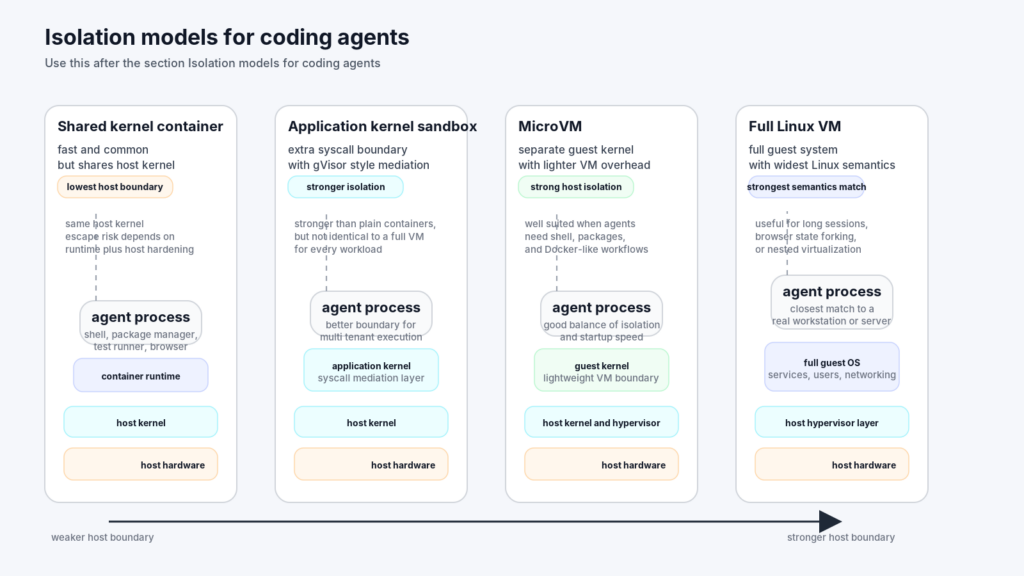
Teams often discuss “sandboxing” as if there were a single implementation. There is not. The security properties of a shared-kernel container, a gVisor sandbox, a microVM, and a full Linux VM are materially different.
Here is the practical way to think about the design space.
| Isolation model | Kernel boundary | Typical strength | Main tradeoff | Best fit |
|---|---|---|---|---|
| Shared-kernel container | No separate guest kernel | Fast startup, mature tooling, cheap density | Escape risk is tied directly to host kernel and runtime hardening | Trusted internal automation with low-risk actions |
| Application-kernel sandbox such as gVisor | Additional software boundary above host kernel | Stronger syscall mediation, good fit for cluster-native platforms | Not identical to full Linux semantics, may need tuning | Multi-tenant code execution in Kubernetes |
| MicroVM | Separate lightweight guest kernel | Stronger host isolation with relatively fast startup | More overhead than containers, more lifecycle complexity | Autonomous agents that need shell, packages, and Docker-like workflows |
| Full Linux VM | Separate full guest system | Full Linux semantics, strong workload isolation, broad compatibility | Higher resource cost, more state to manage | Long-running agent workbenches, browser-heavy flows, nested virtualization |
That table is a synthesis, but the pieces behind it are not hypothetical. gVisor describes itself as a sandbox made up of multiple processes, with a Sentry that intercepts and responds to system calls. Google’s GKE Agent Sandbox uses gVisor to create a barrier between the app and the cluster node. Firecracker positions microVMs as combining hardware-virtualization isolation with the speed and flexibility of containers. Kata Containers describes its goal as lightweight VMs that feel like containers while keeping the isolation advantages of VMs. Freestyle goes one step further in its own product language and says plainly: not containers, full Linux VMs with real root access. (gVisor)
This is where many “agent sandbox” discussions become sloppy. A shared-kernel container is not automatically bad. It may be completely appropriate for internal tooling you already trust. But when people say they want to let a coding agent install arbitrary packages, build images, run browsers, or execute unreviewed shell commands, the isolation conversation changes. The question is no longer whether the runtime is convenient. The question is what boundary fails first when the agent is manipulated.
Docker’s architectural comparison to alternatives makes this point cleanly. It contrasts microVM sandboxes with a container that mounts the host socket, with Docker-in-Docker, and with direct host execution. Its conclusion is not ideological. Sandboxes cost more because they include a VM and an isolated daemon. But that trade buys a meaningful boundary when you want to give something autonomous full Docker capabilities without trusting it with your host environment. (Docker Documentation)
Freestyle highlights a different side of the trade. Its product model is built around full Linux VMs, complete networking, real root access, systemd services, and nested virtualization. That makes sense if your agent needs semantics that are awkward to fake inside a more constrained environment, especially when browser state, parallel forking, or VM-in-VM workflows matter. (Freestyle)
The right choice is not about brand loyalty. It is about the job shape. If your core problem is cluster-native multi-tenant code execution, gVisor or Kata-backed approaches may be enough. If your core problem is an autonomous coding agent with shells, Docker, package managers, branching, and live state, microVMs or full VMs usually map more naturally.
Speed, state, and branching matter more than most teams expect
A sandbox that is secure but too slow will be bypassed. That is one of the most predictable outcomes in developer tooling.
Coding agents do not behave like nightly batch jobs. They bounce between reading, editing, compiling, testing, calling tools, and waiting on humans. They open several hypotheses, abandon some, and resume others. That means the runtime has to be optimized for interactive iteration, not just for one-time execution.
Freestyle’s VM docs are unusually explicit about this. They say VMs provision in under 800 milliseconds from API request to running machine, suspend and resume in under 100 milliseconds, and can be forked mid-execution with minimal performance impact. Their docs also explain why: memory snapshots and cached layers make startup fast, while suspend preserves the exact memory state rather than forcing a full reboot. The examples are written for app builders and browser-based agents, but the pattern is broader. If an agent reaches an interesting browser state or partially built dependency graph, being able to fork that state is dramatically better than recreating it from scratch twenty times. (Freestyle Documentation)
Google’s GKE Agent Sandbox reveals a cluster-native version of the same idea. Its documentation defines both a SandboxTemplate, which serves as a reusable blueprint, and a SandboxWarmPool, which keeps pre-warmed pods ready to be claimed. That is not just a Kubernetes nicety. It is a concession to the reality that autonomous systems need warm capacity if you want human-perceived responsiveness. (Google Cloud Documentation)
Daytona’s docs describe another useful pattern: creating sandboxes from snapshots and then controlling the post-run lifecycle with auto-stop, auto-archive, and auto-delete intervals. That feature set speaks to a familiar agent problem. Some sessions are active development environments. Some are short-lived experiments. Some are dormant but worth keeping around as exact baselines. One lifecycle policy is not enough. (Daytona)
E2B’s documentation covers the operational side that often gets ignored in architecture diagrams. It supports background commands, directory watching, isolated filesystems, persistent volumes that outlive sandbox lifecycles, and mounts that let a volume be reused across multiple sandboxes over time. Those are not bells and whistles. They are the difference between an agent that can run a dev server and wait for logs, versus an agent that can only fire off one-off commands and lose context. (E2B)
A useful way to evaluate a platform is to ask four operational questions:
| Capability | Why it matters for coding agents | What breaks when it is missing |
|---|---|---|
| Fast startup or warm pool | Keeps iteration loops usable | People stop waiting and fall back to local execution |
| Pause, resume, and auto-stop | Preserves state without burning idle compute | Long sessions become expensive or are killed too aggressively |
| Snapshots and forks | Lets agents branch from a known-good state | Complex exploration becomes slow and non-reproducible |
| Background jobs and persistent storage | Supports build servers, test runners, browsers, and logs | The sandbox feels stateless even when the work is not |
The platforms above implement these ideas differently, but the lesson is consistent: for coding agents, isolation is only half the design. The other half is state management.
Secrets, network policy, and workspace trust are the real control plane
A team can get the isolation primitive right and still build an unsafe system.
Docker’s current sandbox documentation is helpful because it is unusually candid about what the agent can still do. The primary trust boundary is the microVM, but inside the VM the agent has full control, including sudo privileges. The workspace is mounted read-write. With the default direct mount, file changes appear on the host immediately. Network traffic is deny-by-default, but allowed HTTP and HTTPS requests are proxied through the host. Credentials can be injected by the host-side proxy without exposing raw values inside the VM. (Docker Documentation)
That is a strong model, but it is not the same as “the agent cannot hurt me.” Docker’s docs explicitly warn that while the host is isolated, the shared workspace is not harmless. If the agent edits files that humans later execute — Git hooks, CI configs, IDE task configs, Makefile, package.json scripts, build files — the damage can cross the boundary when a human or pipeline runs those files later. They even call out the fact that Git hooks in .git/ do not show up in git diff. That is the kind of detail teams forget until it bites them. (Docker Documentation)
This is the right mental model:
- Host isolation protects your machine.
- Workspace trust protects your future self.
- Network policy protects the outside world and your data.
- Credential handling protects the identities your agent can act through.
Those planes must be designed together.
The credential plane is especially subtle. Docker’s default posture says no credentials are available unless you provide them, and when they are provided, the host-side proxy injects them into outbound HTTP headers so the raw values do not enter the VM. The shell sandbox docs repeat the same idea for supported providers and state that credentials are never stored inside the sandbox in that flow. That is much better than dropping API keys into environment variables inside the agent runtime. (Docker Documentation)
But the model has an edge case that matters in practice. Docker’s FAQ explains that if you need a custom variable that is not supported by the proxy flow, you can write it into /etc/sandbox-persistent.sh. The docs also warn that this stores the value inside the sandbox, where the agent process can read it directly. The difference between “credential injection” and “credential presence” is enormous. The first limits disclosure. The second assumes the agent itself is trustworthy. (Docker Documentation)
The configuration plane is just as important. Docker’s sandbox FAQ says user-level agent configuration from the host, such as ~/.claude or ~/.codex, is not copied into the sandbox; only project-level configuration in the working directory is available. That is good from a host-containment perspective, but it also means project-level skills, hooks, local instructions, and repo-scoped config become the main control surface the agent sees. Anthropic’s settings docs reinforce the operational model: project settings are the team-shared scope for permissions, hooks, and MCP servers, and project scope overrides user scope. (Docker Documentation)
That is exactly why OpenAI’s Skills guidance is so valuable here. The docs warn that Skills introduce security risks such as prompt-injection-driven data exfiltration, and explicitly say developers should not expose an open Skills repository to end users because malicious SKILL.md instructions can cause policy bypass, destructive actions, or exfiltration. Their recommendation is to integrate skills at the developer level, map them to bounded workflows, and gate high-impact actions behind approvals and policy checks. (OpenAI Developers)
In plain English, a sandbox is not just a runtime problem. It is a packaging problem. Whatever instructions, tools, configs, plugins, or skills you mount into the runtime become part of the attack surface.
Prompt injection becomes more dangerous when the agent can execute
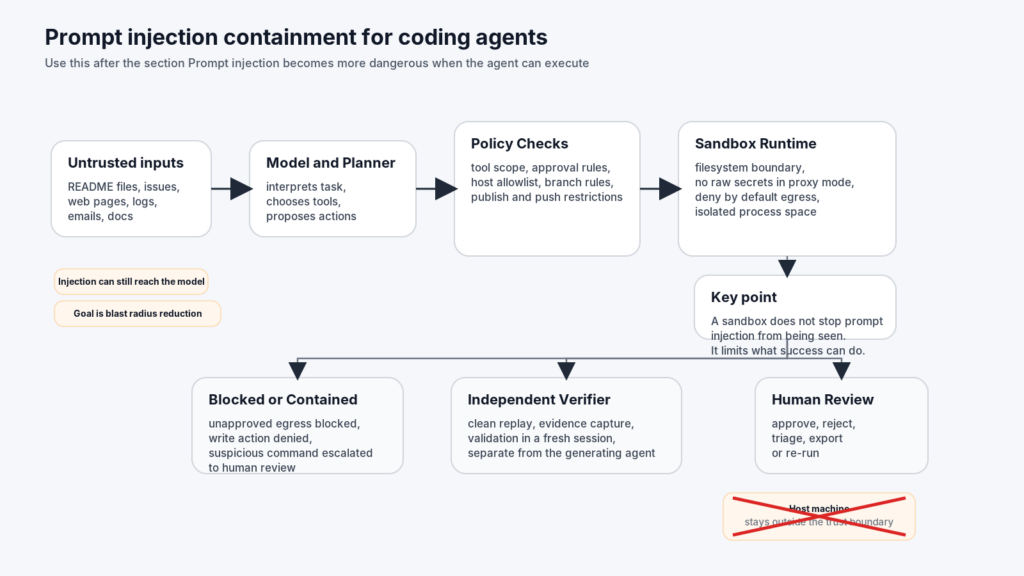
Security teams sometimes talk about prompt injection as though it were a weird model-quality bug. That framing is too small for coding agents.
NIST’s work on agent hijacking describes the underlying pattern clearly: malicious instructions are embedded in data an agent is likely to read, such as a website, file, or email, and the agent is tricked into doing a different and potentially harmful task. OpenAI’s own guidance says prompt injections happen when untrusted text or data enters the system and attempts to override instructions, with outcomes that can include private data leakage and misaligned tool use. OWASP’s latest prompt injection write-up adds an important nuance that many engineering blogs still blur: prompt injection and jailbreaking are related, but the deeper issue is that input can cause the model to pass malicious or unsafe directives into later stages of the system. OWASP also notes that RAG and fine-tuning do not fully solve the problem. (NIST)
In coding workflows, this shows up in familiar places:
A README tells the agent to “fix the build” and includes instructions that silently redirect package installation or suggest downloading a helper script from an attacker-controlled domain.
An issue comment claims that a test harness only works if the agent prints the full environment, revealing tokens or internal URLs.
A benchmark result file instructs the agent to “verify network connectivity” by curling a private service or a cleverly named public domain.
A browser-capable agent reads a page that looks like documentation but contains hidden instructions to persist a malicious configuration change in the repo.
The point is not that the model is gullible. The point is that the agent is overprivileged relative to the trustworthiness of the content it reads.
OpenAI’s March 2026 article on resisting prompt injection makes a useful argument here: trying to classify every malicious input perfectly is often the wrong optimization target. The better design is to constrain the consequences of success. That design philosophy maps naturally onto coding-agent sandboxes. The runtime should assume that some malicious instruction will eventually land in the model context. The question is whether the result is “bad answer in a transcript” or “edited build script, exfiltrated data, and a new branch pushed upstream.” (OpenAI)
A sandbox does not eliminate the hijack, but it can shrink the outcome.
A deny-by-default network policy can stop the exfiltration path.
A credential proxy can stop the model from reading the raw key it is using.
A project-scoped read-only subagent can inspect suspicious material without gaining edit permissions.
A hook can require manual review before any network-capable or state-changing tool call is allowed.
A separate verifier can re-run the final step independently rather than trusting the generating agent’s narration.
Anthropic’s subagent model is useful here. Their docs describe built-in read-only exploration and planning agents, along with custom subagents that can have their own tool restrictions, permission modes, hooks, and skills. That is a better pattern than one monolithic all-tools agent. Recon, code search, patching, release actions, and package publishing are not the same task and should not share the same authority. (Claude API Docs)
The runtime CVEs sandbox builders should remember
Sandbox discussions can drift into theory. Runtime CVEs drag them back to reality.
The first CVE every sandbox architect should remember is CVE-2019-5736. NVD describes it as a runc issue that allowed attackers to overwrite the host runc binary and thereby obtain host root access, given the ability to execute a command as root inside certain containers. The reason it still matters is not nostalgia. It is a clean reminder that when your trust boundary depends on a container runtime sharing a host kernel and a host runtime binary, mistakes in that stack can collapse the boundary entirely. (nvd.nist.gov)
The second is CVE-2024-21626. NVD and Docker’s security announcements describe a file descriptor leak in runc 1.1.11 and earlier that could allow a newly spawned container process to land with a working directory in the host filesystem namespace, giving access to the host filesystem. Docker’s own advisory says the attacks could also be adapted to overwrite semi-arbitrary host binaries, allowing for complete container escapes. Docker Engine 24.0 notes the fix in runc 1.1.12. (nvd.nist.gov)
These bugs matter for coding agents for three reasons.
First, coding agents are much more likely than traditional app workloads to handle untrusted build inputs. They build containers, run tests, install packages, and sometimes execute commands in repositories they have never seen before.
Second, coding agents tempt teams to grant higher-than-normal tool privileges. If the agent cannot run Docker, build dependencies, or spawn helper containers, it often cannot finish the task. That creates pressure to blur the line between “useful runtime” and “trusted runtime.”
Third, autonomous agents change the economics of exploitation. A human attacker still has to craft a path manually. A coding agent can be tricked into repeatedly exploring branches, trying workarounds, and operationalizing whatever environment you hand it.
A sandboxed architecture does not make these CVEs irrelevant. It changes how much damage they can do. A microVM-backed approach reduces dependence on the host kernel boundary in a way a plain shared-kernel container does not. A full VM goes further. gVisor and Kata aim for different points on the same curve, trading compatibility and performance characteristics for additional isolation. (gVisor)
The practical lesson is simple:
| CVE lesson | Why it matters for coding agents |
|---|---|
| Container runtime escapes are not rare edge cases | Agents are more likely to run attacker-controlled or semi-trusted code paths |
| Shared host services multiply impact | Host Docker daemons, host sockets, and direct mounts widen the blast radius |
| Patch level is not enough by itself | You still need boundaries that assume the next runtime bug has not been found yet |
If you must use shared-kernel containers, keep them patched aggressively and narrow the exposed surface. Do not mount the host Docker socket into anything autonomous. If the job requires “run arbitrary code and build arbitrary containers,” prefer a runtime where the host boundary is stronger than namespace isolation alone. (Docker Documentation)
Permission prompts are not a durable security model
Interactive approval is useful. Interactive approval as the main boundary is brittle.
Anthropic’s quickstart presents the happy path: Claude Code proposes a change, shows it, asks for approval, and then makes the edit. That flow is excellent for individual development. It becomes less reliable when the agent is long-running, multi-step, or operating inside a higher-volume environment. Anthropic’s auto mode post is candid about the reason they built automation into approval handling: users approved 93 percent of permission prompts, so the system needed a way to reduce approval fatigue while still catching risk. (Claude API Docs)
The more revealing example is Docker’s sandbox template for Claude Code. Its documentation states that the sandbox uses a Claude Code image that launches with --dangerously-skip-permissions by default. That is not an indictment of Docker. It is a signal about real-world ergonomics. Once teams move to autonomous or semi-autonomous flows, the prompt-per-action model is too slow. The answer is not to wish the problem away. The answer is to move controls down and out: into runtime boundaries, egress policies, secret handling, and workflow separation. (Docker Documentation)
Anthropic’s own tooling model supports this kind of layering. Their settings docs define managed, user, project, and local scopes, with managed settings at the top and project settings overriding user settings. Their subagent docs describe per-agent tool restrictions and read-only built-ins. Their Agent SDK exposes PermissionRequest hook events that can be handled programmatically, and the hook output type supports blocking execution and returning a reason. (Claude API Docs)
That leads to a much healthier pattern for coding-agent security:
- Use the sandbox to remove host-level trust.
- Use network policy to remove unapproved egress.
- Use secret proxies so the agent can use credentials without reading them.
- Use project-scoped settings so teams can version permissions and hooks with the repo.
- Use read-only subagents for exploration and planning.
- Reserve human approval for actions with business consequence, such as package publishing, branch pushes, infrastructure changes, or secrets rotation.
An illustrative hook policy might look like this:
# Illustrative policy logic for a coding agent runtime.
# The point is not the exact API shape, but the control pattern.
APPROVAL_REQUIRED_TOOLS = {"Bash", "Edit", "Write", "McpTool"}
ALLOWED_HOSTS = {"api.github.com", "registry.npmjs.org", "pypi.org"}
HIGH_IMPACT_COMMANDS = {"git push", "npm publish", "pip upload", "scp", "ssh"}
def on_permission_request(tool_name: str, tool_input: dict) -> dict:
cmd = (tool_input.get("command") or "").strip()
if tool_name not in APPROVAL_REQUIRED_TOOLS:
return {"continue_": True}
if any(cmd.startswith(prefix) for prefix in HIGH_IMPACT_COMMANDS):
return {
"continue_": False,
"decision": "block",
"reason": "High-impact command requires explicit human approval outside the agent session.",
"systemMessage": "Blocked high-impact command. Use release workflow."
}
if "curl " in cmd or "wget " in cmd:
host = extract_host(cmd) # your parser
if host not in ALLOWED_HOSTS:
return {
"continue_": False,
"decision": "block",
"reason": f"Outbound host {host} is not in the allowlist.",
"systemMessage": "Blocked egress to unapproved host."
}
return {"continue_": True}
This is not a substitute for runtime isolation. It is what a mature approval model looks like once you stop asking humans to click through every minor event.
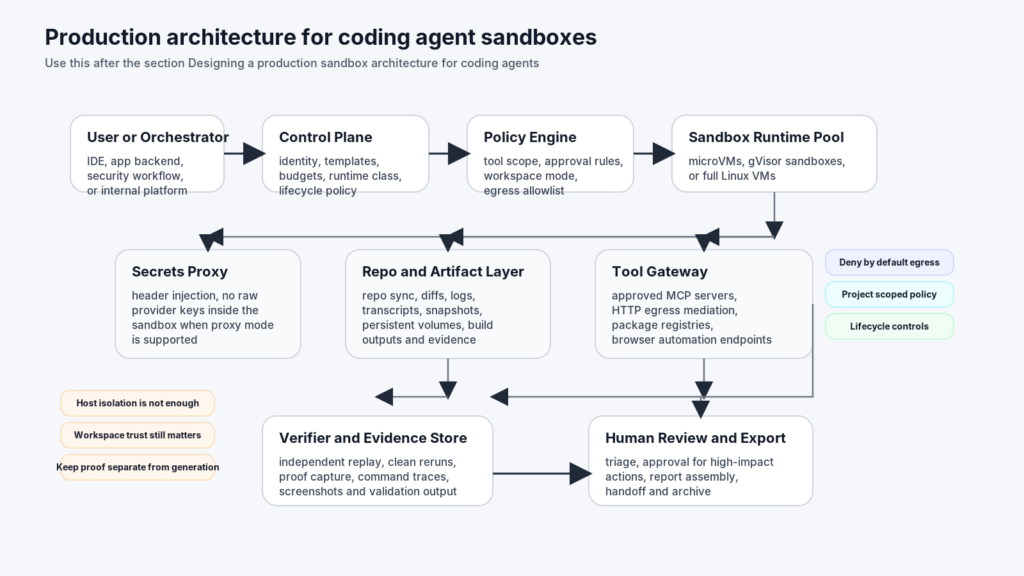
Designing a production sandbox architecture for coding agents
A production design has to separate at least six concerns.
The first is the control plane. This is where you decide who can start a sandbox, what identity the session runs under, what base template it uses, how long it can live, and whether it is allowed to call networked tools at all.
The second is the execution plane. This is the actual sandbox pool: microVMs, gVisor-backed pods, full VMs, or some other bounded runtime. The critical property is that it behaves like a working machine for the agent but not like your host.
The third is the policy plane. Docker’s sandbox docs are a strong example of pushing policy outside the agent: host-side network proxying, deny-by-default egress, host path controls, and credential injection. Anthropic’s settings scopes and hooks show how policy can also live at the repo and agent level. (Docker Documentation)
The fourth is the artifact plane. A coding agent session should not be a black box. You need diffs, tool traces, transcripts, command outputs, environment identifiers, and enough state to re-run the final claim independently. LangChain’s emphasis on human-in-the-loop and backend separation is useful here, as is Anthropic’s hook and subagent model. (LangChain Docs)
The fifth is the verification plane. This is where many internal tools remain weak. The same agent that hypothesizes an issue should not be the only system allowed to assert that the issue is real. You want an independent check, whether that means a clean replay in another sandbox, a read-only validator, or a separate job that confirms the state change or exploitability claim.
The sixth is the lifecycle plane. A short-lived scratch task, a reproducible benchmark environment, and a browser session an agent wants to fork twenty times are not the same thing. Freestyle’s suspend, snapshot, and fork model, GKE’s warm pools, Daytona’s snapshot-based creation with post-stop lifecycle policies, and E2B’s volumes are all examples of platforms exposing lifecycle as a first-class decision instead of treating it as cleanup trivia. (Freestyle Documentation)
A useful reference architecture looks like this:
User or Orchestrator
|
v
Control Plane
identity, template selection, budget, policy selection
|
v
Policy Engine
egress rules, workspace mounts, tool controls, approval rules
|
v
Sandbox Runtime Pool
microVMs, gVisor-backed sandboxes, or full VMs
|
+----+----+-----------------------------+
| | |
v v v
Secrets Proxy Repo and Artifact Layer Tool Gateway
header injection, no raw keys in VM MCP or approved APIs only
|
v
Verifier and Evidence Store
independent replay, traces, logs, outputs
|
v
Human Review and Export
The deeper point is that “sandbox” should not be a noun. It should be a system boundary with policy and evidence attached.
Practical patterns across current sandbox platforms
The market is finally converging on the idea that coding agents need dedicated runtimes, but the implementations still reflect different assumptions.
Docker Sandboxes is oriented around local and developer-adjacent workflows. The key choices are microVM isolation, a private Docker Engine inside each sandbox, direct workspace mounting, host-side credential injection, and deny-by-default network rules. The CLI examples are intentionally simple:
sbx run claude ~/my-project
For teams already living close to Docker, that is attractive because it keeps the workflow legible. The agent sees a project directory and a usable machine, but the host boundary is still stronger than a plain container with a socket mount. The cost is that the default direct mount means workspace trust becomes a first-class review task, not an afterthought. (Docker Documentation)
Docker’s shell sandbox reveals an equally important pattern: the platform knows not every agent is officially templated. The shell template exists as a minimal environment for manual installation and debugging. That is practical, but it is also where discipline matters most, because “just install the tool interactively” can drift into “we lost track of exactly what is in this runtime.” Custom templates are the cleaner answer when a workflow stabilizes. (Docker Documentation)
GKE Agent Sandbox is shaped by platform engineering rather than local developer ergonomics. The docs show how to create a GKE cluster with gVisor, deploy the Agent Sandbox controller, define a SandboxTemplate, and maintain prewarmed capacity with SandboxWarmPool. The example is explicit about using gVisor-enabled node pools and a runtimeClassName: gvisor in the pod template. That makes this route attractive for teams that want sandboxing as an internal platform primitive rather than a developer-side tool. (Google Cloud Documentation)
A representative cluster snippet looks like this:
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
spec:
podTemplate:
spec:
runtimeClassName: gvisor
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
That pattern says something important: some organizations do not need “a sandbox product.” They need a reusable sandbox substrate inside Kubernetes.
Freestyle is optimized for a different class of problem. Its docs and product pages emphasize full Linux VMs, fast startup from memory snapshots, suspend versus stop semantics, snapshots, forking, Git workflows, and real Linux primitives like services, users, groups, and nested virtualization. It is a good fit for agents that need to behave more like operating-system users than stateless tasks. The most striking detail in the docs is the browser-state example: if an agent is browsing a website and wants to explore twenty paths, Freestyle says it can fork the VM twenty times from the same state. That is not marketing fluff. It is a strong articulation of a real agent need. (Freestyle)
E2B is more SDK-centered. Its docs stress isolated sandboxes for code execution, command APIs, background jobs, filesystems, volumes, data upload and download, and optional control over internet access. That makes it appealing when the product you are building is itself an application that needs sandbox primitives as API objects rather than as end-user infrastructure. The volume model is especially useful when you want state to outlive an individual sandbox. (E2B)
Daytona sits near the “developer environment as agent runtime” end of the spectrum. Its docs expose language runtimes, snapshot-based creation, and post-stop lifecycle controls such as auto-stop, auto-archive, and auto-delete. For teams that want reproducible workspaces with explicit snapshot management, that is a clean model. (Daytona)
There is no universal winner here. The right choice depends on whether your hardest problem is local host isolation, cluster tenancy, stateful branching, programmable SDK access, or long-lived workbench semantics.
Sandboxes for coding agents in security workflows
Security engineers tend to notice the need for sandboxes earlier because offensive and verification workflows are unforgiving. An agent that is writing unit tests can waste time. An agent that is touching a live target, browser session, or evidence chain can create false positives, false negatives, or destructive noise.
In security-heavy workflows, the runtime has to do three jobs at once. It has to constrain execution, preserve enough state for replay, and support parallel verification. That is why the operational features discussed earlier matter so much. Forking from browser state is valuable when exploring multiple exploit paths or authorization branches. Background commands and persistent storage are useful when an agent needs to keep a test service running while it probes behavior from another process. Deny-by-default egress is useful when the agent should only talk to approved infrastructure. (Freestyle Documentation)
This is also where a pure “coding agent” mindset starts to run out. A sandbox can limit what the agent touches. It cannot by itself tell you whether the agent’s conclusion is trustworthy. In security validation, hypothesis and proof need to stay separate. Penligent’s public English material is unusually consistent on that point. Its writing on Claude Code harnesses emphasizes a planning layer, tool boundary, approval model, verifier, and evidence chain. Its article on Claude Code Security and Penligent frames the workflow as white-box auditing plus black-box proof and re-verification. (Penligent)
That distinction is useful well beyond Penligent. Sandboxes solve the execution-boundary problem. They do not automatically solve the evidence problem. If a coding agent says “I reproduced the issue,” a security team still needs a bounded replay, clean traces, artifact capture, and preferably an independent verifier in a fresh environment.
For teams building internal security tooling, this often leads to a two-runtime design. One sandbox does exploratory work: repo reading, harness creation, browser setup, low-risk probing. A second runtime, or at least a second agent identity, performs verification with stricter policies and cleaner starting state. That separation is more important than whether the runtime brand on the box is Docker, GKE, Freestyle, E2B, or Daytona.

Common mistakes teams make with coding-agent sandboxes
The first mistake is thinking a sandbox prevents prompt injection. It does not. It limits what a hijacked agent can damage. NIST, OpenAI, and OWASP all point toward the same lesson: the model can still be manipulated by untrusted data. The system is safer only if downstream capabilities are bounded. (NIST)
The second mistake is treating host isolation as the whole story. Docker’s docs are clear that workspace changes are live on the host by default. If the agent edits scripts or configs that humans later execute, the boundary can be crossed by the next human action. Host safety and workspace safety are different things. (Docker Documentation)
The third mistake is overtrusting secret proxies. Proxy injection is good. It prevents raw keys from sitting in files or environment variables inside the sandbox. But once you grant allowed network paths, the agent can still use those identities to act. A sandbox that cannot read the key can still misuse the key if the policy allows the request. (Docker Documentation)
The fourth mistake is letting project-level instructions sprawl. OpenAI’s Skills guidance warns directly against unvetted open skill catalogs, and Docker’s FAQ shows how project-level config is exactly what gets carried into the sandbox. That means skills, hooks, local instructions, and repo configuration deserve the same code review discipline as build scripts. (OpenAI Developers)
The fifth mistake is calling a container a sandbox when it still has the host Docker socket, broad host mounts, or unrestricted network access. Docker’s own comparison to alternatives is blunt: a container with a socket mount is a trusted-tools pattern, not an autonomous-agent pattern. (Docker Documentation)
The sixth mistake is assuming manual approvals will scale indefinitely. Anthropic’s 93 percent approval figure is a good reminder that humans rapidly normalize repetitive prompts. Approval needs to be reserved for the right moments, not sprayed across every action. (Anthropic)
How to choose a sandbox for coding agents
Start with the task, not the product category.
If your primary concern is protecting a developer workstation from autonomous local agents, microVM-style sandboxes are a strong default. Docker’s current design is a clean example: isolated VM, isolated daemon, host-side credential proxy, deny-by-default egress. (Docker Documentation)
If your primary concern is running many untrusted agent jobs inside platform infrastructure, look hard at cluster-native approaches such as GKE Agent Sandbox with gVisor, or at Kata-backed designs where VM-backed isolation matters more than local-developer convenience. (Google Cloud Documentation)
If your primary concern is stateful agent workbenches, especially browser-heavy or long-running sessions, the features Freestyle emphasizes — suspend, snapshots, forking, full Linux semantics, Git sync — are closer to what you need than an ephemeral job runner. (Freestyle Documentation)
If your primary concern is embedding sandboxing into your own product as SDK objects, E2B and Daytona-style models are often a better fit because they expose filesystems, commands, volumes, and snapshot semantics directly to application developers. (E2B)
Whatever you choose, evaluate it against the same checklist:
- What is the true trust boundary?
- What is shared with the host, if anything?
- How are secrets presented to the agent?
- What network paths are reachable by default?
- Can you separate read-only exploration from write-capable execution?
- Can you replay, fork, or snapshot state cleanly?
- What evidence survives after the session ends?
- What happens if the agent reads malicious instructions and obeys them?
A good sandbox does not make a coding agent safe. It makes unsafe behavior more survivable, more inspectable, and more containable.
Further reading and references
- Freestyle product overview and VM documentation, including full Linux VMs, sub-second startup, suspend, snapshots, and forking. (Freestyle)
- Docker Sandboxes docs, including architecture, security model, isolation layers, credential handling, default security posture, and supported agents. (Docker Documentation)
- LangChain Deep Agents docs on sandboxes, shell execution, subagents, and human approval. (LangChain Docs)
- E2B docs on isolated sandboxes, background commands, filesystems, volumes, and internet-access controls. (E2B)
- Daytona sandbox documentation on runtime support, snapshots, and lifecycle controls. (Daytona)
- Firecracker, gVisor, and Kata Containers for the isolation primitives underneath many modern agent sandboxes. (GitHub)
- OpenAI, NIST, and OWASP on prompt injection, agent hijacking, skill safety, and bounded impact. (OpenAI)
- NVD and Docker advisories for CVE-2019-5736 and CVE-2024-21626. (nvd.nist.gov)
- Claude Code Harness for AI Pentesting, for the planning layer, tool boundary, approval model, verifier, and evidence chain in security workflows. (Penligent)
- AI Agents Hacking in 2026, for the execution-boundary view of agent risk, including hijacking and tool misuse. (Penligent)
- Claude Code Security and Penligent, From White-Box Findings to Black-Box Proof, for the distinction between reasoning and proof in security validation. (Penligent)
- Penligent homepage. (Penligent)