קל מאוד לטעות בהבנת "קוד קלוד" כאשר מתייחסים אליו כאל תיבת פקודות משופרת עם גישה לשפת פקודה. החומרים הציבוריים של Anthropic עצמה מתארים משהו ספציפי יותר. "רצועה" (harness), או "פיגום" (scaffold), היא המערכת שמאפשרת למודל לפעול כסוכן באמצעות עיבוד קלט, תיאום קריאות לכלים, ניהול הקשר והחזרת תוצאות. Anthropic מבהירה במפורש שכאשר מעריכים סוכן, מעריכים את ה-harness ואת המודל יחד, ולא את המודל לבדו. ה-Agent SDK שלה בנוי באותו אופן: Claude Code כספרייה ניתנת לתכנות עם אותם כלים, לולאת סוכן וניהול הקשר המניעים את Claude Code עצמו. (אנתרופי)
הבחנה זו חשובה יותר בתחום אבטחת המידע ההתקפית מאשר כמעט בכל תחום יישום אחר. בדיקות חדירה אינן בעיה של שיחה. הן מהוות בו-זמנית בעיה של תכנון, בעיה של ניהול מצבים, בעיה של אימות, בעיה של דיווח ובעיה של בטיחות. תקן NIST SP 800-115 מגדיר בדיקות טכניות כתהליך הכולל תכנון, ביצוע בדיקות, ניתוח ממצאים ופיתוח אסטרטגיות למזעור סיכונים. מדריך בדיקות אבטחת האינטרנט של OWASP עדיין מתייחס לבדיקות אינטרנט כאל תחום רחב המכסה איסוף מידע, אימות, הרשאה, ניהול הפעלה, אימות קלט, לוגיקה עסקית ובדיקות API. מדריך בדיקות ה-AI של OWASP, שפורסם בסוף 2025, מרחיב את תפיסה זו לבדיקות אמינות עבור מערכות AI. (מרכז המחקר למדעי המחשב של ה-NIST)
המאמר על PentestGPT העלה את אותה הטענה מההיבט המחקרי. מחבריו גילו כי מודלים לשוניים גדולים מצטיינים לעתים קרובות במשימות משנה כגון שימוש בכלי אבטחה, פירוש תוצאות והצעת פעולות הבאות, אך מתקשים לשמור על הקשר הכולל של הבדיקה לאורך זמן. התשובה שלהם לא הייתה פקודה ארוכה יותר, אלא ארכיטקטורה משולשת הכוללת מודולים נפרדים להסקת מסקנות, ליצירת תוכן ולניתוח תחבירי, שתוכננה במיוחד כדי לצמצם את אובדן ההקשר. (arXiv)
זה המקום שבו רעיון ה-harness של "קוד קלוד" (Claude Code) הופך לשימושי בבדיקות חדירה של בינה מלאכותית. הלקח החשוב ביותר אינו שסוכן תכנות יכול להריץ פקודות. מערכות רבות מסוגלות להריץ פקודות. הלקח הוא שהתנהגות רצינית של הסוכן נובעת מהמערכת הסובבת: שכבת התכנון, גבולות הכלי, מודל האישור, אובייקטי המסירה, המאמת ושרשרת הראיות. עבודת ה-harness ארוכת השנים של Anthropic עצמה מבהירה זאת. פוסטים הנדסיים פומביים שלהם מתארים סטיית הקשר, "חרדת הקשר", העברות מובנות, תפקידי מתכנן-יוצר-מעריך, חוזי ספרינט, והערך של מעריך נפרד שהוא ספקן יותר מהיוצר. (אנתרופי)
אם מיישמים את זה בתחום בדיקות החדירה, השאלה משתנה. היא כבר לא "האם Claude Code יכול לבצע בדיקות חדירה?", אלא "איך ייראה מערך בדיקות חדירה אם ישאיל את הרעיונות הנכונים מ-Claude Code ויתאים אותם לעבודה בתחום האבטחה הממוקדת ביעד, שבה הראיות עומדות בראש סדר העדיפויות?" זו הארכיטקטורה שכדאי לבנות.
מהנחיה ועד תמיכה
הדרך המהירה להסביר את ההבדל היא זו: פקודה מבקשת ביצוע פעולה, בעוד שמנגנון בקרה מפקח על הפעולה.
בהגדרת בדיקת חדירה של בינה מלאכותית (AI) נאיבית, המודל מקבל יעד, אולי כמה כלים, והוראה כללית כמו "מצא נקודות תורפה". לפעמים זה עובד במשימות פשוטות. בפרויקט אמיתי, זה מביא בדרך כלל לאחת מארבע תוצאות שליליות. הראשונה היא "בזבוז כלים", שבה המודל ממשיך לבצע סיור שטחי מבלי להתמקד בהשערה קונקרטית. השנייה היא "מצב שברירי", שבו הוא שוכח מה היה חשוב לפני שלוש קריאות לכלי. השלישי הוא "אינפלציה נרטיבית", שבה "זה נראה פגיע" נרשם כמו ממצא מאושר. הרביעי הוא "סטייה לא בטוחה", שבה המערכת מרחיבה את ההיקף או מבצעת פעולות שמעולם לא אושרו במפורש. ממצאי הבנצ'מרק של PentestGPT בנוגע לאובדן הקשר והכתבה הציבורית של Anthropic על סוכנים הפועלים לאורך זמן מצביעים על אותו מצב כשל מרכזי: הבעיה היא לא רק איכות ההנמקה, אלא האם המערכת סביב המודל שומרת על הכיוון והשליטה. (arXiv)
ההנחיות של Anthropic עצמה בנוגע לנהלים מומלצים הן כאן ישירות להפליא. נכתב בהן שהדבר בעל ההשפעה הגדולה ביותר שניתן לעשות הוא לספק ל-Claude דרך לאמת את עבודתו. ללא קריטריונים ברורים להצלחה, אתה הופך להיות מעגל המשוב היחיד. בקוד, זה מתבטא בבדיקות, צילומי מסך או תוצאות צפויות. בבדיקות חדירה, המשמעות חזקה עוד יותר: הפעלות חדשות, בקשות שניתן לשחזר, שינויי תפקידים, אימות מצב הדפדפן ולכידת תוצרים. סוכן בדיקות חדירה שאינו יכול לאמת את טענותיו אינו בודק אוטונומי. הוא מחולל השערות עם רמת ביטחון מסוכנת. (קלוד)
קלאוד קוד מציג גם תבנית תכנון שמפתחי אבטחה צריכים לאמץ כמעט כלשונה: יש להשתמש בתכנון בטוח ומכוון לקריאה בשלב מוקדם, ורק לאחר מכן לעבור לשלב הבא כאשר יש סיבה מוגדרת לכך. "מצב תכנון" (Plan Mode) במסמכים הציבוריים נועד במפורש לניתוח לקריאה בלבד ולאיסוף דרישות לפני ביצוע שינויים כלשהם. בתרגום למונחי בדיקת חדירות, זה הופך לתכנון שמבוסס על סיור מקדים: סריקה, מיפוי, קיבוץ, יצירת קורלציות והחלטה מה ראוי לבדיקה אקטיבית לפני שניגשים לכל פעולה שמשנה את המצב. (תיעוד ה-API של Claude)
אותו היגיון חל גם על סוכנים משנה. במסמכי Anthropic מתוארים סוכני משנה מותאמים אישית כעוזרים מתמחים בעלי הנחיות משלהם, גישה לכלים משלהם וחלונות הקשר משלהם. זה לא רק עניין של נוחות בתכנות. זהו מודל מחשבתי טוב לבדיקות חדירה של בינה מלאכותית, מכיוון שפעולות סיור, הבנת זרימת העסק, אימות פרצות ודיווח אינן אותה משימה, ולכן אין להן לחלוק הרשאות זהות או הקשר זהה. (תיעוד ה-API של Claude)
לפיכך, ה-harness שלמטה אינו העתק של Claude Code. זהו תרגום.
מה הופכים פרימיטיבים ציבוריים של "קוד קלוד" בבדיקות חדירה בתחום הבינה המלאכותית
המיפוי הוא פשוט ברגע שצורת המשימה ברורה.
| פרימיטיב של קוד קלוד | מה זה אומר בקוד קלוד | תרגום של בדיקות חדירה מבוססות בינה מלאכותית |
|---|---|---|
| מצב תכנון | ניתוח לקריאה בלבד לפני ביצוע שינויים | סיור לקריאה בלבד, מיפוי נכסים ותכנון מטרות |
| סוכנים משנה | עוזרים מומחים בעלי תפקידים מוגדרים וגישה לכלים | עובד סיור, מתכנן זרימה, מבצע, בודק, כותב דוחות |
| הוקות PreToolUse ו-PermissionRequest | בקרות מדיניות לפני הפעלת הכלי | שומר סף בזמן ריצה עבור היקף, קטגוריית סיכון, תעריף ואישור |
| סביבת בדיקה מבודדת | בידוד מערכת הקבצים והרשת למען אוטונומיה בטוחה יותר | מנהל בדיקות מובנה, רשימות אישור של דומיינים, בקרות יציאה, דפדפן מבודד ושרת פרוקסי |
| דחיסת הקשר והעברת שליטה | רציפות משימות ארוכות למרות מגבלות הקשר | זיכרון קמפיין, סיכומי הפעלה, אינטראקציות הניתנות להמשך |
| תן לקלוד דרך לאמת את עבודתו | בדיקות ותוצאות צפויות משפרות את האמינות | השמעה חוזרת, השוואת שינויים, אישור רב-מפגשי, ראיות שניתן לשחזר |
| מצב אוטומטי: דחייה והמשך | אם הדרך חסומה, סובו לאחור ונסו מסלול בטוח יותר | אם בדיקה אקטיבית נדחית, יש לעבור לאימות פסיבי או לאימות בעל סיכון נמוך יותר |
זהו סיכום, אך כל שורה מבוססת על החומר שפרסמה חברת Anthropic. במסמכים ובפוסטים ההנדסיים שלהם מתואר "Plan Mode" כניתוח לקריאה בלבד, "subagents" כהקשרים ייעודיים, "hooks" כנקודות בקרה מסוג "הרשאה-סירוב-בקשה-דחייה", "sandboxing" כבידוד של מערכת הקבצים והרשת, "long-running harnesses" כמערכות רב-סוכניות מובנות הכוללות העברת שליטה, ו"אימות" כשיפור בעל ההשפעה הגדולה ביותר על אמינות הסוכנים. (תיעוד ה-API של Claude)
בהמשך המאמר נפרט את גרסת בדיקת הפריצה של הטבלה הזו.
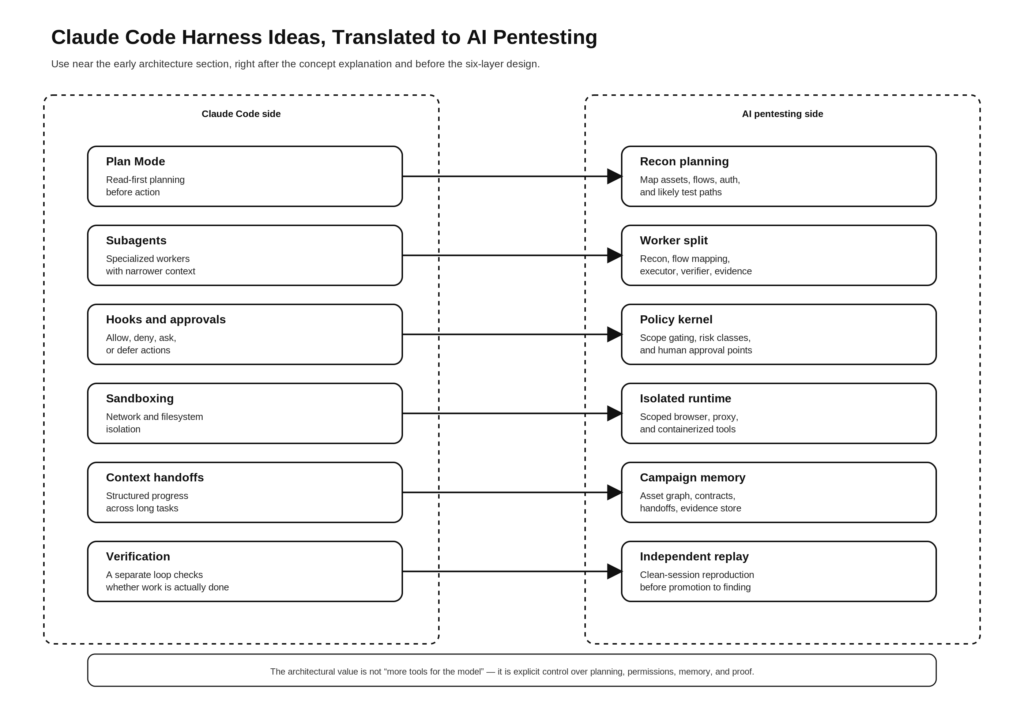
מדוע בדיקות חדירה מבוססות בינה מלאכותית דורשות יותר מסתם מודל
בדיקת חדירה היא אחת המשימות הקשות ביותר עבור סוכן בודד הפועל באופן חופשי. היעד משתנה תחת התצפית. מצב האימות חשוב. הלוגיקה העסקית חשובה. הנחות הסביבה חשובות. "הצלחה" עלולה להיות כוזבת אם היא מתרחשת רק בהפעלה מזוהמת, רק כאשר קובצי Cookie של מנהל מערכת כבר קיימים, רק כנגד רכיב CDN, או רק משום שהסוכן פירש תגובה רועשת כהוכחה.
קבוצת העבודה WSTG של OWASP ממשיכה להיות שימושית בהקשר זה, שכן היא מאלצת את הבודק לחשוב במונחים של קטגוריות תקיפה רחבות ולא במונחים של תוצאות סריקה בודדות. מדריך הבדיקות ל-AI מרחיב את הגישה הזו למערכות AI על ידי התייחסות להערכה כאל בדיקת אמינות מעשית ומובנית, ולא כאל בדיקת "תחושה כללית". PentestGPT פועל באותו הכיוון מזווית אחרת: התקדמות אמיתית נובעת מפירוק המשימה לשלביה ושמירה על ייצוג של מצב המערכת. (OWASP)
העבודה הממושכת של Anthropic בתחום ה-Harness מספקת לקח משלים. ארכיטקטורת המתכנן-המחולל-המעריך שיפרה את התוצאות מכיוון שהסוכנים לא ביצעו כולם את אותה הפעולה. המתכנן הרחיב הנחיות קצרות למפרטים מלאים יותר. היוצר בנה באופן הדרגתי. המעריך השתמש באינטראקציה ישירה עם האפליקציה הפועלת ואכף ספים נוקשים. לפני כל ספרינט, היוצר והמעריך ניהלו משא ומתן על חוזה לגבי המשמעות של "מוכן". דפוס זה מתאים באופן כמעט מביך לבדיקות חדירה. (אנתרופי)
במונחי בדיקות חדירה, התרגום ברור. המתכנן הופך למאגד השערות. היוצר הופך לעובד ביצוע. המעריך הופך למאמת עצמאי. חוזה הספרינט הופך לחוזה תקיפה. מערכת הדחיסה וההעברה הופכת לזיכרון קמפיין. התוצאה אינה "בדיקות חדירה סוכניות יותר" במובן המופשט. זוהי מערכת המסוגלת לעבור מסימן להוכחה מבלי להמיר בשקט השערות לממצאים.
ששת השכבות של מערך בדיקות חדירה מבוסס בינה מלאכותית
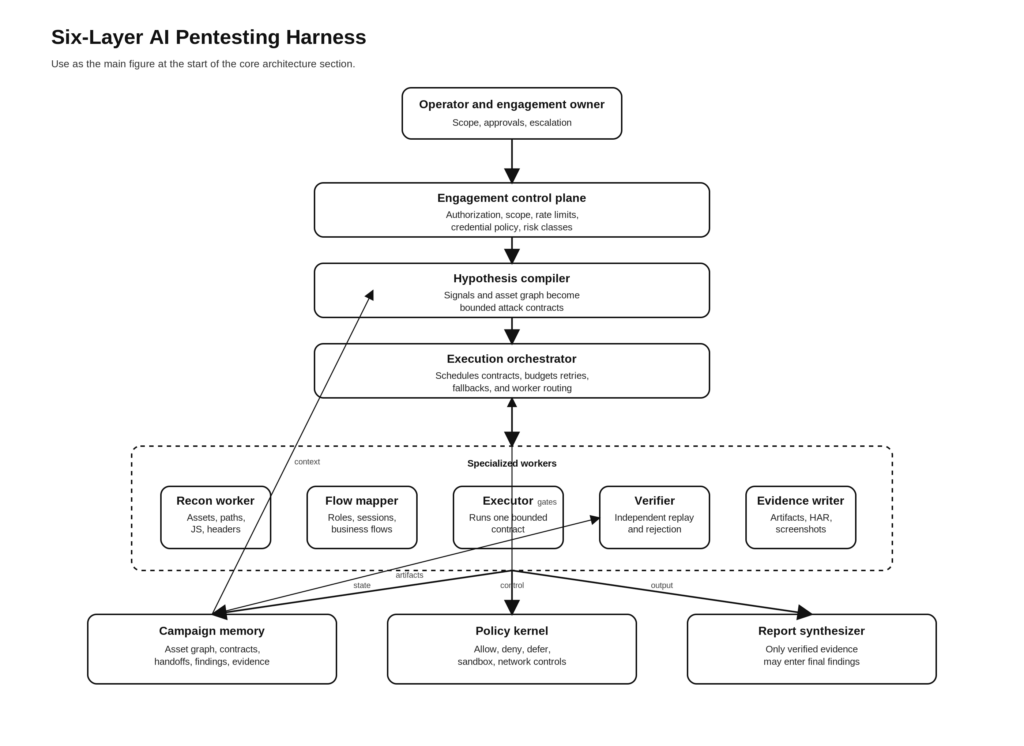
הארכיטקטורה המובאת להלן היא התכנון שהייתי בונה אילו המטרה הייתה לשאוב את הרעיונות החזקים ביותר מ-Claude Code ולהתאימם לבדיקות חדירה של בינה מלאכותית (AI) מאושרות, המתבססות על ראיות.
שכבה ראשונה, מישור בקרת המעורבות
ההכנה מתחילה עוד לפני השימוש בכלי הראשון. היא מתחילה כבר בשלב ההתקשרות עצמה.
המסמך NIST SP 800-115 מדגיש את התכנון כחלק מהבדיקות הטכניות, ולא כפעילות בירוקרטית הנעשית מחוץ למערכת. מסגרת ה-trustworthy-agents של Anthropic אומרת בעיקרון את אותו הדבר במילים אחרות: יש להשאיר את השליטה בידי בני האדם, במיוחד לפני פעולות בעלות סיכון גבוה, ולהתייחס לאוטונומיה כאל דבר שחייב להיות מוגבל. Claude Code מתואר כקוד לקריאה בלבד כברירת מחדל, וככזה שדורש אישור לצורך שינוי מערכות. לצורך בדיקות חדירה, אותה לוגיקה צריכה להיות מקודדת במניפסט מעורבות הניתן לקריאה על ידי מכונה, אשר זמן הריצה צורך בכל סיבוב. (מרכז המחקר למדעי המחשב של ה-NIST)
מישור בקרה נאות לפעילות כוללת היקף, חלונות אישור, קטגוריות בדיקה, פעולות אסורות, תקציבי תעבורה, תוויות יעד, הגבלות על אישורים, הגבלות דפדפן, ניתוב פרוקסי וכללי שמירת ראיות. כמו כן, נדרשת סיווג הפעולות לפי רמת הסיכון. קריאה פסיבית ואיסוף מטא-נתונים מהווים קטגוריה אחת. ספירה אקטיבית בעלת השפעה נמוכה היא קטגוריה אחרת. פעולות המשנות את המצב, שימוש בתעודות, העלאת קבצים או כל אימות הדומה לניצול פרצות אבטחה צריכים להיות מאחורי שערים נפרדים. מישור הבקרה הוא המקום שבו "בדיקת חדירה מורשית" מפסיקה להיות משפט בשורת הפקודה והופכת למדיניות בזמן ריצה.
קובץ manifest מינימלי עשוי להיראות כך:
פעילות: id: acme-web-2026-q2 authorized_by: security-team window_start: 2026-04-10T09:00:00Z window_end: 2026-04-17T23:00:00Z scope: domains:
- app.example.com - api.example.com נתיבים_שלא_כלולים: - /payments/live/* - /admin/billing/* זהויות_מותרות: - אנונימי - משתמש_בעל_הרשאות_מוגבלות יעדים_אסורים: - thirdparty.example.net
- *.internal.example.com runtime: max_rps: 2 browser_allowed: true upload_tests_allowed: false credential_rotation_required: true network_allowlist: - app.example.com - api.example.com
- auth.example.com מדיניות_סיכון: סיור_פסיבי: אוטומטי אימות_בעל_השפעה_נמוכה: אוטומטי פעולות_המשנות_מצב: אישור_אנושי ביצוע_דמוי_ניצול: אסור קריאות_חזרה_חיצוניות: אסור דיווח: לכידת_האר: נכון לכידת_צילומי_מסך: נכון עריכת_סודות: נכון
הדוגמה הזו פשוטה, אך ההיבט הארכיטקטוני רחב יותר. סוכן בדיקת חדירות לא צריך לעולם להסיק את היקף המשימה מהטקסט באנגלית בלבד. יש לפרק את מישור הבקרה להחלטות קונקרטיות בזמן ריצה. מודל ה-hooks של Anthropic מהווה השראה מועילה בהקשר זה, שכן הוא מעגן את נקודות ההחלטה לפני הפעלת הכלי, בעוד שמסגרת הבטיחות שלהם מתעקשת כי בני האדם ישמרו על השליטה לפני ביצוע פעולות בעלות סיכון גבוה. (תיעוד ה-API של Claude)
שכבה שנייה: מהדר השערות וחוזי ספרינט
השכבה הבאה מתרגמת את התצפיות למשימות מוגדרות.
מערכת הניהול של קלוד קוד, שהייתה בשימוש במשך שנים רבות, השתמשה במתכנן כדי להרחיב הנחיות קצרות למפרטי מוצר מפורטים יותר, ולאחר מכן השתמשה במשא ומתן בין הגנרטור למבקר כדי לקבוע מה נחשב לספרינט שהושלם. בתחום בדיקות החדירה, המקבילה לכך אינה תוכנית תכונות. מדובר בהשערת תקיפה הכוללת תנאי בדיקה מפורשים. (אנתרופי)
לכך יש חשיבות מכיוון שבדיקות חדירה אינן רק הפעלת כלים. הן מהוות ניהול השערות. בודק מבחין בהתנהגות, מגבש תיאוריה, שואל מה צריך להיות נכון כדי שהתיאוריה תהיה רלוונטית, ואז מתכנן בדיקה. לממשק הבדיקה יש להבהיר זאת במפורש. במקום להורות למודל "בדוק אימות", על המערכת ליצור חוזה בסגנון: "נראה כי יעד זה מקבל מזהי אובייקטים הנשלטים על ידי המשתמש בשלושה נקודות קצה. בדוק אם ההרשאה נאכפת בצד השרת במעברים בין תפקידים, תוך שימוש רק באישורים בעלי הרשאות נמוכות, מבלי לשנות רשומות מוגנות." זו עבודה שהמודל יכול לבצע. "מצא משהו מעניין" – לא.
חוזה התקפה מעשי כולל לפחות את השדות הבאים:
{ "contract_id": "idor-orders-001", "target": "", "goal": "לבדוק אם אכיפת ההרשאות ברמת האובייקט מיושמת בכל תפקידי המשתמשים",
"preconditions": [ "שני חשבונות בעלי הרשאות נמוכות עם גישה לקבוצות הזמנות שונות", "הפעלה נקייה עבור כל השמעה חוזרת" ], "allowed_actions": [ "בקשות GET", "ניווט בדפדפן", "איפוס הפעלה", "השוואת תגובות" ],
"פעולות אסורות": [ "שינוי רשומות", "ספירה המונית", "קריאות חוזרות חיצוניות" ], "סימני הצלחה": [ "גישה חוצת-חשבונות לנתוני הזמנות מוגנים", "שחזור יציב בשתי הפעלות נקיות" ],
"failure_signals": [ "סירוב אישור עקבי", "התנהגות המופיעה רק במצב הפעלה מזוהם" ], "required_evidence": [ "צמד בקשה ותגובה", "מיפוי תפקידים", "תמלול השמעה חוזרת",
"צילום מסך אם נראה בדפדפן" ], "risk_class": "בינוני", "budget": { "max_requests": 20, "max_duration_seconds": 600 }, "exit_condition": "מאומת או נדחה עם נימוקים" }
החוזה משיג שתי מטרות בו-זמנית. הוא מצמצם את מרחב החיפוש ומציב רף ראייתי גבוה יותר. בתיעוד הציבורי של Anthropic מצוין כי היוצר והמעריך סיכמו על חוזה "ספרינט" לפני תחילת העבודה, דווקא משום שהמעריך נזקק להגדרה ניתנת לבדיקה של המושג "הושלם". משמעת זו חשובה עוד יותר בתחום האבטחה, שבו קל באופן מסוכן לזייף את המושג "הושלם". (אנתרופי)
שכבה שלישית: עובדי ביצוע מיוחדים
סוכנים משנה הם אחד המושגים הניתנים ביותר ליישום במערך ה-Claude Code. חברת Anthropic מתארת אותם כעוזרים ייעודיים לתהליכי עבודה ספציפיים ולניהול הקשר משופר. הדבר אמור להישמע נכון מיד לכל מי שעסק בבדיקות חדירה אמיתיות. איסוף מודיעין, מיפוי תהליכי אימות, אימות פרצות וכתיבת דוחות הם משימות שונות. אין להן לחלוק את אותן הנחיות, כלים או הרשאות. (תיעוד ה-API של Claude)
מערכת בדיקות חדירה בוגרת צריכה לכלול לפחות חמש תפקידי ביצוע נפרדים.
הראשון הוא עובד סיור. תפקידו הוא לאתר ולנרמל ממשקי ממשק משתמש: מארחים, נתיבים, נקודות קצה, פרמטרים, מסלולי JavaScript, וריאציות כניסה, כותרות, מאגרי אובייקטים, ממשקי ניהול ותלות בצד שלישי. עליו להשתמש רבות בכלים, אך להיות בעל הרשאות מוגבלות. אין לאפשר לו "לאמת" ממצאים במובן של דיווח.
השני הוא "ממפה זרימות". עובד זה דומה יותר לאנליסט המתמחה במודלים של איומים מאשר לסורק. הוא הופך רשימות של נקודות קצה להתנהגויות. אילו זהויות קיימות? היכן מתרחשים מעברים? אילו פעולות הן מצביות? אילו סוגי אובייקטים מופיעים בתעבורת הדפדפן? אילו שדות נסתרים משפיעים על החלטות זרימת העבודה? התוצאה אינה זיהוי של פגיעות אבטחה, אלא גרף מובנה של התנהגות עסקית.
השלישי הוא מבצע ההיפותזות. זהו העובד שמבצע בפועל בדיקות פעילות מוגבלות על בסיס חוזה. עליו לקבל רק את הכלים וההרשאות הנדרשים על פי אותו חוזה. לא יותר מזה. התיעוד הציבורי של Anthropic בנושא סוכנים-משנה, הרשאות ו-hooks תומך בתוקף בסגנון זה של האצלת סמכויות מוגבלת: יש להשתמש בהקשרים ייעודיים ולהגביל את הגישה לכלים למה שכל יחידה באמת זקוקה לו. (תיעוד ה-API של Claude)
הרביעי הוא בודק. עובד זה לא יכול להיות אותו גורם שביצע את הבדיקה הראשונית. עבודתה ארוכת השנים של Anthropic בתחום ה-harness מועילה במיוחד בהקשר זה, שכן היא טוענת כי הערכה עצמית היא חלשה וכי קל יותר לכוון בודק נפרד לגישה ספקנית. בכל הנוגע לבדיקות חדירה, עיקרון זה אינו מהווה אופטימיזציה. זוהי דרישת תוקף. (אנתרופי)
החמישי הוא כותב הראיות. תפקידו הוא להמיר את תיעוד הריצה הגולמי לממצאים שניתן לשחזר על ידי מהנדס אחר. הכוונה היא לזוגי בקשה-תגובה, קטעי HAR, צילומי מסך, הערות על הסביבה, הקצאת תפקידים, מקרים שליליים והערות על ניקוי. אם מערך הבדיקות שלכם משלב את ה-worker הזה בתוך ה-executor, לכידת הראיות נוטה להיות סלקטיבית ומבולגנת.
ניתן להוסיף תפקידים נוספים בהמשך, אך חמשת התפקידים הללו מספיקים כדי ליצור הפרדה נאותה בין תחומי האחריות.
שכבה 4: לולאות של בודק עצמאי
זוהי השכבה הקובעת אם המערכת היא מערך לבדיקות חדירה או מכונה ליצירת סיפורים.
בדף "שיטות עבודה מומלצות" של Anthropic נכתב כי קריטריוני אימות ברורים הם השיפור בעל ההשפעה הגדולה ביותר שניתן לבצע. צוות הבדיקה הוותיק שלהם התייחס לכך ברצינות רבה, והעניק למבקר גישה ל-Playwright וקבע ספים נוקשים. המבקר היה רשאי לפסול ספרינט אם לא עמד באף אחד מהקריטריונים המרכזיים. בתחום האבטחה, המקבילה לכך קלה לתיאור וקשה לזיוף: ממצא אינו נחשב שלם עד שבודק עצמאי מצליח לשחזר את ההתנהגות הרלוונטית בתנאים מבוקרים. (קלוד)
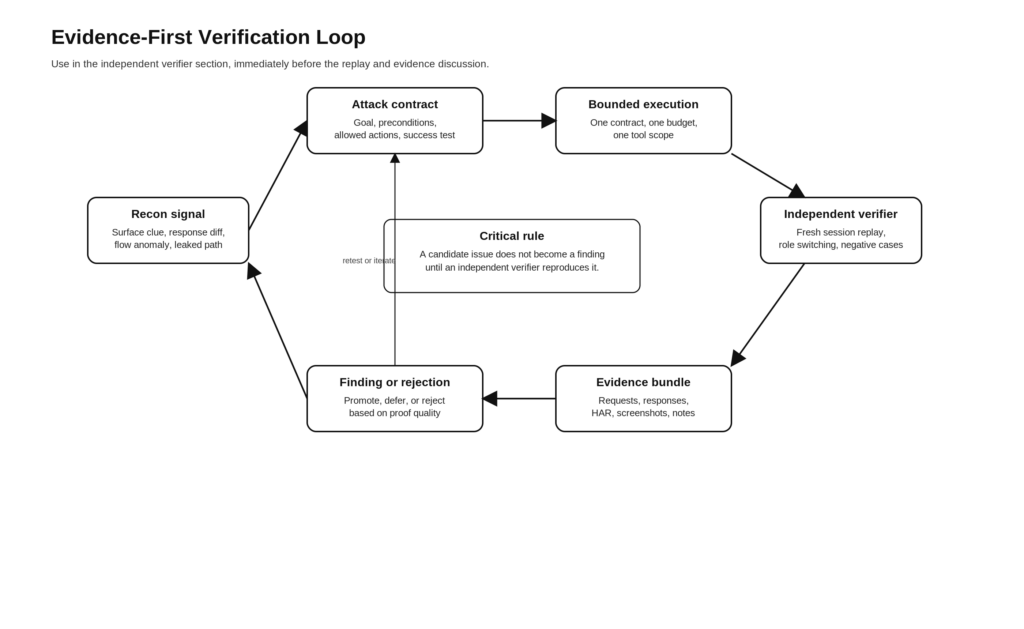
במסגרת בדיקות אתרים ו-API, בודק עצמאי נדרש בדרך כלל לבצע שילוב של הפעולות הבאות:
- אפס את ההפעלה והפעל אותה מחדש ממצב נקי.
- החליפו תפקידים או זהויות והשוו את ההתנהגות.
- ודא שהתוצאה אינה נובעת ממצב לקוח שמור במטמון או מקובצי Cookie פגומים.
- ודא שהתוצאה אינה נובעת מבעיה זמנית במעלה הזרם, מתופעת לוואי של ה-proxy או מחריגה ב-WAF.
- יש לתעד מקרים שליליים כדי שהדו"ח יוכל להסביר מה לא מהווה את הבעיה.
- לאסוף ראיות מספיקות כדי שאדם יוכל לשחזר את האירועים מבלי להסתמך על תיאורו של המודל.
מבנה קטן של השמעה חוזרת עשוי להיראות כך:
from dataclasses import dataclass from typing import List, Dict @dataclass class ReplayCase: name: str session_profile: str request_spec: Dict expected_signal: str @dataclass class VerificationResult: case_name: str observed_signal: str matched: bool artifacts: List[str] notes: str def run_verification(cases: List[ReplayCase], runner) -> List[VerificationResult]: results = [] for case in cases: runner.reset_session(case.session_profile) response = runner.send(case.request_spec) observed = runner.classify_signal(response)
artifacts = [] artifacts.append(runner.save_request_response(case.name, response)) if runner.browser_visible(response): artifacts.append(runner.save_screenshot(case.name))
results.append( VerificationResult( case_name=case.name, observed_signal=observed, matched=(observed == case.expected_signal), artifacts=artifacts, notes=runner.explain_difference(case.expected_signal, observed) ) ) return results
הקוד כתוב בכוונה בשפה פשוטה. הנקודה החשובה היא ההיבט הפרוצדורלי. האימות הוא שלב נפרד, ולא תוספת של הרגע האחרון. גם הכתיבה הפומבית של Anthropic עצמה בנושא סוכנים אמינים מחזקת את היבט השליטה הזה: סוכנים הם בעלי ערך מכיוון שהם מסוגלים לפעול, אך על בני האדם להישאר בשליטה לפני קבלת החלטות או ביצוע פעולות בעלות חשיבות רבה. מערכת בדיקת חדירות צריכה להתייחס לשדרוג מ"בעיה פוטנציאלית" ל"ממצא שיש לדווח עליו" כאחד מאותם מעברים בעלי חשיבות רבה. (אנתרופי)
זהו גם הנקודה שבה קל יותר להצדיק פלטפורמה התקפית המובנית בתוך זרימת העבודה, מאשר ערימה של כלים המחוברים זה לזה באופן אד-הוק. החומרים הציבוריים של Penligent חוזרים שוב ושוב לאותו עיקרון: איתות בלבד אינו מספיק, וזרימת עבודה יעילה היא כזו שהופכת ממצאים להשפעה מאומתת, משמרת את שרשרת ההוכחות, ומאגדת את התוצאה לדוח הניתן לעריכה. דף הבית שלה מדגיש נעילת היקף, פעולות הניתנות להתאמה אישית, ביצוע מונחה מהאות ועד ההוכחה, ודיווח, בעוד שפרסומים טכניים אחרונים מדגישים בדיקות אדפטיביות, מצב משומר, וממצאים מאומתים במקום השערות מנוסחות. בין אם צוות משתמש בפלטפורמה הספציפית הזו ובין אם לא, עקרון הפעולה נכון לחלוטין: הדוח צריך להיות סוף שרשרת הראיות, ולא תחליף לה. (Penligent)
השכבה החמישית, זיכרון קבוע והעברות
אחד מנקודות החוזק הבלתי מוכרות של עבודת ה-harness ארוכת השנים של Anthropic הוא שהיא מתייחסת למצב (state) כאל בעיה הנדסית מהמעלה הראשונה. בפוסטים שלהם מתוארות שתי טכניקות קשורות. האחת היא דחיסת הקשר (context compaction), השומרת על המשכיות הפעולה על ידי קיצור ההיסטוריה. השנייה היא איפוס הקשר בשילוב עם העברה מובנית (structured handoff), המעניקה לסוכן חדש מספיק מידע על מצב האובייקטים כדי להמשיך בעבודה בצורה קוהרנטית. הם מציינים כי דחיסה בלבד לא תמיד פותרת את בעיית הסטייה (drift) וכי העברות מובנות עשויות להיות חיוניות. (אנתרופי)
זה מתאים כמעט באופן מושלם לבדיקות חדירה. מבצע אמיתי כמעט אף פעם אינו מתנהל בלולאה אחת רציפה. היעדים משתנים. הפעלות פוקעות. המפעילים עוצרים וממשיכים. פרטי הזדהות מתחלפים. לפיכך, מערכת תמיכה משמעותית זקוקה לזיכרון מתמשך ומובנה, שהוא עשיר יותר מהיסטוריית הצ'אט.
לכל הפחות, מודל הזיכרון צריך לכלול:
- רשימת מטען של טיסה,
- גרף נכסים,
- רשימת חוזים ומצבם,
- מרשם ממצאים,
- מאגר ראיות,
- העברת אחריות על התקדמות,
- ויומן סיכום הפעלה.
לעתים קרובות מספיקה תצורת תיקיות פשוטה:
campaign/ engagement.yaml assets/ asset_graph.json routes.json identities.json contracts/ 001-auth-flow.json 002-idor-orders.json findings/ candidates.jsonl verified.jsonl rejected.jsonl evidence/
002-idor-orders/ replay_case_a.har replay_case_b.har browser.png notes.md progress/ handoff.md latest_summary.json sessions/ 2026-04-11T0100Z.jsonl
2026-04-11T0900Z.jsonl
הבחירה העיצובית המרכזית היא שהמודל לעולם אינו נדרש לשחזר את הקמפיין כולו מתוך זיכרון פרוזאי. במקום זאת, המערכת מספקת לו מצב מובנה. זהו בדיוק הלקח שעליו הצביע PentestGPT באמצעות "עץ משימות הבדיקה" שלו, וזהו בדיוק סוג זרימת האובייקטים המובנית שעליה הסתמכה Anthropic בעבודתה ארוכת הטווח. (arXiv)
שכבה זו חשובה גם מבחינת יכולת הביקורת. בודק אנושי צריך להיות מסוגל לענות על שאלות פשוטות מבלי לבקש מהמודל לזכור דבר. אילו השערות נבדקו ונדחו? אילו אושרו? אילו נחסמו על ידי מדיניות? אילו עדיין זקוקות לאישור אנושי? אילו זהויות שימשו? אילו חבילות ראיות הושלמו? אם התשובה לשאלות אלה קיימת רק בתוך תמליל הסוכן, הרי שהמערכת עדיין לא בשלה.
שכבה 6: גרעין המדיניות ובקרות זמן ריצה
מודל האבטחה הציבורית של Claude Code הוא אחת הסיבות הברורות ביותר לכך שהוא משמש כנקודת התייחסות ארכיטקטונית. Anthropic אינה מציגה את השימוש בכלים כעניין של אמון בלבד. היא מציגה את השימוש בכלים כמשהו הנשלט על ידי אישורים, הוקס, סנדבוקסינג ומדיניות. בתיעוד של ההוקס נכתב ש-PreToolUse יכול לאשר, לדחות, לבקש או לדחות קריאות לכלים, ואף לשנות את קלט הכלים לפני הביצוע. ההפניה ל-hooks גם מזהירה כי hooks לפקודות פועלים עם כל ההרשאות של משתמש המערכת. הפוסט שלהם על sandboxing ברור באותה מידה כי sandboxing יעיל דורש הן בידוד של מערכת הקבצים והן בידוד רשת. ללא בידוד רשת, סוכן שנפרץ יכול להוציא קבצים רגישים; ללא בידוד מערכת הקבצים, הוא יכול לברוח ולהשיב לעצמו את הגישה לרשת. (תיעוד ה-API של Claude)
במסגרת בדיקות חדירה, משמעות הדבר היא שהמערכת זקוקה ל"גרעין מדיניות" הנמצא מחוץ למודל ומקבל את ההחלטות הסופיות לגבי מה שעשוי לקרות. דפוס שימושי הוא לסווג פעולות לארבע קטגוריות.
פעולות אוטומטיות הן קריאות בעלות סיכון נמוך הנכללות בהיקף הבדיקה ובדיקות מוגבלות.
פעולות הכפופות לאישור הן בדיקות אקטיביות העלולות לשנות את המצב או ליצור הפרעות.
פעולות מושהות הן בדיקות לגיטימיות שדורשות תגובה אנושית תחילה, כגון האם בדיקת העלאה בעלת השפעה נמוכה מקובלת עבור יעד זה.
פעולות אסורות הן כל מה שאינו נכלל במסגרת המותר.
קובץ מדיניות קצר יכול לבטא זאת בצורה ברורה:
מדיניות: - שם: passive-read התאמה: כלי: [Read, WebFetch, BrowserNavigate] היקף היעד: in_scope סוג הפעולה: passive החלטה: לאפשר
- שם: אימות-API-בעל-השפעה-נמוכה התאמה: כלי: [HttpRequest] שיטה: [GET, HEAD] היקף-יעד: in_scope rate_limit_ok: true החלטה: לאפשר
- שם: בדיקות-שינוי-מצב התאמה: כלי: [HttpRequest, BrowserAction] שיטה: [POST, PUT, PATCH, DELETE] היקף-יעד: in_scope החלטה: דחייה שאלה: "פעולה זו עשויה לשנות את מצב היישום. לאשר?"
- שם: external-callbacks התאמה: destination_scope: external החלטה: deny סיבה: "תשתית callback מחוץ להיקף נחסמת" - שם: exploit-like-execution התאמה: action_class: exploit_validation החלטה: deny סיבה: "ביצוע בסגנון ניצול נמצא מחוץ לפרופיל ההתקשרות הזה"
זה המקום שבו הרעיון של "דחייה והמשך" של Anthropic מקבל ערך מוסף. בתיאור הציבורי שלהם על מצב האוטומטי נכתב שכאשר המסווג חוסם פעולה, קלוד לא צריך פשוט לעצור; עליו להתאושש ולנסות נתיב בטוח יותר, אם קיים כזה. במסגרת מערך בדיקות חדירה, משמעות הדבר היא שפעולה הרסנית שנדחתה צריכה להפעיל מעבר לאישור פסיבי, ניתוח נתיב קוד, השוואת תפקידים או פנייה לבני אדם, במקום עצירה מוחלטת. (אנתרופי)
ליבת המדיניות צריכה גם להבין את הסיכונים הספציפיים ל-MCP. ההנחיות הרשמיות בנושא אבטחת MCP רלוונטיות במיוחד לצוותי אבטחה, מכיוון שהן אינן מנוסחות במונחים מעורפלים. הן מציינות בעיות של "סגן מבולבל", העברת אסימונים, SSRF, חטיפת הפעלה, פגיעה בשרת MCP מקומי ומזעור היקף כנקודות תורפה אמיתיות. מפרט ההרשאות של MCP מחייב גם אימות קהל היעד ודוחה במפורש דפוסים של שימוש לרעה באסימונים העלולים לטשטש את גבולות האבטחה בין שירותים. (פרוטוקול הקשר מודל)
מערכת בדיקות חדירה שמתחברת לכלי MCP אך אינה מאמתת באופן עצמאי את קהלי היעד של האסימונים, אינה אוכפת צמצום היקף, ואינה מפרידה בין אישורי הכניסה במעלה הזרם ובמורד הזרם, היא כמו בנייה על חול.
מדוע יש להתייחס ליעדים כאל קלט יריב
הטעות החמורה ביותר שאנשים עושים בבדיקות חדירה סוכניות היא ההנחה שהמטרה היא הדבר היחיד שנבדק. במציאות, כל מה שמגיע במגע עם מערך הבדיקה עלול להפוך למשטח תקיפה.
מחקר של חברת Anthropic בנושא הזרקת פקודות בדפדפן מציין זאת במפורש. כאשר סוכן גולש באינטרנט, כל דף מהווה וקטור תקיפה פוטנציאלי. הזרקת פקודות נותרה אתגר מרכזי שטרם נפתר, במיוחד כאשר הסוכנים מבצעים פעולות בעולם האמיתי, ו-Anthropic מציינת במפורש כי הבעיה לא נפתרה גם עם שיפור ההגנות. החומר של OWASP בנושא GenAI אומר את אותו הדבר במונחים כלליים יותר: הזרקת פקודות יכולה לחשוף נתונים רגישים, להעניק גישה לא מורשית לפונקציות, לבצע פקודות במערכות מחוברות ולתפעל תהליכי קבלת החלטות. הזרקת פקודות עקיפה רלוונטית במיוחד כאשר המודל צורך נתונים חיצוניים כגון דפים, מסמכים או קבצים. (אנתרופי)
לכך יש השלכות ישירות על בדיקות חדירה של בינה מלאכותית. גוף התגובה של היעד אינו מורכב רק מנתונים. חבילת JavaScript, צומת DOM, קובץ PDF, שדה הערות או דף תיעוד – כולם עשויים להכיל הוראות שנועדו לכוון את המודל. כך גם מאגר קוד, קובץ readme, קובץ פלט של כלי או תגובת API מדומה. לפיכך, על מערכת הבדיקה להתייחס ליעד כאל קלט עויין בכל שכבה.
דבר זה משנה את האופן שבו מעצבים את ה"עובדים". אסור לאפשר ל"עובד" ה-recon לפרש מחדש תוכן דף שרירותי כהוראות מהימנות. על ה-flow mapper להפריד בין תצפיות שחולצו לבין הוראות הסוכן. על ה-verifier לא לסמוך על הערות שמספק ה-executor. על ה-evidence writer לציין מה מקורם של הארטפקטים והאם הם נוצרו ממקורות מהימנים או לא מהימנים. הזרקת פקודות (prompt injection) אינה מקרה קיצון אופציונלי. היא חלק ממודל האיומים הרגיל בבדיקות סוכניות. (אנתרופי)
זה גם משנה את האופן שבו אתם תופסים כלים. מדריך האבטחה של MCP לא עוסק רק באסימונים. הוא מציין במפורש את הפריצה לשרת המקומי ואת צמצום היקף הפריצה, מכיוון שמישור הכלים הוא חלק ממשטח התקיפה. באופן דומה, התיעוד של Anthropic בנושא ה-hooks מזהיר כי hooks לפקודות מבוצעים עם כל ההרשאות של המשתמש. ברגע שמשלבים גישה לכלים, ביצוע פקודות, גישה לדפדפן, זיכרון ותצורה מקומית של מאגר הקוד, הגבול הישן בין "נתונים" ל"ביצוע" מתחיל להתמוסס. (פרוטוקול הקשר מודל)
דרך מועילה להתייחס לנושא זה היא לבנות מודל של ארבע קטגוריות קלט.
| מחלקת קלט | דוגמאות | הסיכון העיקרי | בקרה נדרשת |
|---|---|---|---|
| הוראות אמינות | מסמך התחייבות, אישורי מפעילים, כללי מדיניות | הרשאה רחבה מדי או מדיניות מיושנת | מדיניות גרסאות, בדיקה, בקרת שינויים |
| הקשר פנימי בעל אמינות חלקית | הערות, סיכומי העברת תיקים, ראיות קודמות | הטיה של הזיכרון, הנחות מיושנות | מבנים מובנים, תגי מקור, תוקף |
| תוכן יעד שאינו מהימן | HTML, JS, מסמכים, קבצי PDF, תגובות API | החדרת רמזים עקיפה, הטעיה, הוכחה כוזבת | תיוג קלט, ניתוח בסביבת בדיקה מבודדת, הימנעות מביצוע הוראות מרומזות |
| תוכן בנושא מישורי | יציאות MCP, כניסות הוק, תצורת רפו, סקריפטים מקומיים | ביצוע פקודות, גניבת אסימונים, "confused deputy", SSRF | רשימות כלי מורשים, אימות קהל, בידוד מכולות, מודל אמינות מאגרים |
הטבלה מהווה סיכום, אך היא מבוססת על דפוסי האיומים שתועדו על ידי Anthropic, OWASP וההנחיות הרשמיות של MCP עצמה בנושא אבטחה. (אנתרופי)
ה-CVE-ים שהופכים את הארכיטקטורה הזו לחובה
התכנון ברמה הגבוהה הופך להיות הרבה פחות מופשט כאשר בוחנים את מה שכבר קרה במערכות סוכנים דומות.
Langflow CVE-2025-3248 והמיתוס על נקודות קצה עוזרות בלתי מזיקות
NVD מתאר את CVE-2025-3248 כבעיית הזרקת קוד בגרסאות Langflow שקדמו לגרסה 1.3.0. נקודת הקצה הפגיעה הייתה /api/v1/validate/code, והפגיעות אפשרה לתוקף מרוחק ולא מאומת לשלוח בקשות שתוכננו במיוחד לביצוע קוד שרירותי. בהמשך הוסיפה CISA את הבעיה למסגרת העבודה שלה בנושא "פגיעות שנוצלו". (NVD)
מדוע זה רלוונטי למאמר על מסגרת לבדיקות חדירה? מכיוון שזו דוגמה מובהקת לכישלון שצוותים רבים עדיין נוטים לזלזל בו. מוצרי זרימת עבודה מבוססי בינה מלאכותית (AI) מכילים לעתים קרובות מסלולי "עזר" או "אימות" שנראים כמו פונקציות תומכות ולא כמו משטחי ביצוע מרכזיים. בפועל, דווקא הרכיב שנקרא "אימות" עשוי להיות המקום המדויק שבו מתרחשת ביצוע לא בטוח. אדריכל רתמות צריך ללמוד מכך שני לקחים. ראשית, יש למדל את יכולות העזר הפנימיות כגבולות ביצוע, ולא כתכונות נוחות. שנית, המדיניות והאימות חייבים לכסות את נקודות הקצה התומכות באותה נחישות כמו את אלה הברורות. (NVD)
מבחינת אנשי האבטחה, הסיפור בנוגע לצעדי המיתון מלמד לא פחות. ה-NVD מצביע על גרסאות מתוקנות ועל הפניות לספקים. ברמת הארכיטקטורה, התיקון אינו מסתכם רק ב"הוספת אימות". הוא כולל גם את העיקרון של "להפסיק להניח שתכונות אימות הקוד יכולות לעבד בבטחה קלט הנשלט על ידי תוקפים". זוהי תיקון בתכנון, ולא רק תיקון זמני. (NVD)
Langflow CVE-2026-33017 והסכנה שבתיקונים חלקיים
הבעיה המאוחרת יותר ב-Langflow חושפת עוד יותר. NVD מתאר את CVE-2026-33017 כפגיעות המאפשרת הרצת קוד מרחוק ללא אימות בגרסאות שקדמו לגרסה 1.9.0. נקודת הקצה הפגיעה, POST /api/v1/build_public_tmp/{flow_id}/flow, לא אומת בכוונה עבור זרימות ציבוריות, אך קיבל נתוני זרימה שבשליטת התוקף, שהכילו קוד Python שרירותי בהגדרות הצמתים, והעביר אותם אל exec() ללא סביבת בידוד כלל. ה-NVD מציין במפורש כי בעיה זו נבדלת מ-CVE-2025-3248. לא מדובר באותה תקלה שצצה שוב באותו נקודת קצה, אלא במודל ביצוע רחב יותר שהתגלה במקום אחר. ה-NVD מציין גם כי הפגיעות נכללה בקטלוג הפגיעות המנוצלות הידועות של ה-CISA במרץ 2026. (NVD)
זהו בדיוק סוג הלקח שעל מפתחי מסגרות לבדיקות חדירה של בינה מלאכותית להקפיד עליו. מערכת יכולה לתקן נקודת קצה מסוכנת אחת ועדיין לשמור על הדפוס הבסיסי במקום אחר. אם למסגרת שלכם יש מספר נתיבי קוד שיכולים להפוך נתונים לא מהימנים לקריאות לכלי, פעולות דפדפן או פקודות שורת פקודה, תיקון נקודת תורפה אחת אינו מספיק. אתם זקוקים לגבול ארכיטקטוני. בשפת Anthropic, זה אומר שכבות סנדבוקסינג והרשאות בפועל. בשפת רתמות בדיקות חדירה, זה אומר גרעין מדיניות מחוץ למודל וסביבת ריצה שלעולם לא מתייחסת למשטחים "ציבוריים" או "עוזרים" כבעלי סיכון נמוך באופן אוטומטי. (אנתרופי)
בעיות תצורה ברמת המאגר של Claude Code וגבול הביצוע החדש
המקרה המזהיר הרלוונטי ביותר ל-Claude Code עצמו הגיע ממחלקת המחקר של Check Point בפברואר 2026. בדו"ח שלהם נכתב כי תצורות פרויקט זדוניות עלולות לנצל לרעה הוקס, שילובים של MCP ומשתני סביבה כדי לבצע הרצת קוד מרחוק ולגנוב אישורי API כאשר משתמשים משכפלים ופותחים מאגרים לא מהימנים. בסיכום שלהם נכתב כי הבעיות תוקנו לפני הפרסום, אך הלקח הארכיטקטוני רחב יותר מהתיקון. הם טוענים כי קבצי התצורה ברמת המאגר הפכו לשכבת ביצוע פעילה במקום למטא-נתונים תפעוליים בלתי מזיקים. Check Point קישרה מחקר זה ל-CVE-2025-59536 ו-CVE-2026-21852. (מחקר Check Point)
ממצא זה תואם באופן מטריד את התיעוד של Anthropic עצמה. בתיאור ה-hooks נכתב כי hooks לפקודות פועלים עם כל ההרשאות של משתמש המערכת. בפוסט על סביבת ה-sandboxing נכתב כי הגנה יעילה מחייבת בידוד הן של מערכת הקבצים והן של הרשת. אם מחברים את הדברים יחד, קשה לפספס את המסקנה: ברגע שכלי סוכני יכול לקרוא קבצים, להריץ פקודות, להתחבר לכלים אחרים ולטעון תצורה מקומית של הפרויקט, תוכן המאגר הופך לחלק מגבולות ההרצה. (תיעוד ה-API של Claude)
בבדיקות חדירה מבוססות בינה מלאכותית, יש לכך חשיבות משתי סיבות. ראשית, מערך הבדיקה שלכם יפעל לעתים קרובות מול יעדים לא מהימנים, מאגרי קוד לא מהימנים, מסמכים לא מהימנים או תוכן דפדפן לא מהימן. שנית, צוותי בדיקות חדירה נוטים במיוחד לחבר יחד סקריפטים מקומיים, אינטגרציות פרוקסי, שרתים MCP ואוטומציה ספציפית לפרויקט. משמעות הדבר היא ש-harness שתוכנן בצורה לקויה עלול להיתקף על ידי אותה מערכת אקולוגית ממש שהוא משתמש בה כדי לבדוק אחרים. אם יש לקח אחד שאפשר ללמוד ממקרה Claude Code, שיהיה זה: התצורה היא חלק מזמן הריצה. יש לבנות את מודל האיומים בהתאם לכך.
מה משמעותם של מקרים אלה בפועל
שלושת המקרים שלעיל מצביעים על מסקנה משותפת אחת. הסיכון במערכות סוכניות אינו רק שהמודל יפעיל היגיון לקוי. הסיכון הוא שמסלול ביצוע כלשהו במערכת יקבל קלט לא מהימן כאילו היה בטוח להפעלה, בטוח לאישור או בטוח לאמון.
לכן העיצוב בן שש השכבות אינו סתם פורמליות. מישור ההתקשרות מונע חריגה מקרית. מהדר ההשערות מצמצם את היקף הביצוע. התמחות העובדים מצמצמת את התפשטות ההרשאות. המאמת מדכא הוכחות כוזבות. הזיכרון המתמשך מונע מאובדן מצב להפוך לסטייה מהנרטיב. גרעין המדיניות שומר על מישור הכלים תחת שליטה חיצונית. ללא שכבות אלה, אתם מהמרים על שלמותו של תהליך בדיקת חדירות על מודל שיישאר קוהרנטי וטוב לב בתנאים עוינים. התיעוד הציבורי כבר מראה שזה לא מספיק. (NVD)
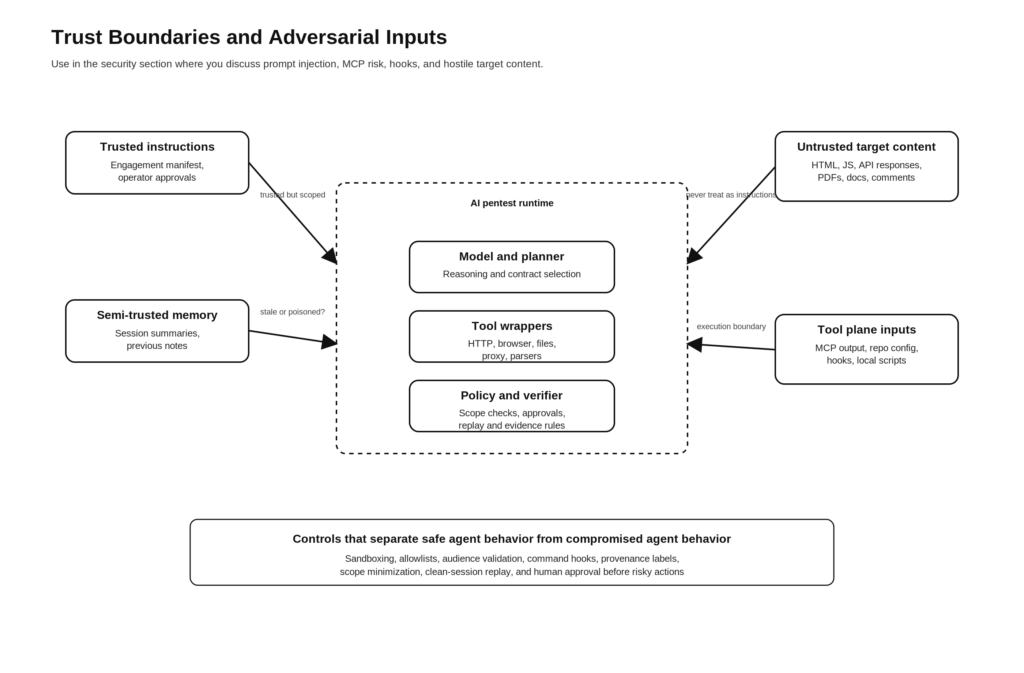
ארכיטקטורת ייחוס למערך בדיקות חדירה מבוסס בינה מלאכותית, המתמקד בראיות
ניתן לייצג את המערכת כולה בצורה תמציתית:
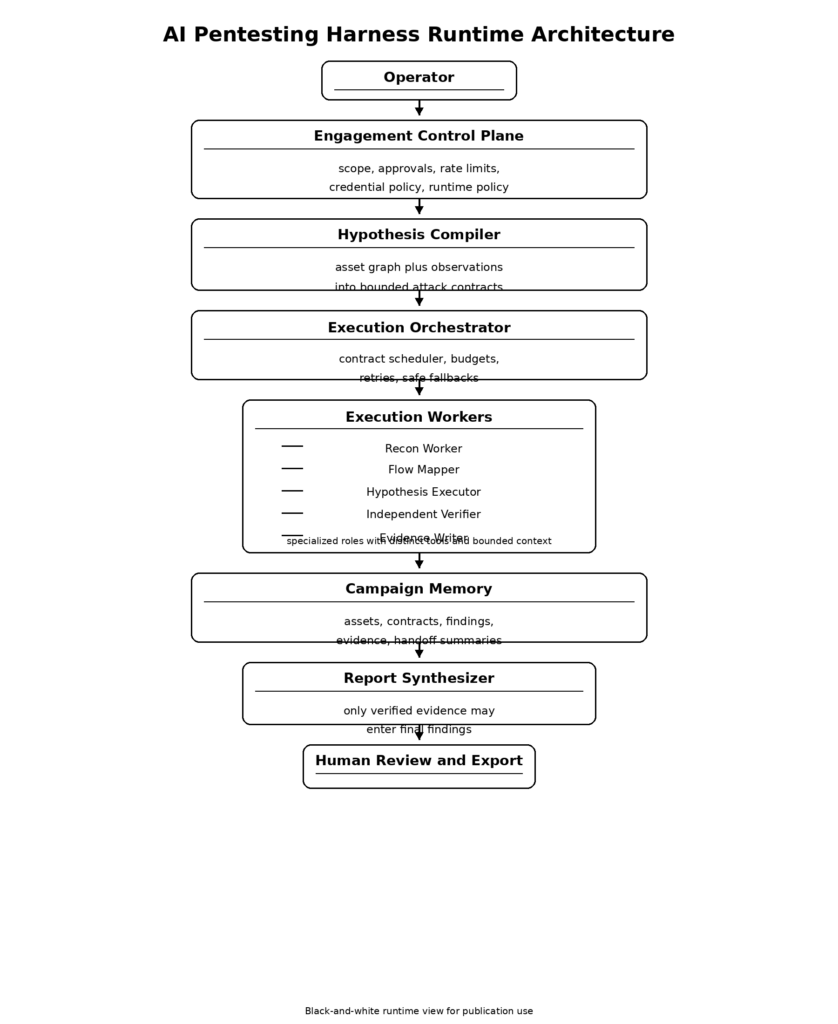
יש שתי סיבות לכך שהצורה הזו עובדת.
הראשון הוא שזה תואם את האופן שבו מתבצע בדיקה אמיתית. איסוף מודיעין (Recon) מביא לידי ביטוי אפשרויות. ניתוח זרימה (Flow analysis) הופך את האפשרויות לרעיונות לתקיפה. ביצוע (Execution) בודק רעיון מוגדר אחד בכל פעם. אימות (Verification) קובע אם התוצאה ראויה לאמון. הדיווח מתבצע רק לאחר מכן. NIST SP 800-115 ו-OWASP WSTG הם מסמכים שונים מאוד, אך שניהם מדגישים כי בדיקה היא תהליך, ולא שלב בודד בתפוקת הכלי. (מרכז המחקר למדעי המחשב של ה-NIST)
השני הוא שזה תואם את התצפיות הפומביות של Anthropic בנוגע לסוכנים. ביצוע משימות ארוכות משתפר כאשר העבודה מחולקת למרכיבים, כאשר אובייקטים המועברים בין שלבים משמרים את המצב, וכאשר מעריך ספקן נמצא מחוץ לגנרטור. עוזרים מתמחים משפרים את ניהול ההקשר. קריטריוני אימות משפרים את התוצאות. סביבות בדיקה (sandboxing) וגבולות מדיניות הופכים את האוטונומיה לבטוחה יותר. (אנתרופי)
גרסה ראשונה איתנה של מערכת זו אינה זקוקה לניצול אוטונומי. היא זקוקה להתקדמות מסודרת. מערך המינימום הניתן ליישום צריך להיות מסוגל:
- היקף ומדיניות היישום,
- לבנות גרף נכסים,
- לערוך חוזה אחד בכל פעם,
- לבצע בדיקות מוגבלות,
- להשמיע אותם בנפרד,
- ראיות מתמשכות,
- ולייצא תוצר שניתן לדווח עליו.
זה מספיק כדי לבדוק את הארכיטקטורה לפני שתוסיף התנהגות נועזת יותר.
מודל נתונים, גרף נכסים, חוזה התקפה, חבילת ראיות
ההחלטה ההנדסית החשובה ביותר במערכת מסוג זה היא להפסיק להתמקד בצ'אט חופשי ולהתחיל להתמקד באובייקטי נתונים.
האובייקט הראשון הוא גרף הנכסים. זהו לא רק רשימת כתובות URL. זהו גרף של דומיינים, נקודות קצה, פרמטרים, קבצי Cookie, כותרות, זהויות, תפקידים, נתיבי JavaScript, מאגרי אובייקטים, ממשקי ניהול ומעברים שנצפו ביניהם. מטרתו אינה רק להציג את הנתונים באופן חזותי, אלא לספק למערכת מודל שמיש למחשב, המציג היכן עשויים להתקיים גבולות אמון ונקודות תורפה.
סכימה מצומצמת יכולה להיראות כך:
from dataclasses import dataclass, field from typing import List, Dict @dataclass class AssetNode: id: str type: str labels: List[str] attributes: Dict[str, str] = field(default_factory=dict)
@dataclass class AssetEdge: source: str target: str relation: str evidence_refs: List[str] = field(default_factory=list)
האלמנט השני הוא חוזה ההתקפה. זהו יחידת העבודה ויחידת ההערכה. עליו להיות עמיד, מוגדר, ניתן להמשך וניתן לבדיקה. אם המערכת אינה יכולה לציין איזה חוזה היא מבצעת, מהו תנאי ההצלחה ומהן הראיות הנדרשות, היא עדיין פועלת כסוכן שיחתי ולא כמערכת לבדיקת חדירות.
הפריט השלישי הוא תיק הראיות. זהו הבסיס שעליו נבנה ממצא שיש לדווח עליו. לא פסקת טקסט. לא סיכום. תיק ראיות.
{ "finding_id": "idor-orders-001", "status": "verified", "severity_candidate": "high", "contracts": ["idor-orders-001"],
"artifacts": { "requests": ["req-1.json", "req-2.json"], "responses": ["res-1.json", "res-2.json"], "screenshots": ["browser-1.png"],
"har": ["session-a.har"], "logs": ["verifier-notes.md"] }, "reproduction": { "identities": ["user_a", "user_b"],
"steps": [ "התחבר כמשתמש_א", "לכוד את מזהה ההזמנה", "התחבר כמשתמש_ב", "הפעל מחדש את ה-GET כנגד מזהה ההזמנה של משתמש_א" ], "negative_case": "מזהה אקראי שאינו קיים מחזיר 404" },
"confidence": "high", "review_required": true }
זה המקום שבו משתלבת באופן טבעי עוד תובנה מאופקת בנוגע למוצר. חומר שפורסם לאחרונה על ידי Penligent בנוגע ל-Claude כ"טייס משנה" בבדיקות חדירה מעלה נקודה שקל להסכים איתה גם אם מתעלמים לחלוטין מהמותג: מערכת חזקה צריכה לשים דגש על דוחות הניתנים לעריכה, חומר הוכחת היתכנות שניתן לשחזר וממצאים מאומתים, ולא על תיאור בלתי ניתן לאימות שמספק הבינה המלאכותית. פלטפורמות בדיקות חדירה ציבוריות, המובנות בתוך זרימת העבודה וממקדות את התפוקות הללו, מכוונות לפתור את החלק הנכון של הבעיה. החלק הקשה הוא לא לגרום למודל להישמע חכם. החלק הקשה הוא לגרום לזרימת העבודה לשמר מספיק אמת כדי שמישהו אחר יוכל להריץ אותה מחדש. (Penligent)
דפוסי יישום וקוד
הלוגיקה המרכזית של התזמור אינה צריכה להיות מסתורית. היא רק צריכה להיות מסודרת.
לולאה פשוטה עשויה לפעול כך:
def run_campaign(campaign): while True: contract = campaign.next_ready_contract() if contract is None: break if not campaign.policy.allows(contract): campaign.defer(contract, reason="policy gate") continue execution_result = campaign.executor.run(contract)
if execution_result.status == "rejected": campaign.record_rejection(contract, execution_result) continue verification_result = campaign.verifier.run(contract, execution_result) if verification_result.status == "verified": bundle = campaign.evidence_writer.build_bundle( contract, execution_result, verification_result
) campaign.promote_finding(contract, bundle) elif verification_result.status == "needs_review": campaign.queue_human_review(contract, verification_result) else: campaign.record_rejection(contract, verification_result) campaign.write_handoff()
מה שחשוב אינו התחביר, אלא המבנה. הלולאה מאלצת כל מועמד לעבור את אותו תהליך: תזמון, קביעת מדיניות, ביצוע, אימות, שימור. דפוס זה הוא התרגום של תחום אבטחת המידע ההתקפית ל"לולאת הגנרטור-מנתח" של Anthropic ולדגש שהם שמים על קריטריוני האימות. (אנתרופי)
המאמת יכול גם לאכוף משמעת השמעה חוזרת באמצעות יצירת מקרים מפורשת:
def build_replay_cases(contract, candidate): cases = [] for identity in contract["required_identities"]:
cases.append({ "name": f"{contract['contract_id']}-{identity}-clean", "session_profile": identity, "request_spec": candidate["request_spec"], "expected_signal": candidate["expected_signal"] })
if contract.get("negative_case"): cases.append({ "name": f"{contract['contract_id']}-negative", "session_profile": contract["negative_case"]["identity"], "request_spec": contract["negative_case"]["request_spec"], "expected_signal": contract["negative_case"]["expected_signal"] }) return cases
בודק התומך בדפדפן יכול להוסיף תמונות מצב של ה-DOM או צילומי מסך כראיות תומכות, דבר הדומה מבחינה קונספטואלית לאופן שבו הבודק של Anthropic השתמש ב-Playwright כדי לבדוק את היישום הפועל, במקום להסתמך רק על פלט סטטי. (אנתרופי)
לבסוף, מנוע המדיניות יכול לפעול מאחורי מעטפות כלים במקום להיות משולב בתוך הפקודות:
def guarded_http_request(policy, request): decision = policy.evaluate_http(request) if decision.kind == "deny": raise PermissionError(decision.reason) if decision.kind == "defer": raise RuntimeError("נדרשת אישור אנושי") return send_http(request)
הבחירה הזו חשובה יותר מכפי שנדמה. אם המודל יכול רק "להבטיח" לכבד את תחום ההגדרה, אך סביבת ההרצה אינה יכולה לאכוף זאת, הרי שהמערכת שברירית מעצם מבנהה.
הערכת הרתמה, ולא רק הדגם
המאמר של Anthropic, "Demystifying evals for AI agents" (פישוט הערכות הביצועים של סוכני בינה מלאכותית), מציג את הנקודה באופן ישיר: כאשר מעריכים סוכן, מעריכים את שיתוף הפעולה בין מערכת הבדיקה למודל. זו צריכה להיות הנחת יסוד גם בבדיקות חדירה של בינה מלאכותית. (אנתרופי)
שאלה לא נכונה להערכה היא: "האם המודל הציע את הצעד הבא הנכון?" השאלות הנכונות להערכה קרובות יותר לאלה:
| מטרי | מדוע זה חשוב |
|---|---|
| שיעור השלמת החוזים | מציין אם מערך הבדיקות יכול להמיר תצפיות ליחידות בדיקה מוגמרות |
| שיעור ההצלחה בבחינות ההסמכה | מודד כמה בעיות פוטנציאליות שורדות בהפעלה חוזרת עצמאית |
| שיעור דיכוי התוצאות החיוביות השגויות | מציין אם המאמת מבצע עבודה בפועל |
| שלמות הראיות | בודק אם הממצאים אכן ראויים לדיווח |
| שיעור הפרות המדיניות | מזהה התנהגות לא בטוחה או החורגת מההיקף |
| קצב העלייה במספר הנפגעים | מסייע באיזון בין אוטונומיה לפיקוח |
| שיעור ההצלחה בקבלת עבודה | בודק אם קמפיינים ארוכים שורדים הפרעה |
| דיוק בבדיקה חוזרת של התיקון | בודק אם המערכת יכולה לאמת תיקונים מבלי לסטות מהמסלול |
הטבלה היא בעלת אופי תיאורטי ולא מבוססת על נתונים אמפיריים, אך היא נובעת ישירות ממסגרת ההערכה של Anthropic וממה שתקנים כגון NIST SP 800-115 ו-OWASP WSTG מצפים מעבודת בדיקה אמיתית. מערכת שמזהה מספר רב של תוצאות אפשריות אך מספקת ראיות חלשות והפרות תדירות של המדיניות, אינה עדיפה על מערכת איטית יותר עם ממצאים מעטים יותר, ברורים יותר וניתנים לשחזור. (אנתרופי)
מתודולוגיית ההערכה של PentestGPT מועילה גם כאן, שכן היא לא צמצמה את הביצועים לתוצאה בינארית סופית אחת של ניצול. המאמר מדגיש את ההתקדמות במשימות המשנה ואת ההישגים ההדרגתיים. זוהי גישה נכונה להערכת מערכות. יש לתת קרדיט לקמפיין על מיפוי נכסים מדויק, דחייה נכונה של השערות וטיפול קפדני במקרים שליליים, ולא רק על רגעים שבהם "נמצא ניצול". (arXiv)
דפוסי כשל נפוצים
רוב מערכות בדיקות הפריצה המבוססות על בינה מלאכותית לא נכשלות בגלל שהמודל חלש מדי. הן נכשלות משום שהארכיטקטורה שלהן מגדירה את הדבר הלא נכון כהצלחה.
טעות נפוצה אחת היא לאפשר לאותו עובד לבצע את הבדיקה וגם לאמת את תוצאותיה. ממחקריה הפומביים של חברת Anthropic בנושא מערכי בדיקה ארוכי טווח עולה כי קל יותר לכוון מעריכים נפרדים לגישה ספקנית מאשר מחוללים. בבדיקות חדירה, שילוב תפקידים אלה מהווה הזמנה להגזמת רמת הביטחון. (אנתרופי)
כישלון נוסף הוא התייחסות לזיכרון כאל מדיניות. מסגרת ה"סוכן האמין" של Anthropic מדגישה כי על בני האדם לשמור על השליטה וכי להרשאות יש חשיבות. הזיכרון תורם לרציפות, אך הוא אינו אוכף את תחום ההיקף. אם אמצעי השליטה היחיד שלך בתחום ההיקף הוא הערה שהמודל קרא קודם לכן, אין לך שליטה בתחום ההיקף. (אנתרופי)
טעות שלישית היא מתן גישה רחבה לשורת הפקודה או לרשת בשלב מוקדם מדי. בחומרי ההדרכה של Anthropic בנושא סנדבוקסינג מצוין במפורש כי יש חשיבות הן לבידוד מערכת הקבצים והן לבידוד הרשת. גם בתיעוד של ה-hooks מצוין במפורש כי hooks לפקודות פועלים עם כל ההרשאות של משתמש המערכת. אם מערך בדיקת חדירה מתחיל עם שורת פקודה בעלת הרשאות מלאות ונתיב רשת גלובלי, די בכניסה אחת שנפרצה כדי שהוא יהפוך לחלק מהבעיה. (אנתרופי)
טעות רביעית היא כתיבת דוחות המבוססים על תיאור הסוכן במקום על אוסף הראיות. זוהי הדרך הקצרה ביותר לתוצאות חיוביות כוזבות שנראות מקצועיות. ככל שמודל השפה משוכלל יותר, כך הדבר הופך למסוכן יותר, משום שהדוח נשמע ודאי גם כאשר הראיות שבבסיסו דלות.
טעות חמישית היא ההנחה שהזרקת פקודות היא בעיה הנוגעת בעיקר לצ'אטבוטים לצרכנים או לעוזרי דפדפן. מחקרי השימוש בדפדפנים של Anthropic והחומר של OWASP בנושא הזרקת פקודות מצביעים על אחרת. כל מערכת הצורכת תוכן לא מהימן ויכולה לבצע פעולות בכלים מחוברים נכללת בתחום זה. ערכת בדיקות חדירה ל-AI פועלת בדיוק בעולם הזה. (אנתרופי)
כיצד נראה מודל תפעולי בוגר
מערכת בדיקות חדירה מבוססת בינה מלאכותית בוגרת אינה מנסה לבטל את תפקידו של האדם. היא משנה את התחומים שבהם תפקידו של האדם הוא החשוב ביותר.
מסגרת ה"סוכנים האמינים" (Trustworthy Agents) של Anthropic מגדירה זאת כמצב שבו בני האדם שומרים על השליטה, תוך מתן אפשרות לאוטונומיה של הסוכנים. הדבר מתאים באופן ברור לתחום בדיקות החדירה. אין צורך שבני האדם יעתיקו ידנית כל כותרת לכל בקשת השמעה חוזרת. על בני האדם להחליט איזו קטגוריית סיכון של פעולה מקובלת, מה נחשב לתוצאה שיש לדווח עליה, ומתי תוצאה פוטנציאלית חשובה מספיק כדי להעביר אותה לדרג גבוה יותר. (אנתרופי)
בפועל, מודל תפעולי בוגר נראה בדרך כלל כך.
המפעיל מאשר את רשימת המטען ואת היעד שנקבע.
המערכת מבצעת סיור לקריאה בלבד ובונה גרף נכסים ראשוני.
מהדר ההיפותזות מייצר חוזים מוגבלים.
עובדי הביצוע מבצעים בדיקות בעלות סיכון נמוך באופן אוטומטי.
הבודק מפרסם רק תוצאות שניתן לשחזר באופן עצמאי.
בדיקות בעלות סיכון גבוה יותר נדחות עד לקבלת אישור המפעיל.
הדו"ח מבוסס על אוספי ראיות, ולא על תיאור מילולי.
לאחר התיקון, אותם חוזים מופעלים מחדש לצורך בדיקות רגרסיה.
מודל הפעולה הזה גם מקל על שילוב כלים במקום בחירה במחנה אחד. Claude Code, על פי המסמכים של Anthropic עצמה, הוא סביבת עבודה חזקה ומבוקרת המיועדת להסקת מסקנות תוך התחשבות במאגר הקוד, לשימוש בכלים מקומיים ולזרימות עבודה גמישות של סוכנים משנה. מערכות בדיקת חדירות (pentest) המותאמות לזרימת עבודה, כולל Penligent בחומרי הפרסום שלה, מותאמות לאימות מול היעד, שימור הוכחות ואריזת דוחות. הגישה הבוגרת היא לא לבלבל בין התפקידים הללו. היא להבין לאן כל אחד מהם שייך. (תיעוד ה-API של Claude)
סגירת המעגל
התרומה המשמעותית ביותר של "קוד קלוד" לבדיקות חדירה מבוססות בינה מלאכותית אינה אוסף של פקודות, אלא דרך לחשוב על סוכנים כעל מערכות.
ממחקרי ה-Harness הציבוריים של Anthropic עולה כי ביצוע משימות ארוכות משתפר כאשר ההקשר מנוהל באופן מכוון, העבודה מחולקת למרכיבים, המעריכים מופרדים, וההצלחה קשורה למבחנים קונקרטיים. PentestGPT קובע כי בדיקות חדירה אוטומטיות משתפרות כאשר אובדן הקשר מטופל כבעיית תכנון ולא כבעיית פקודה. NIST ו-OWASP מזכירים לנו כי בדיקות אבטחה הן תהליך מובנה הכולל תכנון, ביצוע, ניתוח ודיווח, ולא רצף של ניחושים מתוחכמים. CVE אמיתיים ב-Langflow ומחקר אמיתי על משטח הביצוע ברמת הריפו של Claude Code מראים מה קורה כאשר מערכות סוכניות מטשטשות את הגבול בין נוחות לשליטה. (אנתרופי)
לכן, השאיפה הנכונה אינה "לגרום למודל להרגיש עצמאי יותר". השאיפה הנכונה היא לבנות מסגרת שתוכל לשמור על מצב, לשמור על היקף, להפריד בין תכנון לפעולה, להפריד בין פעולה לאימות, ולהפריד בין ראיות לתיאור.
זהו ההבדל בין בינה מלאכותית המסייעת בביצוע בדיקות חדירה לבין תהליך בדיקת חדירה שאפשר באמת לסמוך עליו.
קריאה נוספת ומקורות
- Anthropic, רתמות יעילות עבור סוכנים הפועלים לאורך זמן. (אנתרופי)
- Anthropic, תכנון מסגרת לפיתוח יישומים הפועלים לאורך זמן. (אנתרופי)
- Anthropic, פישוט תהליך ההערכה של סוכני בינה מלאכותית. (אנתרופי)
- Anthropic, סקירה כללית של SDK ל-Agent. (תיעוד ה-API של Claude)
- Anthropic, שיטות עבודה מומלצות לכתיבת קוד עבור Claude. (קלוד)
- Anthropic, צור סוכנים משנה מותאמים אישית. (תיעוד ה-API של Claude)
- Anthropic, הפניה ל-Hooks. (תיעוד ה-API של Claude)
- Anthropic, מעבר להנחיות ההרשאה, מה שהופך את Claude Code לבטוח ואוטונומי יותר. (אנתרופי)
- Anthropic, מצב אוטומטי של Claude Code, דרך בטוחה יותר לעקוף הרשאות. (אנתרופי)
- Anthropic, הפחתת הסיכון של הזרקות מיידיות בשימוש בדפדפן. (אנתרופי)
- PentestGPT, מצגת בכנס USENIX Security 2024. (USENIX)
- המאמר על PentestGPT, גרסת HTML ב-arXiv. (arXiv)
- NIST SP 800-115, מדריך טכני לבדיקה והערכה של אבטחת מידע. (מרכז המחקר למדעי המחשב של ה-NIST)
- מדריך OWASP לבדיקות אבטחת אתרים. (OWASP)
- מדריך OWASP לבדיקות בינה מלאכותית. (OWASP)
- יוזמת האבטחה של OWASP Agentic ו-Top 10 ליישומים מבוססי Agentic לשנת 2026. (פרויקט אבטחת AI של OWASP Gen)
- הזרקת פקודות ב-OWASP LLM01. (פרויקט אבטחת AI של OWASP Gen)
- פרוטוקול Model Context, שיטות עבודה מומלצות בתחום האבטחה. (פרוטוקול הקשר מודל)
- פרוטוקול Model Context, מפרט ההרשאה. (פרוטוקול הקשר מודל)
- NVD, CVE-2025-3248. (NVD)
- NVD, CVE-2026-33017. (NVD)
- הודעת אבטחה של Langflow ב-GitHub בנוגע ל-CVE-2026-33017. (GitHub)
- מחקר Check Point: "Caught in the Hook" – הרצת קוד מרחוק (RCE) והוצאת אסימוני API באמצעות קבצי פרויקט של Claude Code. (מחקר Check Point)
- Check Point Research, סיכום הפגמים בקוד קלוד. (הבלוג של Check Point)
- כלי בדיקת חדירות מבוסס בינה מלאכותית: איך תיראה תקיפה אוטומטית אמיתית בשנת 2026. (Penligent)
- AI Pentest Copilot, מהצעות חכמות לממצאים מאומתים. (Penligent)
- Claude AI עבור Pentest Copilot: בניית תהליך עבודה שמבוסס על ראיות באמצעות Claude Code. (Penligent)
- קוד קלוד לבדיקות חדירה לעומת Penligent: היכן מסתיים תפקידו של מתכנת ומתחיל תהליך בדיקת החדירה. (Penligent)
- Claude Code Security ו-Penligent, מממצאי בדיקת "קופסה לבנה" להוכחת "קופסה שחורה". (Penligent)
- דף הבית של Penligent. (Penligent)

