क्लॉड कोड को सबसे आसानी से गलत समझा जाता है जब लोग इसे शेल एक्सेस वाले एक बेहतर प्रॉम्प्ट बॉक्स के रूप में मानते हैं। एंथ्रोपिक की अपनी सार्वजनिक सामग्री कुछ अधिक विशिष्ट का वर्णन करती है। एक हार्नेस, या स्कैफ़ोल्ड, वह प्रणाली है जो इनपुट को संसाधित करके, टूल कॉल्स का समन्वय करके, संदर्भ का प्रबंधन करके, और परिणाम लौटाकर एक मॉडल को एजेंट के रूप में कार्य करने देती है। Anthropic स्पष्ट रूप से कहता है कि जब आप किसी एजेंट का मूल्यांकन करते हैं, तो आप हार्नेस और मॉडल दोनों का एक साथ मूल्यांकन कर रहे होते हैं, न कि केवल मॉडल का अलग से। इसका एजेंट SDK भी इसी तरह से तैयार किया गया है: Claude Code एक प्रोग्रामेबल लाइब्रेरी के रूप में, जिसमें वही टूल्स, एजेंट लूप और संदर्भ प्रबंधन शामिल हैं जो Claude Code को ही शक्ति प्रदान करते हैं। (मानवजनित)
यह अंतर लगभग किसी भी अन्य अनुप्रयोग क्षेत्र की तुलना में आक्रामक सुरक्षा में अधिक मायने रखता है। पैठ परीक्षण कोई चैट समस्या नहीं है। यह एक ही समय में योजना बनाने की समस्या, स्थिति-प्रबंधन की समस्या, सत्यापन की समस्या, रिपोर्टिंग की समस्या और सुरक्षा की समस्या है। NIST SP 800-115 तकनीकी परीक्षण को एक ऐसी प्रक्रिया के रूप में परिभाषित करता है जिसमें योजना बनाना, परीक्षण करना, निष्कर्षों का विश्लेषण करना और शमन रणनीतियाँ विकसित करना शामिल है। OWASP वेब सुरक्षा परीक्षण गाइड अभी भी वेब परीक्षण को एक व्यापक अनुशासन के रूप में मानती है, जिसमें सूचना एकत्र करना, प्रमाणीकरण, प्राधिकरण, सत्र प्रबंधन, इनपुट सत्यापन, व्यावसायिक तर्क, और एपीआई परीक्षण शामिल हैं। OWASP एआई परीक्षण गाइड, जो 2025 के अंत में प्रकाशित होगी, उस मानसिकता को एआई प्रणालियों के लिए विश्वसनीयता परीक्षण तक बढ़ाती है। (एनआईएसटी सीएसआरसी)
PentestGPT पेपर ने शोध पक्ष से यही बात कही। इसके लेखकों ने पाया कि बड़े भाषा मॉडल अक्सर सुरक्षा उपकरणों का उपयोग करने, आउटपुट की व्याख्या करने और अगली कार्रवाइयों का प्रस्ताव रखने जैसे उप-कार्यों में अच्छे होते थे, लेकिन समय के साथ पूरे परीक्षण संदर्भ को बनाए रखने में संघर्ष करते थे। उनका उत्तर एक लंबा प्रॉम्प्ट नहीं था। यह तर्क, उत्पन्न करने और पार्सिंग के लिए अलग-अलग मॉड्यूल वाला एक त्रि-भागीय आर्किटेक्चर था, जिसे विशेष रूप से संदर्भ हानि को कम करने के लिए डिज़ाइन किया गया था। (arXiv)
यहीं पर Claude Code हार्नेस का विचार AI पेनेटस्टिंग के लिए उपयोगी हो जाता है। सबसे महत्वपूर्ण सबक यह नहीं है कि एक कोडिंग एजेंट कमांड चला सकता है। बहुत से सिस्टम कमांड चला सकते हैं। सबक यह है कि गंभीर एजेंट व्यवहार आसपास के सिस्टम से आता है: योजना परत, टूल सीमा, अनुमोदन मॉडल, हैंडऑफ़ आर्टिफैक्ट्स, सत्यापनकर्ता, और साक्ष्य श्रृंखला। Anthropic का अपना लंबे समय से चल रहा हार्नेस कार्य इसे स्पष्ट करता है। उनके सार्वजनिक इंजीनियरिंग पोस्ट में संदर्भ विचलन, "संदर्भ चिंता," संरचित हैंडऑफ़, प्लानर-जनरेटर-मूल्यांकनकर्ता भूमिकाएँ, स्प्रिंट अनुबंध, और एक अलग मूल्यांकनकर्ता के मूल्य का वर्णन है जो जनरेटर की तुलना में अधिक संशयवादी होता है। (मानवजनित)
अगर आप इसे पेनेट्रेशन टेस्टिंग में लागू करें, तो सवाल बदल जाता है। यह "क्या Claude Code पेनेट्रेशन टेस्टिंग कर सकता है?" से हटकर "अगर कोई पेनेट्रेशन टेस्ट हार्नेस Claude Code से सही विचार उधार लेकर उन्हें लक्ष्य-केंद्रित, साक्ष्य-प्रथम सुरक्षा कार्य के लिए अनुकूलित करे, तो वह कैसा दिखेगा?" बन जाता है। यही वह आर्किटेक्चर है जिसे बनाना सार्थक है।
मार्गदर्शन से सहारा देने तक
शिफ्ट को समझाने का सबसे तेज़ तरीका यह है: एक प्रॉम्प्ट व्यवहार मांगता है, जबकि एक हार्नेस व्यवहार को नियंत्रित करता है।
एक सरल एआई पेनेटस्ट सेटअप में, मॉडल को एक लक्ष्य मिलता है, शायद कुछ टूल्स, और "कमजोरियाँ खोजें" जैसी एक ढीली-ढाली निर्देश। कभी-कभी यह छोटे-मोटे कामों के लिए काम कर जाता है। एक वास्तविक अभियान में यह आमतौर पर चार बुरे परिणामों में से एक देता है। पहला है टूल थ्रैश, जहाँ मॉडल बिना किसी ठोस परिकल्पना पर पहुँचे सतही जानकारी जुटाने के लिए टूल्स का बार-बार इस्तेमाल करता रहता है। दूसरा है भंगुर स्थिति, जहाँ यह भूल जाता है कि तीन टूल कॉल पहले क्या महत्वपूर्ण था। तीसरा है कथासूत्र का अतिशयोक्ति (narrative inflation), जहाँ "यह कमजोर दिखता है" को एक पुष्ट निष्कर्ष की तरह लिखा जाता है। चौथा है असुरक्षित भटकाव (unsafe drift), जहाँ सिस्टम दायरा बढ़ा देता है या ऐसे कार्य करता है जिनके लिए कभी स्पष्ट रूप से प्राधिकरण नहीं दिया गया था। PentestGPT के संदर्भ-हानि (context loss) पर बेंचमार्क निष्कर्ष और एंथ्रोपिक (Anthropic) के लंबे समय तक चलने वाले एजेंट्स पर सार्वजनिक लेखन, एक ही मूल विफलता मोड की ओर इशारा करते हैं: समस्या सिर्फ तर्क की गुणवत्ता की नहीं है, बल्कि यह भी है कि मॉडल के आसपास की प्रणाली दिशा और नियंत्रण को बनाए रखती है या नहीं। (arXiv)
Anthropic की अपनी सर्वोत्तम-अभ्यास मार्गदर्शिका यहाँ काफी स्पष्टवादी है। यह कहती है कि आप जो सबसे अधिक प्रभावशाली काम कर सकते हैं, वह है Claude को अपने काम की पुष्टि करने का एक तरीका देना। स्पष्ट सफलता मानदंडों के बिना, आप ही एकमात्र फीडबैक लूप बन जाते हैं। कोड में, इसका मतलब है परीक्षण, स्क्रीनशॉट, या अपेक्षित आउटपुट। पेंटस्टिंग में, इसका अनुवाद और भी सशक्त है: नए सत्र, दोबारा चलाए जा सकने वाले अनुरोध, भूमिका परिवर्तन, ब्राउज़र स्थिति सत्यापन, और आर्टिफैक्ट कैप्चर। एक पेंटस्ट एजेंट जो अपने दावों का सत्यापन नहीं कर सकता, वह एक स्वायत्त परीक्षक नहीं है। यह खतरनाक स्तर के आत्मविश्वास वाला एक परिकल्पना जनरेटर है। (क्लॉड)
क्लाउड कोड एक ऐसा डिज़ाइन पैटर्न भी प्रस्तुत करता है जिसे सुरक्षा इंजीनियरों को लगभग शब्दशः अपनाना चाहिए: पहले सुरक्षित, पठन-उन्मुख योजना का उपयोग करें, फिर केवल तभी आगे बढ़ें जब आपके पास ऐसा करने का एक सीमित कारण हो। सार्वजनिक दस्तावेज़ों में प्लान मोड को स्पष्ट रूप से किसी भी बदलाव से पहले केवल-पठन विश्लेषण और आवश्यकता-संग्रह के लिए डिज़ाइन किया गया है। पेंटस्ट अनुवाद में, यह पहले recon-first योजना बन जाता है: क्रॉल करें, मैप करें, क्लस्टर करें, सहसंबंधित करें, और किसी भी स्थिति-परिवर्तनकारी कार्रवाई से पहले तय करें कि किस चीज़ की सक्रिय जाँच करनी चाहिए। (क्लाउड एपीआई दस्तावेज़)
उप-एजेंट्स पर भी यही तर्क लागू होता है। Anthropic की डॉक्स कस्टम उप-एजेंट्स को विशेष सहायक के रूप में वर्णित करती हैं, जिनके अपने प्रॉम्प्ट, अपने टूल एक्सेस, और अपने संदर्भ विंडो होते हैं। यह सिर्फ कोडिंग की सुविधा नहीं है। यह AI पेनेटस्टिंग के लिए एक अच्छा मानसिक मॉडल है, क्योंकि पुनर्प्राप्ति, व्यावसायिक प्रवाह की समझ, शोषण सत्यापन, और रिपोर्टिंग एक ही काम नहीं हैं और इन्हें समान अनुमतियाँ या समान संदर्भ साझा नहीं करना चाहिए।क्लाउड एपीआई दस्तावेज़)
नीचे दिया गया हार्नेस इसलिए क्लॉड कोड की नकल नहीं है। यह एक अनुवाद है।
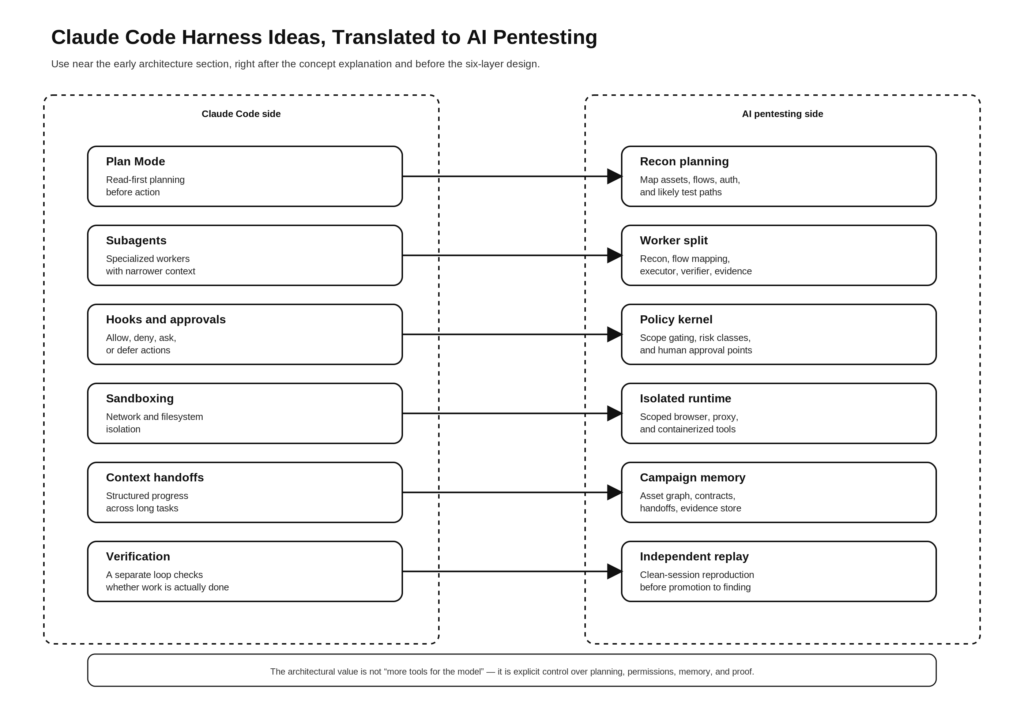
क्लाउड कोड में सार्वजनिक प्राइमिटिव्स एआई पेनेट्रेशन टेस्टिंग में क्या बन जाते हैं
एक बार कार्य का आकार स्पष्ट हो जाने पर मानचित्रण सरल होता है।
| क्लाउड कोड प्राइमिटिव | क्लाउड कोड में इसका क्या मतलब है | एआई पेनेटस्टिंग अनुवाद |
|---|---|---|
| योजना मोड | संपादन से पहले केवल-पठन विश्लेषण | केवल-पठन टोही, संपत्ति मानचित्रण, और लक्ष्य योजना |
| उप-एजेंट | विशिष्ट भूमिकाओं और उपकरणों तक पहुँच वाले विशेष सहायक | पुनरावलोकनकर्ता, प्रवाह मानचित्रक, निष्पादक, सत्यापक, साक्ष्य लेखक |
| PreToolUse और PermissionRequest हुक्स | टूल निष्पादन से पहले नीति नियंत्रण | दायरा, जोखिम श्रेणी, दर और अनुमोदन के लिए रनटाइम गेटकीपर |
| सैंडबॉक्सिंग | सुरक्षित स्वायत्तता के लिए फ़ाइल सिस्टम और नेटवर्क पृथक्करण | टेस्ट रनर, डोमेन अलाउलिस्ट, एग्रेस कंट्रोल्स, आइसोलेटेड ब्राउज़र और प्रॉक्सी शामिल थे। |
| संदर्भ संकुचन और हस्तांतरण | संदर्भ सीमाओं के बावजूद दीर्घ-कार्य निरंतरता | अभियान की स्मृति, सत्र सारांश, पुनः आरंभ करने योग्य संलग्नताएँ |
| क्लॉड को अपने काम को सत्यापित करने का एक तरीका दें। | परीक्षण और अपेक्षित परिणाम विश्वसनीयता में सुधार करते हैं। | पुनःप्रसारण, विसंगति तुलना, बहु-सत्र पुष्टि, पुनरुत्पादित साक्ष्य |
| स्वचालित मोड अस्वीकार-और-जारी रखें | यदि अवरुद्ध हो, तो वापस लौटें और एक सुरक्षित मार्ग आज़माएँ। | यदि सक्रिय परीक्षण अस्वीकार कर दिया जाए, तो निष्क्रिय या कम-जोखिम वाले सत्यापन पर वापस लौटें। |
यह एक संश्लेषण है, लेकिन प्रत्येक पंक्ति Anthropic की सार्वजनिक सामग्री पर आधारित है। उनके दस्तावेज़ और इंजीनियरिंग पोस्ट Plan Mode को केवल-पठन विश्लेषण, subagents को विशेषीकृत संदर्भ, hooks को अनुमति-अस्वीकृति-पूछताछ-स्थगन नियंत्रण बिंदु, sandboxing को फ़ाइल सिस्टम और नेटवर्क पृथक्करण, लंबे समय तक चलने वाले harnesses को संरचित बहु-एजेंट प्रणालियाँ जिनमें हस्तांतरण शामिल हैं, और verification को एजेंट विश्वसनीयता में सबसे अधिक प्रभाव वाली एकमात्र सुधार के रूप में वर्णित करते हैं।क्लाउड एपीआई दस्तावेज़)
इस लेख का बाकी हिस्सा उस तालिका का पेनटेस्ट संस्करण तैयार करता है।
एआई पेनेट्रेशन टेस्टिंग को सिर्फ एक मॉडल से अधिक की आवश्यकता क्यों है
एक पेनेट्रेशन टेस्ट स्वतंत्र रूप से घूमने वाले एकल एजेंट के लिए सबसे कठिन कार्यों में से एक है। लक्ष्य निरीक्षण के दौरान बदलता रहता है। प्रमाणीकरण की स्थिति मायने रखती है। व्यावसायिक तर्क मायने रखता है। पर्यावरणीय धारणाएँ मायने रखती हैं। एक "सफलता" झूठी हो सकती है यदि वह केवल दूषित सत्र में काम करती हो, केवल पहले से मौजूद एडमिन कुकीज़ के साथ काम करती हो, केवल किसी CDN आर्टिफैक्ट के खिलाफ काम करती हो, या केवल इसलिए दिखाई देती हो क्योंकि एजेंट ने शोर भरे उत्तर को प्रमाण के रूप में व्याख्या किया।
OWASP WSTG यहाँ उपयोगी बना रहता है क्योंकि यह परीक्षक को अलग-थलग स्कैनर हिट्स के बजाय व्यापक हमले की श्रेणियों में सोचने के लिए मजबूर करता है। AI Testing Guide इस अनुशासन को AI प्रणालियों पर लागू करता है, मूल्यांकन को भावनात्मक जाँच के बजाय व्यावहारिक, संरचित विश्वास परीक्षण के रूप में मानते हुए। PentestGPT एक अलग दृष्टिकोण से इसी दिशा में आगे बढ़ता है: वास्तविक प्रगति कार्य को विभाजित करने और स्थिति का प्रतिनिधित्व बनाए रखने से होती है।ओवास्प)
Anthropic के लंबे समय से चल रहे हार्नेस कार्य ने एक पूरक सबक जोड़ा। प्लानर-जेनरेटर-इवैल्यूएटर आर्किटेक्चर ने आउटपुट में सुधार किया क्योंकि एजेंटों ने सभी ने एक ही काम नहीं किया। प्लानर ने संक्षिप्त प्रॉम्प्ट्स को व्यापक विनिर्देशों में विस्तारित किया। जनरेटर ने क्रमिक रूप से निर्माण किया। मूल्यांकनकर्ता ने चल रही ऐप के साथ प्रत्यक्ष इंटरैक्शन का उपयोग किया और कठोर सीमाएँ लागू कीं। प्रत्येक स्प्रिंट से पहले, जनरेटर और मूल्यांकनकर्ता ने "पूरा" का क्या मतलब होगा, इस पर एक अनुबंध तय किया। यह बिल्कुल वही पैटर्न है जो पेनेटस्टिंग के लिए लगभग शर्मनाक रूप से उपयुक्त है। (मानवजनित)
पेंटस्टिंग की शब्दावली में, अनुवाद स्पष्ट है। प्लानर एक परिकल्पना संकलक बन जाता है। जनरेटर एक निष्पादन कार्यकर्ता बन जाता है। मूल्यांकनकर्ता एक स्वतंत्र सत्यापक बन जाता है। स्प्रिंट अनुबंध एक हमला अनुबंध बन जाता है। संपीड़न और हैंडऑफ़ प्रणाली अभियान स्मृति बन जाती है। परिणाम अमूर्त रूप से "अधिक एजेंटिक पेंटस्टिंग" नहीं है। यह एक ऐसी प्रणाली है जो संकेत से प्रमाण तक बिना चुपचाप अनुमानों को निष्कर्षों में बदलने के आगे बढ़ सकती है।
एक एआई पेनेट्रेशन टेस्टिंग हार्नेस की छह परतें
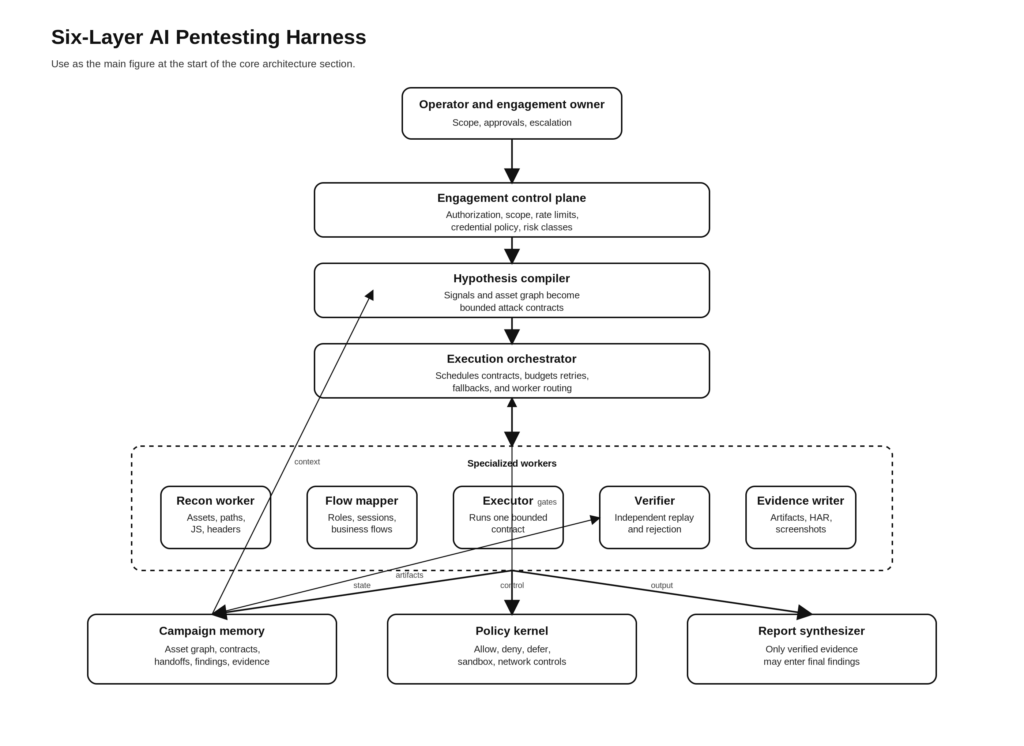
निम्नलिखित वास्तुकला वह डिज़ाइन है जिसे मैं तब तैयार करता यदि लक्ष्य Claude Code से सबसे मजबूत विचारों को उधार लेकर उन्हें अधिकृत, साक्ष्य-प्रथम AI पेनेट्रेशन परीक्षण के लिए अनुकूलित करना होता।
परत एक, संलग्नता नियंत्रण तल
हार्नेस पहली टूल कॉल से पहले ही शुरू हो जाता है। यह स्वयं संलग्नता से ही शुरू होता है।
NIST SP 800-115 तकनीकी परीक्षण के हिस्से के रूप में योजना पर जोर देता है, न कि सिस्टम के बाहर कागजी कार्रवाई के रूप में। Anthropic का ट्रस्टवर्थी-एजेंट्स फ्रेमवर्क एक अलग शब्दावली में लगभग यही बात कहता है: मनुष्यों को नियंत्रण में रखें, विशेषकर उच्च-दांव वाली कार्रवाइयों से पहले, और स्वायत्तता को एक ऐसी चीज़ के रूप में मानें जिसे सीमित होना चाहिए। Claude कोड को डिफ़ॉल्ट रूप से केवल-पठनीय (read-only) और सिस्टम संशोधन के लिए अनुमोदन-आधारित (approval-gated) बताया गया है। पेनटेस्टिंग के लिए, उसी तर्क को एक मशीन-पठनीय संलग्नता घोषणा-पत्र (engagement manifest) में एन्कोड किया जाना चाहिए जिसे रनटाइम हर बारी में उपभोग करता है। (एनआईएसटी सीएसआरसी)
एक उचित एंगेजमेंट कंट्रोल प्लेन में दायरा, प्राधिकरण विंडो, परीक्षण श्रेणियाँ, निषिद्ध क्रियाएँ, ट्रैफ़िक बजट, लक्ष्य लेबल, प्रमाण-पत्र सीमाएँ, ब्राउज़र प्रतिबंध, प्रॉक्सी राउटिंग, और साक्ष्य प्रतिधारण नियम शामिल होते हैं। इसमें जोखिम के आधार पर क्रियाओं का वर्गीकरण भी आवश्यक है। निष्क्रिय रीड और मेटाडेटा संग्रह एक श्रेणी हैं। कम-प्रभाव वाली सक्रिय सूचीकरण एक अन्य श्रेणी है। स्थिति-परिवर्तनकारी क्रियाएँ, प्रमाण-पत्र उपयोग, फ़ाइल अपलोड, या कोई भी शोषण-सदृश सत्यापन अलग-अलग गेट्स के पीछे होना चाहिए। नियंत्रण तल वह स्थान है जहाँ "अधिकृत पेन्टस्ट" प्रॉम्प्ट में एक वाक्य होना बंद हो जाता है और रनटाइम नीति बन जाता है।
एक न्यूनतम घोषणापत्र कुछ इस तरह दिख सकता है:
engagement:
id: acme-web-2026-q2
authorized_by: security-team
window_start: 2026-04-10T09:00:00Z
window_end: 2026-04-17T23:00:00Z
scope:
domains:
- app.example.com
- api.example.com
exclude_paths:
- /payments/live/*
- /admin/billing/*
allowed_identities:
- anonymous
- low_priv_user
forbidden_targets:
- thirdparty.example.net
- *.internal.example.com
runtime:
max_rps: 2
browser_allowed: true
upload_tests_allowed: false
credential_rotation_required: true
network_allowlist:
- app.example.com
- api.example.com
- auth.example.com
risk_policy:
passive_recon: auto
low_impact_validation: auto
state_changing_actions: human_approval
exploit_like_execution: forbidden
external_callbacks: forbidden
reporting:
capture_har: true
capture_screenshots: true
redact_secrets: true
वह उदाहरण सरल है, लेकिन वास्तुशिल्पीय बिंदु बड़ा है। एक पेनेटस्ट एजेंट को केवल अंग्रेज़ी से ही संलग्नता के दायरे का अनुमान कभी नहीं लगाना चाहिए। कंट्रोल प्लेन को कठोर रनटाइम निर्णयों में पार्स किया जाना चाहिए। एंथ्रोपिक का हुक्स मॉडल यहाँ उपयोगी प्रेरणा है क्योंकि यह टूल निष्पादन से पहले निर्णय बिंदुओं को औपचारिक रूप देता है, जबकि उनका सुरक्षा ढांचा यह सुनिश्चित करता है कि उच्च-दांव वाले कार्यों से पहले मनुष्य नियंत्रण बनाए रखें।क्लाउड एपीआई दस्तावेज़)
परत दो, परिकल्पना संकलक और स्प्रिंट अनुबंध
अगली परत अवलोकनों को सीमित कार्य में अनुवादित करती है।
क्लाउड कोड के लंबे समय से चल रहे एप्लिकेशन हार्नेस ने एक प्लानर का उपयोग करके संक्षिप्त संकेतों को व्यापक उत्पाद विनिर्देशों में विस्तारित किया, फिर यह तय करने के लिए जनरेटर-मूल्यांकनकर्ता वार्ता का उपयोग किया कि क्या एक पूर्ण स्प्रिंट माना जाएगा। पेंटस्टिंग में, इसका समकक्ष कोई फीचर प्लान नहीं है। यह स्पष्ट परीक्षण शर्तों के साथ एक हमला परिकल्पना है।मानवजनित)
यह महत्वपूर्ण है क्योंकि पेनेट्रेशन टेस्टिंग सिर्फ टूल चलाना नहीं है। यह परिकल्पना प्रबंधन है। एक परीक्षक एक व्यवहार देखता है, एक सिद्धांत बनाता है, पूछता है कि उस सिद्धांत के मायने रखने के लिए क्या सत्य होना चाहिए, और फिर एक जांच डिजाइन करता है। हार्नेस को इसे स्पष्ट करना चाहिए। मॉडल को "test auth" कहने के बजाय, सिस्टम को एक अनुबंध बनाना चाहिए जैसे: "यह लक्ष्य तीन एंडपॉइंट्स पर उपयोगकर्ता-नियंत्रित ऑब्जेक्ट पहचानकर्ता स्वीकार करता प्रतीत होता है। परीक्षण करें कि क्या भूमिका परिवर्तन के दौरान केवल कम-अधिकार वाले क्रेडेंशियल्स का उपयोग करके, संरक्षित रिकॉर्ड्स को परिवर्तित किए बिना, सर्वर-साइड पर प्राधिकरण लागू होता है।" यह वह कार्य है जिसे मॉडल निष्पादित कर सकता है। "कुछ दिलचस्प खोजो" नहीं।
एक व्यावहारिक हमला अनुबंध में कम से कम ये क्षेत्र होते हैं:
{
"contract_id": "idor-orders-001",
"target": "",
"goal": "यह सत्यापित करना कि उपयोगकर्ता भूमिकाओं में ऑब्जेक्ट-स्तर का प्राधिकरण लागू किया गया है या नहीं",
"पूर्व-शर्तें": [
"अलग-अलग ऑर्डर सेट तक पहुंच वाले दो कम-विशेषाधिकार वाले खाते",
"प्रत्येक रीप्ले के लिए क्लीन सेशन"
],
"अनुमत-क्रियाएं": [
"GET अनुरोध",
"ब्राउज़र नेविगेशन",
"सेशन रीसेट",
"प्रतिक्रिया अंतर"
],
"प्रतिबंधित_क्रियाएं": [
"रिकॉर्ड संशोधन",
"बल्क सूचीकरण",
"बाहरी कॉलबैक"
],
"सफलता_संकेत": [
"सुरक्षित ऑर्डर डेटा तक क्रॉस-खाता पहुंच",
"दो क्लीन सेशन में स्थिर पुनरुत्पादन"
],
"विफलता_संकेत": [
"लगातार प्राधिकरण अस्वीकृति",
"व्यवहार केवल दूषित सत्र स्थिति में दिखाई देता है"
],
"आवश्यक_साक्ष्य": [
"अनुरोध और प्रतिक्रिया की जोड़ी",
"भूमिका मैपिंग",
"ट्रांसक्रिप्ट का पुन: प्रसारण",
"यदि ब्राउज़र में दिखाई दे तो स्क्रीनशॉट"
],
"जोखिम_वर्ग": "मध्यम",
"बजट": {
"अधिकतम_अनुरोध": 20,
"अधिकतम_अवधि_सेकंड": 600
},
"निकास_शर्त": "कारणों के साथ सत्यापित या अस्वीकृत"
}
यह अनुबंध एक साथ दो काम करता है। यह खोज क्षेत्र को संकीर्ण करता है और साक्ष्य की सीमा को बढ़ाता है। Anthropic की सार्वजनिक हार्नेस में उल्लेख है कि जनरेटर और मूल्यांकनकर्ता ने काम शुरू होने से पहले एक स्प्रिंट अनुबंध पर बातचीत की, क्योंकि मूल्यांकनकर्ता को 'पूर्णता' की एक परीक्षण योग्य परिभाषा चाहिए थी। यही अनुशासन सुरक्षा में और भी अधिक मूल्यवान है, जहाँ 'पूर्णता' को अन्यथा खतरनाक रूप से आसानी से नकली बनाया जा सकता है।मानवजनित)
परत तीन, विशेषीकृत निष्पादन कार्यकर्ता
सबएजेंट्स Claude Code स्टैक में सबसे अधिक हस्तांतरणीय विचारों में से एक हैं। Anthropic उन्हें कार्य-विशिष्ट वर्कफ़्लो और बेहतर संदर्भ प्रबंधन के लिए विशेष सहायक के रूप में वर्णित करता है। यह उन सभी को तुरंत सही लगेगा जिन्होंने वास्तविक पेनेटस्टिंग की है। रिकॉन, ऑथ-फ़्लो मैपिंग, एक्सप्लॉइट वैलिडेशन, और रिपोर्ट लेखन अलग-अलग काम हैं। इन्हें एक ही प्रॉम्प्ट, टूल, या अधिकार साझा नहीं करना चाहिए।क्लाउड एपीआई दस्तावेज़)
एक परिपक्व पेनेट्रेशन टेस्टिंग हार्नेस को न्यूनतम रूप से पाँच निष्पादन भूमिकाओं को अलग करना चाहिए।
पहला एक पुनर्खोज कार्यकर्ता है। इसका काम सतह क्षेत्र की खोज करना और उसे सामान्य बनाना है: होस्ट, पथ, एंडपॉइंट, पैरामीटर, जावास्क्रिप्ट रूट, लॉगिन वेरिएंट, हेडर, ऑब्जेक्ट स्टोर, एडमिन इंटरफेस और थर्ड-पार्टी निर्भरताएँ। इसे उपकरणों का व्यापक उपयोग करना चाहिए, लेकिन इसकी विशेषाधिकार क्षमता कम होनी चाहिए। इसे रिपोर्टिंग के संदर्भ में निष्कर्षों को "मान्य" करने की अनुमति नहीं होनी चाहिए।
दूसरा एक फ्लो मैपर है। यह वर्कर स्कैनर की तुलना में थ्रेट-मॉडेलिंग एनालिस्ट के अधिक करीब है। यह एंडपॉइंट सूचियों को व्यवहारों में बदलता है। कौन-कौन सी पहचान मौजूद हैं? संक्रमण कहाँ हैं? कौन-कौन सी क्रियाएँ स्टेटफुल हैं? ब्राउज़र ट्रैफ़िक में कौन-कौन सी ऑब्जेक्ट प्रकार दिखाई देते हैं? कौन-कौन से छिपे हुए फ़ील्ड्स वर्कफ़्लो निर्णयों को आकार देते हैं? इसका आउटपुट कोई भेद्यता दावा नहीं है। यह व्यावसायिक व्यवहार का एक संरचित ग्राफ़ है।
तीसरा एक हाइपोथिसिस एक्ज़ीक्यूटर है। यह वह वर्कर है जो वास्तव में किसी कॉन्ट्रैक्ट के आधार पर बाउंडेड एक्टिव चेक्स चलाता है। इसे केवल उसी कॉन्ट्रैक्ट द्वारा आवश्यक टूल्स और परमिशन मिलनी चाहिए। और कुछ नहीं। एंथ्रोपिक की सबएजेंट्स, परमिशन और हुक्स पर सार्वजनिक दस्तावेज़ीकरण इस सीमित प्रतिनिधिमंडल शैली का दृढ़ता से समर्थन करता है: विशेषीकृत संदर्भों का उपयोग करें और प्रत्येक यूनिट को वास्तव में आवश्यक टूल एक्सेस तक ही सीमित करें।क्लाउड एपीआई दस्तावेज़)
चौथा एक सत्यापक है। यह कर्ता उस इकाई से अलग होना चाहिए जिसने प्रारंभिक जाँच की थी। Anthropic का लंबे समय से चल रहा हार्नेस कार्य यहाँ विशेष रूप से उपयोगी है क्योंकि यह तर्क देता है कि आत्म-मूल्यांकन कमजोर है और एक अलग मूल्यांकनकर्ता को संशयवाद की ओर समायोजित करना आसान है। पेनेटस्टिंग के लिए, यह सिद्धांत कोई अनुकूलन नहीं है। यह वैधता की आवश्यकता है।मानवजनित)
पाँचवाँ एक साक्ष्य लेखक है। इसका काम कच्चे ट्रेस को उन आर्टिफैक्ट्स में बदलना है जिन्हें कोई दूसरा इंजीनियर फिर से चला सके। इसका मतलब है अनुरोध-प्रतिक्रिया जोड़े, HAR स्निपेट्स, स्क्रीनशॉट, पर्यावरण नोट्स, भूमिका असाइनमेंट, नकारात्मक मामले और सफाई नोट्स। यदि आपका हार्नेस इस वर्कर को एक्ज़ीक्यूटर में मिला देता है, तो साक्ष्य कैप्चर चयनात्मक और अव्यवस्थित हो जाता है।
आप बाद में और भूमिकाएँ जोड़ सकते हैं, लेकिन ये पाँच भूमिकाएँ कर्तव्यों के बीच स्वस्थ अलगाव बनाने के लिए पर्याप्त हैं।
परत चार, स्वतंत्र सत्यापन लूप
यह वह परत है जो यह तय करती है कि सिस्टम एक पेनटेस्ट हार्नेस है या एक कहानी सुनाने वाली मशीन।
Anthropic के बेस्ट-प्रैक्टिसेज़ पेज पर कहा गया है कि स्पष्ट सत्यापन मानदंड वह एकल सुधार है जिसका प्रभाव सबसे अधिक होता है। उनके लंबे समय से चल रहे एप्लिकेशन हार्नेस ने इसे गंभीरता से लिया और मूल्यांकनकर्ता को Playwright तक पहुंच तथा कठोर सीमाएँ प्रदान कीं। मूल्यांकनकर्ता किसी स्प्रिंट को असफल कर सकता था यदि कोई भी प्रमुख मानदंड पूरा नहीं होता। सुरक्षा में, इसका समकक्ष वर्णन करना सरल है लेकिन नकली बनाना कठिन: कोई निष्कर्ष तब तक पूरा नहीं माना जाता जब तक कोई स्वतंत्र सत्यापक नियंत्रित परिस्थितियों में संबंधित व्यवहार को दोहरा नहीं सकता।क्लॉड)
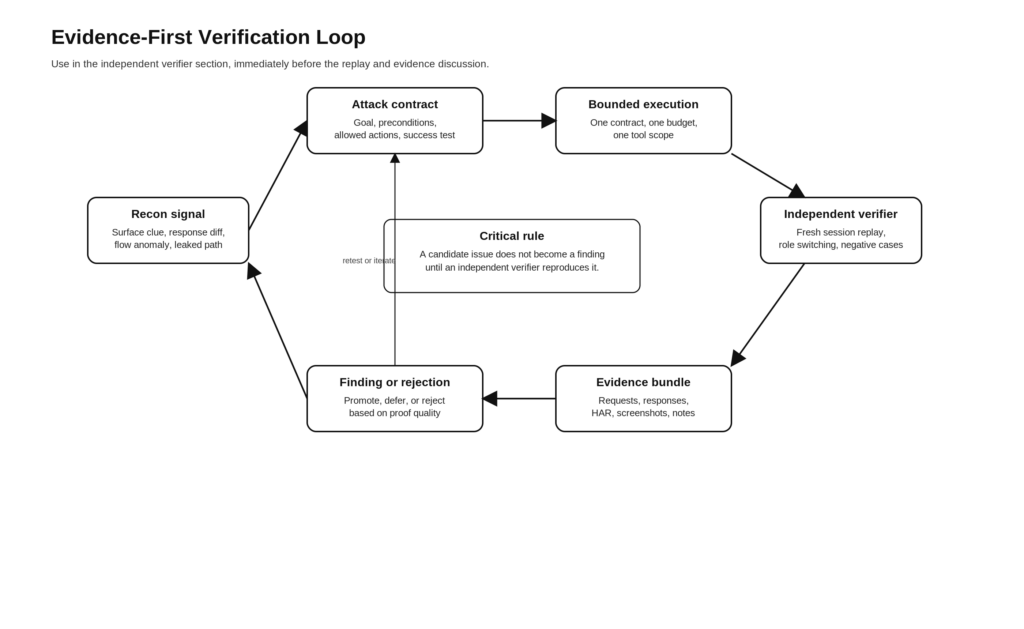
वेब और एपीआई परीक्षण के लिए, एक स्वतंत्र सत्यापक को आमतौर पर निम्नलिखित का कुछ मिश्रण करना होता है:
- सत्र को रीसेट करें और स्वच्छ स्थिति से पुनः चलाएँ।
- भूमिकाएँ या पहचान बदलें और व्यवहार की तुलना करें।
- यह पुष्टि करें कि परिणाम कैश किए गए क्लाइंट स्टेट या दूषित कुकीज़ के कारण नहीं हुआ है।
- यह पुष्टि करें कि परिणाम कोई अस्थायी अपस्ट्रीम समस्या, प्रॉक्सी आर्टिफैक्ट, या WAF विसंगति नहीं है।
- नकारात्मक मामलों को शामिल करें ताकि रिपोर्ट यह बता सके कि समस्या क्या नहीं है।
- मॉडल की व्याख्या पर भरोसा किए बिना कोई मानव इसे फिर से चला सके, इसके लिए पर्याप्त सबूत इकट्ठा करें।
एक छोटा पुनरावृत्ति ढांचा कुछ इस तरह दिख सकता है:
from dataclasses import dataclass
from typing import List, Dict
@dataclass
class ReplayCase:
name: str
session_profile: str
request_spec: Dict
expected_signal: str
@dataclass
class VerificationResult:
case_name: str
observed_signal: str
matched: bool
artifacts: List[str]
notes: str
def run_verification(cases: List[ReplayCase], runner) -> List[VerificationResult]:
results = []
for case in cases:
runner.reset_session(case.session_profile)
response = runner.send(case.request_spec)
observed = runner.classify_signal(response)
artifacts = []
artifacts.append(runner.save_request_response(case.name, response))
if runner.browser_visible(response):
artifacts.append(runner.save_screenshot(case.name))
results.append(
VerificationResult(
case_name=case.name,
observed_signal=observed,
matched=(observed == case.expected_signal),
artifacts=artifacts,
notes=runner.explain_difference(case.expected_signal, observed)
)
)
return results
कोड जानबूझकर साधारण रखा गया है। महत्वपूर्ण बिंदु प्रक्रियात्मक है। सत्यापन एक अलग चरण है, न कि बाद की सोच। एंथ्रोपिक की विश्वसनीय एजेंट्स पर सार्वजनिक लेखनी भी नियंत्रण पक्ष को मजबूत करती है: एजेंट मूल्यवान हैं क्योंकि वे कार्य कर सकते हैं, लेकिन उच्च-दांव वाले निर्णयों या कार्रवाइयों से पहले नियंत्रण मनुष्यों के पास ही रहना चाहिए। एक पेनटेस्ट हार्नेस को "उम्मीदवार समस्या" से "रिपोर्ट योग्य निष्कर्ष" तक पदोन्नति को उन उच्च-दांव वाले परिवर्तनों में से एक मानना चाहिए। (मानवजनित)
यहीं वह बिंदु है जहाँ एक वर्कफ़्लो-नेटिव आक्रामक प्लेटफ़ॉर्म को, अस्थायी रूप से एक साथ जोड़े गए उपकरणों के ढेर की तुलना में, औचित्यसंगत ठहराना आसान हो जाता है। पेनलिजेंट की सार्वजनिक सामग्री बार-बार उसी मानक पर लौटती है: संकेत पर्याप्त नहीं है, और एक उपयोगी वर्कफ़्लो वह है जो निष्कर्षों को सत्यापित प्रभाव में बदलता है, एक प्रूफ़ चेन को संरक्षित रखता है, और परिणाम को संपादन योग्य रिपोर्टिंग में पैकेज करता है। इसका होमपेज स्कोप लॉकिंग, अनुकूलन योग्य क्रियाओं, संकेत से प्रमाण तक निर्देशित निष्पादन और रिपोर्टिंग पर जोर देता है, जबकि हालिया तकनीकी पोस्ट अनुकूलनीय परीक्षण, संरक्षित स्थिति और सत्यापित निष्कर्षों पर, वर्णनात्मक अनुमानों के बजाय, जोर देती हैं। चाहे कोई टीम उस विशिष्ट प्लेटफ़ॉर्म का उपयोग करे या न करे, संचालन सिद्धांत बिल्कुल सही है: रिपोर्ट साक्ष्य श्रृंखला का अंत होनी चाहिए, न कि उसका विकल्प। (पेनलिजेंट)
परत पाँच, स्थायी स्मृति और हस्तांतरण
Anthropic के लंबे समय से चल रहे हार्नेस कार्य की एक शांत ताकत यह है कि यह स्थिति को प्रथम श्रेणी की इंजीनियरिंग समस्या के रूप में देखता है। उनके पोस्ट दो संबंधित तकनीकों का वर्णन करते हैं। एक है संदर्भ संकुचन, जो इतिहास को छोटा करके सत्र को जारी रखता है। दूसरी है संदर्भ रीसेट और संरचित हैंडऑफ़, जो एक नए एजेंट को सुसंगत रूप से काम जारी रखने के लिए पर्याप्त आर्टिफैक्ट स्थिति प्रदान करता है। वे उल्लेख करते हैं कि केवल संकुचन हमेशा ड्रिफ्ट को हल नहीं करता और संरचित हैंडऑफ़ आवश्यक हो सकते हैं। (मानवजनित)
यह लगभग पूरी तरह पेनेटस्टिंग से मेल खाता है। एक वास्तविक अभियान शायद ही कभी एक ही बिना रुकावट वाले चक्र के रूप में होता है। लक्ष्य बदलते हैं। सत्र समाप्त हो जाते हैं। ऑपरेटर रुकते और फिर से शुरू करते हैं। क्रेडेंशियल बदलते रहते हैं। इसलिए एक सार्थक हार्नेस के लिए चैट इतिहास से कहीं अधिक समृद्ध, स्थायी और संरचित मेमोरी की आवश्यकता होती है।
न्यूनतम रूप से, मेमोरी मॉडल में शामिल होना चाहिए:
- एक संलग्नता प्रकट
- एक संपत्ति ग्राफ़
- संविदाओं की सूची और उनकी स्थिति,
- एक खोज रजिस्ट्री
- एक साक्ष्य भंडार
- प्रगति का हस्तांतरण
- और एक सत्र सारांश लॉग।
एक सरल निर्देशिका लेआउट अक्सर पर्याप्त होता है:
campaign/
engagement.yaml
assets/
asset_graph.json
routes.json
identities.json
contracts/
001-auth-flow.json
002-idor-orders.json
findings/
candidates.jsonl
verified.jsonl
rejected.jsonl
evidence/
002-idor-orders/
replay_case_a.har
replay_case_b.har
browser.png
notes.md
progress/
handoff.md
latest_summary.json
sessions/
2026-04-11T0100Z.jsonl
2026-04-11T0900Z.jsonl
मुख्य डिज़ाइन विकल्प यह है कि मॉडल को कभी भी संपूर्ण अभियान को केवल स्मृति में रखे हुए पुनर्निर्मित करने की आवश्यकता नहीं होती। इसके बजाय, हार्नेस इसे टाइप की गई स्थिति प्रदान करता है। यह बिल्कुल वही सबक है जिसकी ओर PentestGPT ने अपने Pentesting Task Tree के साथ इशारा किया था, और यह बिल्कुल उसी प्रकार का संरचित आर्टिफैक्ट प्रवाह है जिस पर Anthropic ने दीर्घकालिक कार्यों में भरोसा किया था।arXiv)
यह परत ऑडिटबिलिटी के लिए भी महत्वपूर्ण है। एक मानव समीक्षक को मॉडल से कुछ भी याद रखने को कहे बिना सरल प्रश्नों का उत्तर देने में सक्षम होना चाहिए। कौन-सी परिकल्पनाओं का परीक्षण किया गया और उन्हें खारिज किया गया? कौन-सी परिकल्पनाओं को बढ़ावा दिया गया? नीति द्वारा किन परिकल्पनाओं को अवरुद्ध किया गया? किन परिकल्पनाओं को अभी भी मानव अनुमोदन की आवश्यकता है? किन पहचानों का उपयोग किया गया? कौन-से साक्ष्य समूह पूर्ण हैं? यदि इन प्रश्नों का उत्तर केवल एजेंट ट्रांसक्रिप्ट में मौजूद है, तो यह हार्नेस अभी परिपक्व नहीं हुआ है।
परत छह, नीति कर्नेल और रनटाइम नियंत्रण
क्लाउड कोड का सार्वजनिक सुरक्षा मॉडल उन स्पष्ट कारणों में से एक है कि यह एक वास्तुशिल्प संदर्भ के रूप में उपयोगी है। एंथ्रॉपिक टूल के उपयोग को केवल विश्वास का मामला नहीं मानता है। यह टूल के उपयोग को अनुमोदन, हुक्स, सैंडबॉक्सिंग और नीति द्वारा शासित कुछ चीज़ के रूप में प्रस्तुत करता है। हुक्स के लिए दस्तावेज़ कहते हैं कि PreToolUse टूल कॉल्स को अनुमति दे सकता है, अस्वीकार कर सकता है, पूछ सकता है, या स्थगित कर सकता है और निष्पादन से पहले टूल इनपुट को भी संशोधित कर सकता है। हुक्स संदर्भ यह भी चेतावनी देता है कि कमांड हुक्स सिस्टम उपयोगकर्ता की पूर्ण अनुमति के साथ चलते हैं। उनकी सैंडबॉक्सिंग पोस्ट भी स्पष्ट रूप से कहती है कि प्रभावी सैंडबॉक्सिंग के लिए फ़ाइल सिस्टम पृथक्करण और नेटवर्क पृथक्करण दोनों आवश्यक हैं। नेटवर्क पृथक्करण के बिना, एक समझौता किया गया एजेंट संवेदनशील फ़ाइलों को बाहर भेज सकता है; फ़ाइल सिस्टम पृथक्करण के बिना, यह भाग सकता है और नेटवर्क एक्सेस फिर से हासिल कर सकता है। (क्लाउड एपीआई दस्तावेज़)
पेंटस्टिंग के लिए, इसका मतलब है कि हार्नेस को एक पॉलिसी कर्नेल की आवश्यकता होती है जो मॉडल के बाहर स्थित हो और यह तय करे कि क्या हो सकता है। एक उपयोगी पैटर्न है कि क्रियाओं को चार श्रेणियों में वर्गीकृत किया जाए।
स्वचालित क्रियाएँ कम-जोखिम वाली, दायरे में आने वाली पढ़ीं और सीमित जांचें हैं।
अनुमोदन-आधारित क्रियाएँ सक्रिय जाँचें हैं जो अपनी अवस्था बदल सकती हैं या शोर उत्पन्न कर सकती हैं।
स्थगित क्रियाएँ वैध जाँचें हैं जिनमें पहले किसी व्यक्ति से प्रश्न का उत्तर लेना आवश्यक होता है, जैसे कि क्या इस लक्ष्य के लिए कम प्रभाव वाला अपलोड परीक्षण स्वीकार्य है।
प्रतिबंधित कृत्य वह सब कुछ हैं जो अधिकृत दायरे से बाहर हैं।
एक छोटी पॉलिसी फ़ाइल इसे स्पष्ट रूप से व्यक्त कर सकती है:
नीतियाँ:
- नाम: निष्क्रिय-पठन
मिलान:
उपकरण: [पठन, वेबफ़ेच, ब्राउज़रनेविगेट]
लक्ष्य-दायरा: दायरे में
क्रिया-वर्ग: निष्क्रिय
निर्णय: अनुमति दें
- नाम: low-impact-api-validation
मैच:
टूल: [HttpRequest]
मेथड: [GET, HEAD]
टारगेट_स्कोप: in_scope
रेट_लिमिट_ओके: true
निर्णय: allow
- नाम: स्थिति-बदलने-वाली-जांच
मैच:
टूल: [HttpRequest, BrowserAction]
मेथड: [POST, PUT, PATCH, DELETE]
टारगेट_स्कोप: in_scope
निर्णय: स्थगित
प्रश्न: "यह क्रिया एप्लिकेशन की स्थिति बदल सकती है। अनुमोदित करें?"
- नाम: बाहरी-कॉलबैक
मैच:
गंतव्य_स्कोप: बाहरी
निर्णय: अस्वीकार करें
कारण: "स्कोप से बाहर का कॉलबैक इंफ्रास्ट्रक्चर अवरुद्ध है"
- नाम: शोषण-जैसी-कार्यवाही
मैच:
क्रिया_वर्ग: शोषण_प्रमाणीकरण
निर्णय: अस्वीकार करें
कारण: "शोषण-शैली की कार्यवाही इस संलग्नता प्रोफ़ाइल के बाहर है"
यहीं पर Anthropic का "deny-and-continue" विचार मूल्यवान हो जाता है। उनके सार्वजनिक विवरण के अनुसार ऑटो मोड में जब क्लासिफायर किसी क्रिया को ब्लॉक करता है, तो Claude को बस रुकना नहीं चाहिए; इसे पुनः ठीक होकर जहाँ संभव हो एक सुरक्षित मार्ग आज़माना चाहिए। एक पेनेटस्ट हार्नेस में इसका मतलब है कि अस्वीकृत विनाशकारी क्रिया को पूर्णतः रुकने के बजाय पैसिव कन्फर्मेशन, कोड-पाथ विश्लेषण, भूमिका तुलना या मानव एस्केलेशन पर वापस लौटना चाहिए।मानवजनित)
नीति निर्माण को भी MCP-विशिष्ट जोखिम को समझने की आवश्यकता है। आधिकारिक MCP सुरक्षा मार्गदर्शन सुरक्षा टीमों के लिए असामान्य रूप से प्रासंगिक है क्योंकि यह अस्पष्ट शब्दों में बात नहीं करता। यह confused deputy मुद्दों, टोकन पासथ्रू, SSRF, सत्र हाईजैकिंग, स्थानीय MCP सर्वर समझौता और स्कोप मिनिमाइज़ेशन को वास्तविक हमले की सतहों के रूप में नामित करता है। MCP प्राधिकरण विनिर्देश में दर्शक सत्यापन की भी आवश्यकता होती है और यह स्पष्ट रूप से उन टोकन दुरुपयोग पैटर्न को अस्वीकार करता है जो सेवाओं के बीच सुरक्षा सीमाओं को धुंधला कर देंगे।मॉडल संदर्भ प्रोटोकॉल)
एक पेनटेस्ट हार्नेस जो MCP टूल्स में प्लग होता है लेकिन टोकन ऑडियंस को स्वतंत्र रूप से सत्यापित नहीं करता, स्कोप मिनिमाइज़ेशन लागू नहीं करता, और अपस्ट्रीम तथा डाउनस्ट्रीम क्रेडेंशियल्स को अलग नहीं करता, वह रेत पर बन रहा है।
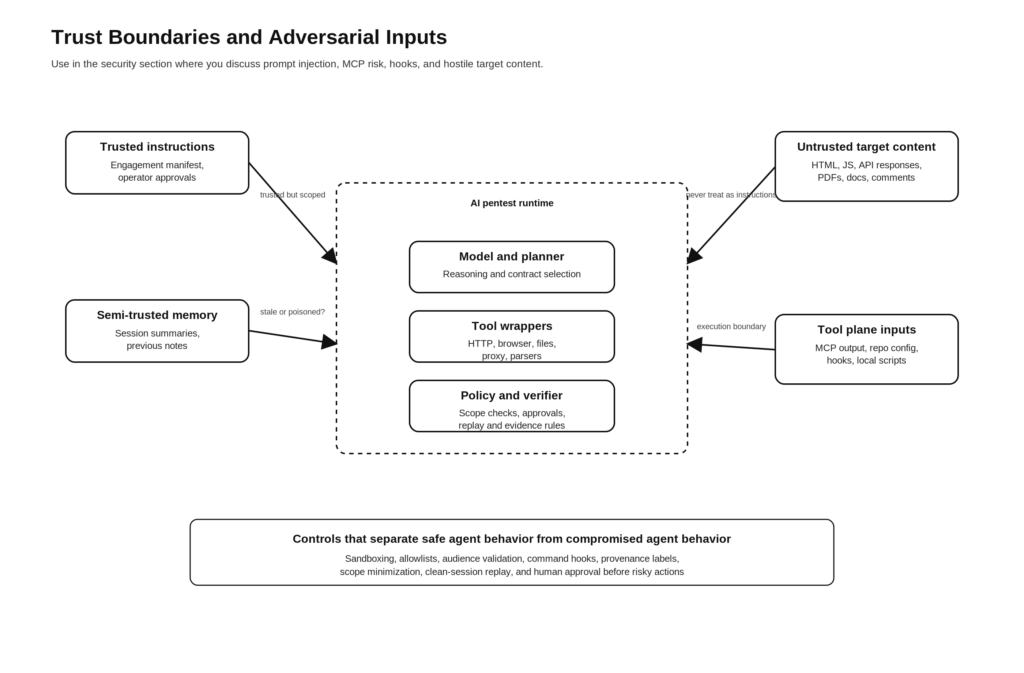
लक्ष्यों को प्रतिद्वंद्वी इनपुट्स के रूप में क्यों माना जाना चाहिए
एजेंटिक पेनेट्रेशन टेस्टिंग में लोग सबसे बड़ी गलती यह मान लेते हैं कि केवल लक्ष्य ही परीक्षण के दायरे में है। वास्तव में, हार्नेस से जुड़ी हर चीज़ एक संभावित हमला सतह बन सकती है।
Anthropic के ब्राउज़र प्रॉम्प्ट इंजेक्शन शोध में यह बात स्पष्ट रूप से कही गई है। जब कोई एजेंट इंटरनेट ब्राउज़ करता है, तो हर पेज एक संभावित हमले का मार्ग है। प्रॉम्प्ट इंजेक्शन एक बड़ी अनसुलझी चुनौती बनी हुई है, खासकर जब एजेंट वास्तविक दुनिया में कार्रवाई करते हैं, और Anthropic स्पष्ट रूप से कहता है कि बेहतर सुरक्षा उपायों के बावजूद यह समस्या हल नहीं हुई है। OWASP की GenAI सामग्री सामान्य शब्दों में यही बात कहती है: प्रॉम्प्ट इंजेक्शन संवेदनशील डेटा उजागर कर सकता है, फ़ंक्शंस तक अनधिकृत पहुँच प्रदान कर सकता है, जुड़े सिस्टम में कमांड निष्पादित कर सकता है, और निर्णय लेने में हेरफेर कर सकता है। अप्रत्यक्ष प्रॉम्प्ट इंजेक्शन विशेष रूप से तब प्रासंगिक होता है जब मॉडल पृष्ठों, दस्तावेज़ों या फ़ाइलों जैसे बाहरी डेटा का उपभोग करता है। (मानवजनित)
इसका सीधा प्रभाव एआई पेनेट्रेशन टेस्टिंग पर पड़ता है। लक्ष्य प्रतिक्रिया बॉडी सिर्फ डेटा नहीं है। एक जावास्क्रिप्ट बंडल, एक DOM नोड, एक PDF, एक टिप्पणी क्षेत्र या एक दस्तावेज़ पृष्ठ—ये सभी मॉडल को निर्देशित करने के लिए डिज़ाइन की गई निर्देशों से भरे हो सकते हैं। इसी तरह एक रिपॉजिटरी, एक README, एक टूल आउटपुट फ़ाइल या एक मॉक्ड API प्रतिक्रिया भी ऐसा कर सकती है। इसलिए हार्नेस को हर परत पर लक्ष्य को प्रतिद्वंद्वी इनपुट के रूप में मानना चाहिए।
यह आपके वर्कर्स को डिज़ाइन करने के तरीके को बदलता है। पुनःखोज वर्कर को मनमाने पेज की सामग्री को विश्वसनीय निर्देशों के रूप में पुनर्व्याख्या करने की अनुमति नहीं दी जानी चाहिए। प्रवाह मैपर को निकाले गए अवलोकनों को एजेंट निर्देशों से अलग रखना चाहिए। सत्यापनकर्ता को निष्पादक द्वारा प्रदान की गई टिप्पणी पर भरोसा नहीं करना चाहिए। साक्ष्य लेखक को यह अंशांकन करना चाहिए कि कलाकृतियाँ कहाँ से आईं और क्या वे विश्वसनीय या अविश्वसनीय स्रोतों से उत्पन्न हुई थीं। प्रॉम्प्ट इंजेक्शन कोई वैकल्पिक सीमा-स्थिति नहीं है। यह एजेंटिक परीक्षण के सामान्य खतरा मॉडल का हिस्सा है।मानवजनित)
यह उपकरणों के बारे में आपकी सोच को भी बदल देता है। MCP सुरक्षा मार्गदर्शिका केवल टोकन पर चर्चा नहीं करती। यह स्थानीय सर्वर समझौता और दायरे को न्यूनतम करने का उल्लेख करती है क्योंकि टूल प्लेन हमला सतह का हिस्सा है। इसी तरह, Anthropic का हुक्स दस्तावेज़ीकरण चेतावनी देता है कि कमांड हुक्स उपयोगकर्ता की पूरी अनुमति के साथ निष्पादित होते हैं। एक बार जब आप टूल एक्सेस, कमांड निष्पादन, ब्राउज़र एक्सेस, मेमोरी और रिपो-स्थानीय कॉन्फ़िगरेशन को मिलाते हैं, तो "डेटा" और "निष्पादन" के बीच की पुरानी रेखा धुंधली होने लगती है। (मॉडल संदर्भ प्रोटोकॉल)
इस पर तर्क करने का एक उपयोगी तरीका चार इनपुट क्लासेस का मॉडल तैयार करना है।
| इनपुट क्लास | उदाहरण | प्राथमिक जोखिम | आवश्यक नियंत्रण |
|---|---|---|---|
| विश्वसनीय निर्देश | प्रतिबद्धता प्रकट, ऑपरेटर अनुमोदन, नीति नियम | अत्यधिक व्यापक प्राधिकरण या पुरानी नीति | संस्करणबद्ध नीति, समीक्षा, परिवर्तन नियंत्रण |
| अर्ध-विश्वसनीय आंतरिक संदर्भ | नोट्स, हैंडऑफ़ सारांश, पूर्व साक्ष्य | स्मृति विषाक्तता, पुराने अनुमान | संरचित स्कीमा, उत्पत्ति टैग, समाप्ति |
| अविश्वसनीय लक्ष्य सामग्री | HTML, JS, दस्तावेज़, PDF, API प्रतिक्रियाएँ | अप्रत्यक्ष प्रॉम्प्ट इंजेक्शन, भ्रामक संकेत, झूठा प्रमाण | इनपुट लेबलिंग, सैंडबॉक्स में पार्सिंग, कोई निहित निर्देश पालन नहीं |
| टूल प्लेन सामग्री | एमसीपी आउटपुट, हुक इनपुट, रिपो कॉन्फ़िग, लोकल स्क्रिप्ट्स | कमांड निष्पादन, टोकन चोरी, भ्रमित उप-निरीक्षक, एसएसआरएफ | टूल अनुमति-सूची, दर्शक सत्यापन, कंटेनर पृथक्करण, रिपो विश्वसनीयता मॉडल |
यह तालिका एक संश्लेषण है, लेकिन यह Anthropic, OWASP और MCP के अपने आधिकारिक सुरक्षा मार्गदर्शन द्वारा दस्तावेजीकृत खतरे के पैटर्न का अनुसरण करती है।मानवजनित)
वे CVEs जो इस आर्किटेक्चर को वैकल्पिक नहीं बनाते
जब आप आसन्न एजेंट प्रणालियों में पहले से क्या हुआ है, देखते हैं, तो उच्च-स्तरीय डिज़ाइन बहुत कम अमूर्त हो जाता है।
Langflow CVE-2025-3248 और हानिरहित हेल्पर एंडपॉइंट्स की मिथक
NVD CVE-2025-3248 का वर्णन Langflow संस्करण 1.3.0 से पहले के संस्करणों में कोड इंजेक्शन समस्या के रूप में करता है। संवेदनशील एंडपॉइंट था /api/v1/validate/code, और इस खामी ने एक दूरस्थ, बिना प्रमाणीकरण वाले हमलावर को ऐसे तैयार किए गए अनुरोध भेजने की अनुमति दी, जो मनमाना कोड निष्पादित करते हैं। CISA ने बाद में इस मुद्दे को अपनी ज्ञात शोषित कमजोरियों (Known Exploited Vulnerabilities) कार्यधारा में शामिल कर लिया। (एनवीडी)
यह एक पेनटेस्ट हार्नेस लेख के लिए क्यों मायने रखता है? क्योंकि यह एक ऐसी विफलता का स्पष्ट उदाहरण है जिसे कई टीमें अभी भी कम आंकती हैं। AI वर्कफ़्लो उत्पाद अक्सर "हेल्पर" या "वैलिडेशन" पथ शामिल करते हैं जो मुख्य निष्पादन सतहों की बजाय सहायक फ़ंक्शन लगते हैं। व्यवहार में, जिसे "वैलिडेट" कहा जाता है, वही वह जगह हो सकती है जहाँ असुरक्षित निष्पादन होता है। एक हार्नेस आर्किटेक्ट को इससे दो सबक सीखने चाहिए। पहला, आंतरिक सहायक क्षमताओं को निष्पादन सीमाओं के रूप में थ्रेट-मॉडेल किया जाना चाहिए, न कि सुविधा सुविधाओं के रूप में। दूसरा, नीति और सत्यापन को स्पष्ट रूप से दिखाई देने वाले एंडपॉइंट्स की तरह ही सहायक एंडपॉइंट्स को भी उतनी ही आक्रामकता से कवर करना चाहिए। (एनवीडी)
रक्षा करने वालों के लिए, शमन की कहानी भी उतनी ही शिक्षाप्रद है। NVD स्थिर संस्करणों और विक्रेता संदर्भों की ओर इशारा करता है। आर्किटेक्चर स्तर पर, मरम्मत सिर्फ "add auth" नहीं है। यह यह भी है कि "यह मानना बंद करें कि कोड-प्रमाणीकरण सुविधाएँ हमलावर-नियंत्रित इनपुट्स को सुरक्षित रूप से संसाधित कर सकती हैं।" यह सिर्फ एक पैच नहीं, बल्कि एक डिज़ाइन सुधार है।एनवीडी)
Langflow CVE-2026-33017 और आंशिक सुधारों का खतरा
बाद का Langflow मुद्दा और भी अधिक खुलासा करता है। NVD CVE-2026-33017 को 1.9.0 से पहले के संस्करणों में एक अनाधिकृत दूरस्थ कोड निष्पादन दोष के रूप में वर्णित करता है। संवेदनशील एंडपॉइंट, POST /api/v1/build_public_tmp/{flow_id}/flow, सार्वजनिक फ्लो के लिए जानबूझकर प्रमाणीकरण रहित था, लेकिन हमलावर-नियंत्रित फ्लो डेटा जिसे नोड परिभाषाओं में मनमाना पाइथन कोड शामिल था, स्वीकार कर लिया और उसे पास कर दिया कार्यपालन करें() बिना किसी सैंडबॉक्सिंग के। NVD स्पष्ट रूप से उल्लेख करता है कि यह समस्या CVE-2025-3248 से अलग है। यह वही बग एक ही एंडपॉइंट पर फिर से उभरने की समस्या नहीं थी। यह व्यापक निष्पादन मॉडल कहीं और प्रकट हो रहा था। NVD यह भी दर्ज करता है कि यह खामी मार्च 2026 में CISA की ज्ञात शोषित कमजोरियों की सूची में शामिल हो गई।एनवीडी)
यह बिल्कुल वैसा ही सबक है जिसकी परवाह AI पेंटस्ट हार्नेस बनाने वालों को करनी चाहिए। एक सिस्टम एक खतरनाक एंडपॉइंट को ठीक कर सकता है और फिर भी कहीं और अंतर्निहित पैटर्न को बरकरार रख सकता है। यदि आपके हार्नेस में कई कोड पाथ हैं जो अविश्वसनीय डेटा को टूल इनवोकेशन, ब्राउज़र एक्शन, या शेल कमांड में बदल सकते हैं, तो सिर्फ एक सतह को पैच करना पर्याप्त नहीं है। आपको एक वास्तुशिल्प सीमा की आवश्यकता है। Anthropic की भाषा में, इसका मतलब है वास्तविक सैंडबॉक्सिंग और अनुमति परतें। पेंट-टेस्ट-हार्नेस की भाषा में, इसका मतलब है मॉडल के बाहर एक नीति कर्नेल और एक रनटाइम जो कभी भी "सार्वजनिक" या "सहायक" सतहों को स्वचालित रूप से कम जोखिम वाला नहीं मानता। (मानवजनित)
क्लाउड कोड रिपो-स्तर विन्यास संबंधी समस्याएँ और नई निष्पादन सीमा
क्लॉड कोड के लिए सबसे प्रासंगिक चेतावनी मामला फरवरी 2026 में चेक पॉइंट रिसर्च से आया था। उनके लेख में कहा गया है कि दुर्भावनापूर्ण प्रोजेक्ट कॉन्फ़िगरेशन हुक्स, MCP इंटीग्रेशन और एनवायरनमेंट वेरिएबल्स का दुरुपयोग करके रिमोट कोड एक्ज़ीक्यूशन और API क्रेडेंशियल चोरी कर सकते हैं, जब उपयोगकर्ता अविश्वसनीय रिपॉजिटरीज़ को क्लोन करके खोलते हैं। उनका सारांश बताता है कि प्रकाशन से पहले इन समस्याओं को पैच कर दिया गया था, लेकिन वास्तुशिल्प संबंधी सबक पैच से कहीं बड़ा है। वे तर्क देते हैं कि रिपॉजिटरी-स्तर की कॉन्फ़िगरेशन फ़ाइलें हानिरहित परिचालन मेटाडेटा के बजाय एक सक्रिय निष्पादन परत बन गईं। चेक पॉइंट ने इस शोध को CVE-2025-59536 और CVE-2026-21852 से जोड़ा। (चेक पॉइंट रिसर्च)
यह निष्कर्ष अंथ्रोपिक की अपनी ही दस्तावेज़ीकरण के साथ असहज रूप से मेल खाता है। हुक्स संदर्भ कहता है कि कमांड हुक्स सिस्टम उपयोगकर्ता की पूरी अनुमति के साथ चलते हैं। सैंडबॉक्सिंग पोस्ट कहती है कि प्रभावी सुरक्षा के लिए फ़ाइल सिस्टम और नेटवर्क दोनों का पृथक्करण आवश्यक है। इन दोनों को मिलाकर देखें तो निहितार्थ स्पष्ट है: एक बार जब कोई एजेंटिक टूल फ़ाइलें पढ़ सकता है, कमांड चला सकता है, टूल्स को जोड़ सकता है, और प्रोजेक्ट-स्थानीय कॉन्फ़िगरेशन लोड कर सकता है, तो रिपॉजिटरी की सामग्री निष्पादन सीमा का हिस्सा बन जाती है।क्लाउड एपीआई दस्तावेज़)
AI पेंटस्टिंग के लिए, यह दो कारणों से महत्वपूर्ण है। पहला, आपका हार्नेस अक्सर अविश्वसनीय लक्ष्यों, अविश्वसनीय रिपॉजिटरी, अविश्वसनीय दस्तावेज़ों या अविश्वसनीय ब्राउज़र सामग्री के साथ इंटरैक्ट करेगा। दूसरा, पेनेटस्टिंग टीमें अक्सर स्थानीय स्क्रिप्ट्स, प्रॉक्सी इंटीग्रेशन, MCP सर्वर और प्रोजेक्ट-विशिष्ट ऑटोमेशन को एक साथ जोड़ती हैं। इसका मतलब है कि एक खराब डिज़ाइन किया गया हार्नेस उसी इकोसिस्टम द्वारा हमला किया जा सकता है जिसका वह दूसरों का परीक्षण करने के लिए उपयोग कर रहा है। यदि आप Claude Code मामले से एक सबक सीखना चाहें, तो वह यह है: कॉन्फ़िगरेशन रनटाइम का हिस्सा है। इसे उसी तरह थ्रेट-मॉडल करें।
व्यावहारिक रूप से इन मामलों का क्या मतलब है
उपरोक्त तीनों उदाहरण एक साझा निष्कर्ष की ओर इशारा करते हैं। एजेंट-आधारित प्रणालियों में जोखिम केवल यह नहीं है कि मॉडल गलत तर्क करेगा। असली जोखिम यह है कि हार्नेस के किसी भाग में चलने वाला निष्पादन पथ अविश्वसनीय इनपुट को इस तरह स्वीकार कर ले जैसे इसे चलाना, अधिकृत करना या उस पर भरोसा करना सुरक्षित हो।
यही कारण है कि छह-परत वाला डिज़ाइन कोई औपचारिकता नहीं है। एंगेजमेंट प्लेन आकस्मिक अतिशयोक्ति को रोकता है। हाइपोथिसिस कंपाइलर निष्पादन को सीमित करता है। वर्कर विशेषज्ञता विशेषाधिकार के प्रसार को कम करती है। वेरिफायर झूठे प्रमाण को दबा देता है। स्थायी मेमोरी स्थिति के नुकसान को कथा भटकाव बनने से रोकती है। नीति कर्नेल टूल प्लेन को बाहरी नियंत्रण में रखता है। इन परतों के बिना, आप प्रतिद्वंद्वी परिस्थितियों में एक मॉडल के सुसंगत और भलाइयांकारी बने रहने पर पेंटस्ट वर्कफ़्लो की अखंडता दांव पर लगा रहे हैं। सार्वजनिक रिकॉर्ड पहले से ही कहता है कि यह पर्याप्त नहीं है। (एनवीडी)
सबूत-प्रथम एआई पेनटेस्ट हार्नेस के लिए संदर्भ वास्तुकला
पूरे सिस्टम को संक्षिप्त रूप में दर्शाया जा सकता है:
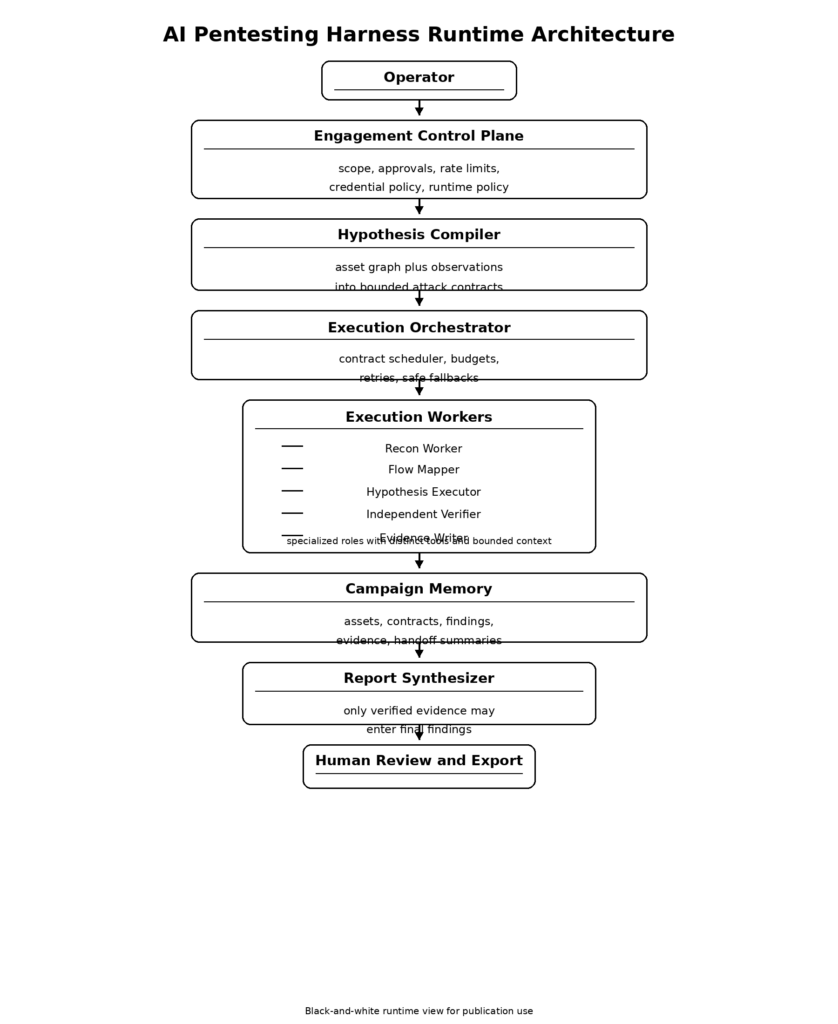
इस आकार के काम करने के दो कारण हैं।
पहला यह है कि यह वास्तविक परीक्षण के क्रम से मेल खाता है। Recon संभावनाएँ उत्पन्न करता है। Flow विश्लेषण संभावनाओं को हमलों के विचारों में बदलता है। Execution एक समय में एक सीमित विचार का परीक्षण करता है। Verification यह तय करता है कि परिणाम पर भरोसा किया जा सकता है या नहीं। Reporting केवल उसके बाद होती है। NIST SP 800-115 और OWASP WSTG बहुत अलग दस्तावेज़ हैं, लेकिन दोनों इस बात को पुष्ट करते हैं कि परीक्षण एक प्रक्रिया है, न कि किसी उपकरण के एकल चरण का परिणाम।एनआईएसटी सीएसआरसी)
दूसरा यह है कि यह एजेंट्स के बारे में एंथ्रोपिक के सार्वजनिक अवलोकनों से मेल खाता है। लंबे कार्य तब बेहतर होते हैं जब काम को विभाजित किया जाता है, जब हैंडऑफ़ आर्टिफैक्ट्स स्थिति को संरक्षित करते हैं, और जब एक संशयवादी मूल्यांकनकर्ता जनरेटर के बाहर बैठता है। विशेषज्ञ सहायक संदर्भ प्रबंधन में सुधार करते हैं। सत्यापन मानदंड परिणामों में सुधार करते हैं। सैंडबॉक्सिंग और नीति सीमाएँ स्वायत्तता को अधिक सुरक्षित बनाती हैं।मानवजनित)
इस प्रणाली का एक मजबूत पहला संस्करण स्वायत्त शोषण की आवश्यकता नहीं रखता। इसे अनुशासित प्रगति की आवश्यकता है। न्यूनतम व्यवहार्य हार्नेस को सक्षम होना चाहिए:
- दायरा और नीति
- एक एसेट ग्राफ़ बनाएँ,
- एक समय में एक अनुबंध संकलित करें,
- सीमित जाँचें करें,
- उन्हें स्वतंत्र रूप से चलाएँ,
- साक्ष्य बनाए रखें
- और एक रिपोर्ट करने योग्य आर्टिफैक्ट निर्यात करें।
यह वास्तुकला साबित करने के लिए पर्याप्त है, इससे पहले कि आप और साहसी व्यवहार जोड़ें।
डेटा मॉडल, परिसंपत्ति ग्राफ़, हमला अनुबंध, साक्ष्य बंडल
इस प्रकार की प्रणाली में सबसे महत्वपूर्ण इंजीनियरिंग निर्णय यह है कि सब कुछ फ्री-फॉर्म चैट पर केंद्रित करना बंद कर दिया जाए और सब कुछ डेटा ऑब्जेक्ट्स पर केंद्रित किया जाए।
पहली वस्तु एसेट ग्राफ़ है। यह केवल URL की सूची नहीं है। यह डोमेन, एंडपॉइंट, पैरामीटर, कुकीज़, हेडर, पहचान, भूमिकाएँ, जावास्क्रिप्ट रूट्स, ऑब्जेक्ट स्टोर्स, एडमिन सतहों और उनके बीच देखे गए संक्रमणों का ग्राफ़ है। इसका उद्देश्य केवल दृश्यांकन नहीं है। इसका उद्देश्य हार्नेस को मशीन-उपयोगी मॉडल प्रदान करना है, जिसमें विश्वास की सीमाएँ और हमले के मार्ग कहाँ हो सकते हैं।
एक सरलीकृत स्कीमा इस प्रकार दिख सकती है:
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class AssetNode:
id: str
type: str
labels: List[str]
attributes: Dict[str, str] = field(default_factory=dict)
@dataclass
class AssetEdge:
source: str
target: str
relation: str
evidence_refs: List[str] = field(default_factory=list)
दूसरी वस्तु अटैक कॉन्ट्रैक्ट है। यह कार्य की इकाई और मूल्यांकन की इकाई है। इसे टिकाऊ, टाइप्ड, पुनः आरंभ करने योग्य और ऑडिट करने योग्य होना चाहिए। यदि सिस्टम आपको यह नहीं बता सकता कि वह कौन सा कॉन्ट्रैक्ट निष्पादित कर रहा है, सफलता का क्या अर्थ है, और किन साक्ष्यों की आवश्यकता है, तो यह अभी भी पेंटस्ट हार्नेस के बजाय संवादात्मक एजेंट के रूप में काम कर रहा है।
तीसरी वस्तु साक्ष्य बंडल है। यही वह है जिससे एक रिपोर्ट योग्य निष्कर्ष तैयार होता है। न तो कोई अनुच्छेद। न ही कोई सारांश। एक बंडल।
{
"finding_id": "idor-orders-001",
"status": "verified",
"severity_candidate": "high",
"contracts": ["idor-orders-001"],
"artifacts": {
"requests": ["req-1.json", "req-2.json"],
"responses": ["res-1.json", "res-2.json"],
"screenshots": ["browser-1.png"],
"har": ["session-a.har"],
"logs": ["verifier-notes.md"]
},
"reproduction": {
"identities": ["user_a", "user_b"],
"steps": [
"user_a के रूप में लॉगिन करें",
"ऑर्डर आईडी कैप्चर करें",
"user_b के रूप में लॉगिन करें",
"user_a ऑर्डर आईडी के खिलाफ GET को रिप्ले करें"
],
"negative_case": "यादृच्छिक गैर-मौजूद आईडी 404 लौटाता है"
},
"विश्वास": "उच्च",
"समीक्षा_आवश्यक": true
}
यहीं पर एक और संयमित उत्पाद अवलोकन स्वाभाविक रूप से फिट बैठता है। हाल ही में Penligent द्वारा Claude को पेनटेस्ट कोपायलट के रूप में प्रस्तुत सामग्री एक ऐसा तर्क देती है जिससे ब्रांड को पूरी तरह हटा देने पर भी सहमत होना आसान है: एक मजबूत सिस्टम को संपादन योग्य रिपोर्टिंग, पुनरुत्पादित प्रूफ-ऑफ-कॉन्सेप्ट सामग्री, और सत्यापित निष्कर्षों पर जोर देना चाहिए, न कि अप्रमाणित AI कथावाचन पर। सार्वजनिक वर्कफ़्लो-नेटिव पेनटेस्ट प्लेटफ़ॉर्म जो इन आउटपुट्स को केंद्र में रखते हैं, समस्या के सही छोर पर ध्यान केंद्रित कर रहे हैं। कठिन हिस्सा किसी मॉडल को स्मार्ट लगने वाला बनाना नहीं है। यह वर्कफ़्लो को इतना सत्य बनाए रखने के लिए है कि कोई और इसे फिर से चला सके। (पेनलिजेंट)
अमलीकरण पैटर्न और कोड
मुख्य ऑर्केस्ट्रेटर लॉजिक रहस्यमयी होने की आवश्यकता नहीं है। इसे केवल अनुशासित होना चाहिए।
एक न्यूनतम लूप इस प्रकार काम कर सकता है:
`run_campaign(campaign)` फ़ंक्शन:
जब तक `True` है:
`contract = campaign.next_ready_contract()`
अगर `contract` `None` है:
`break`
अगर `campaign.policy.allows(contract)` नहीं है:
`campaign.defer(contract, reason="policy gate")`
`continue`
`execution_result = campaign.executor.run(contract)`
if execution_result.status == "rejected":
campaign.record_rejection(contract, execution_result)
continue
verification_result = campaign.verifier.run(contract, execution_result)
if verification_result.status == "verified":
bundle = campaign.evidence_writer.build_bundle(
contract, execution_result, verification_result
)
campaign.promote_finding(contract, bundle)
elif verification_result.status == "needs_review":
campaign.queue_human_review(contract, verification_result)
else:
campaign.record_rejection(contract, verification_result)
campaign.write_handoff()
महत्वपूर्ण सिंटैक्स नहीं है। यह संरचना है। लूप प्रत्येक उम्मीदवार को एक ही क्रम से गुज़रने के लिए मजबूर करता है: अनुसूची, नीति, निष्पादन, सत्यापन, निरंतरता। यह पैटर्न एंथ्रोपिक के जनरेटर-मूल्यांकन लूप और उनके सत्यापन मानदंडों पर जोर देने का आक्रामक-सुरक्षा अनुवाद है।मानवजनित)
प्रमाणीकरणकर्ता स्पष्ट केस जेनरेशन के साथ पुनरावृत्ति अनुशासन को भी लागू कर सकता है:
`build_replay_cases(contract, candidate)` फ़ंक्शन:
`cases` = []
`identity` `contract["required_identities"]` में से प्रत्येक के लिए:
cases.append({
"name": f"{contract['contract_id']}-{identity}-clean",
"session_profile": identity,
"request_spec": candidate["request_spec"],
"expected_signal": candidate["expected_signal"]
})
if contract.get("negative_case"):
cases.append({
"name": f"{contract['contract_id']}-negative",
"session_profile": contract["negative_case"]["identity"],
"request_spec": contract["negative_case"]["request_spec"],
"expected_signal": contract["negative_case"]["expected_signal"]
})
return cases
एक ब्राउज़र-जागरूक सत्यापक तब DOM स्नैपशॉट या स्क्रीनशॉट को सहायक साक्ष्य के रूप में जोड़ सकता है, जो अवधारणात्मक रूप से उसी तरह है जैसे Anthropic के मूल्यांकनकर्ता ने केवल स्थिर आउटपुट पर निर्भर रहने के बजाय चल रहे एप्लिकेशन की जाँच के लिए Playwright का उपयोग किया था।मानवजनित)
अंततः, पॉलिसी इंजन प्रॉम्प्ट्स के अंदर रहने के बजाय टूल रैपर के पीछे रह सकता है:
def guarded_http_request(policy, request):
decision = policy.evaluate_http(request)
if decision.kind == "deny":
raise PermissionError(decision.reason)
if decision.kind == "defer":
raise RuntimeError("मानवीय अनुमोदन आवश्यक है")
return send_http(request)
वह एक विकल्प दिखने से कहीं अधिक महत्वपूर्ण है। यदि मॉडल केवल दायरे का सम्मान करने का "वादा" कर सकता है लेकिन रनटाइम इसे लागू नहीं कर सकता, तो हार्नेस स्वभावतः नाजुक है।
केवल मॉडल का ही नहीं, बल्कि हार्नेस का भी मूल्यांकन
Anthropic का "Demystifying evals for AI agents" सीधे इस बात पर जोर देता है: जब आप किसी एजेंट का मूल्यांकन करते हैं, तो आप हार्नेस और मॉडल को एक साथ काम करते हुए आंका जाता है। यह AI पेनेटस्टिंग के लिए भी एक मूलभूत धारणा होनी चाहिए।मानवजनित)
गलत मूल्यांकन प्रश्न है "क्या मॉडल ने सही अगला कदम सुझाया?" सही मूल्यांकन प्रश्न इनके करीब हैं:
| मेट्रिक | यह क्यों मायने रखती है |
|---|---|
| संविदा पूर्णता दर | यह दर्शाता है कि हार्नेस अवलोकनों को तैयार परीक्षण इकाइयों में परिवर्तित कर सकता है या नहीं। |
| सत्यापन उत्तीर्ण दर | स्वतंत्र पुनःप्रसारण में कितने उम्मीदवार मुद्दे बचे रहते हैं, इसकी माप करता है। |
| झूठी-सकारात्मक दमन दर | दिखाता है कि सत्यापक वास्तविक कार्य कर रहा है या नहीं |
| साक्ष्य पूर्णता | यह मापता है कि निष्कर्ष वास्तव में रिपोर्ट करने योग्य हैं या नहीं। |
| नीति उल्लंघन दर | असुरक्षित या दायरे से बाहर के व्यवहार को प्रकट करता है। |
| मानवीय वृद्धि दर | स्वायत्तता बनाम निगरानी को समायोजित करने में मदद करता है। |
| सफलता दर | परीक्षण करता है कि लंबी अभियानों में रुकावट के बाद भी वे जारी रहते हैं या नहीं। |
| पैच पुनः परीक्षण सटीकता | यह मापता है कि क्या सिस्टम बिना विचलित हुए सुधारों को मान्य कर सकता है। |
यह तालिका किसी स्रोत से ली गई नहीं है, बल्कि वास्तुशिल्पीय है, लेकिन यह सीधे तौर पर Anthropic के मूल्यांकन ढांचे और NIST SP 800-115 तथा OWASP WSTG जैसे मानकों द्वारा वास्तविक परीक्षण कार्य से अपेक्षित मानदंडों से उपजी है। एक ऐसी प्रणाली जो कई संभावित हिट्स देती है लेकिन कमजोर साक्ष्य और बार-बार नीति उल्लंघन उत्पन्न करती है, वह धीमी प्रणाली से बेहतर नहीं है जिसमें कम, अधिक स्पष्ट और पुन:प्रयोग योग्य निष्कर्ष होते हैं।मानवजनित)
PentestGPT की बेंचमार्क पद्धति यहाँ भी उपयोगी है क्योंकि इसने प्रदर्शन को केवल एक अंतिम बाइनरी एक्सप्लॉइट परिणाम तक सीमित नहीं किया। यह पेपर उप-कार्य प्रगति और क्रमिक उपलब्धि पर जोर देता है। यह मूल्यांकन के लिए एक अच्छा दृष्टिकोण है। एक अभियान को सटीक संपत्ति मैपिंग, सही परिकल्पना खंडन, और विश्वसनीय नकारात्मक-मामलों के निपटान के लिए श्रेय मिलना चाहिए, न कि केवल "एक्सप्लॉइट मिला" क्षणों के लिए।arXiv)
सामान्य विफलता के तरीके
अधिकांश एआई पेनेटस्ट सिस्टम इसलिए विफल नहीं होते कि मॉडल बहुत कमजोर हो। वे इसलिए विफल होते हैं क्योंकि आर्किटेक्चर गलत चीज़ को सफलता के रूप में गिनने देता है।
एक सामान्य विफलता यह है कि एक ही कर्मचारी को निष्पादन और सत्यापन करने दिया जाए। एंथ्रोपिक के सार्वजनिक कार्यों से पता चलता है कि लंबे समय तक चलने वाले हार्नेस में, जनरेटर की तुलना में मूल्यांकनकर्ताओं को संशयवाद की ओर ट्यून करना आसान होता है। पेनेटस्टिंग में, इन भूमिकाओं को मिलाना आत्मविश्वास बढ़ाने का निमंत्रण है।मानवजनित)
एक और विफलता मेमोरी को नीति के रूप में मान लेना है। Anthropic का ट्रस्टवर्थी-एजेंट फ्रेमवर्क इस बात पर जोर देता है कि मनुष्यों को नियंत्रण बनाए रखना चाहिए और अनुमतियाँ मायने रखती हैं। मेमोरी निरंतरता में मदद करती है, लेकिन मेमोरी दायरा लागू नहीं करती। यदि आपका एकमात्र दायरा नियंत्रण वह नोट है जिसे मॉडल ने पहले पढ़ा था, तो आपके पास दायरा नियंत्रण नहीं है।मानवजनित)
तीसरी विफलता है बहुत जल्दी व्यापक शेल या नेटवर्क एक्सेस देना। Anthropic की अपनी सैंडबॉक्सिंग सामग्री स्पष्ट रूप से कहती है कि फ़ाइल सिस्टम और नेटवर्क पृथक्करण दोनों महत्वपूर्ण हैं। हुक्स दस्तावेज़ भी उतने ही स्पष्ट हैं कि कमांड हुक्स सिस्टम उपयोगकर्ता की पूरी अनुमति के साथ चलते हैं। यदि एक पेनेटस्ट हार्नेस पूरी विशेषाधिकार प्राप्त शेल और वैश्विक नेटवर्क पथ के साथ शुरू होता है, तो वह समस्या का हिस्सा बनने से केवल एक समझौता किया गया इनपुट दूर है।मानवजनित)
चौथी विफलता यह है कि सबूतों के बंडलों के बजाय एजेंट के वर्णन से रिपोर्ट लिखी जाती है। यह पेशेवर दिखने वाले झूठे सकारात्मक परिणामों का सबसे त्वरित मार्ग है। भाषा मॉडल जितना अधिक परिष्कृत होगा, यह उतना ही अधिक खतरनाक हो जाता है, क्योंकि रिपोर्ट पढ़ने में निश्चितता जैसा लगता है, भले ही अंतर्निहित प्रमाण कमजोर हों।
पाँचवां भ्रम यह मानना है कि प्रॉम्प्ट इंजेक्शन मुख्यतः कंज्यूमर चैटबॉट्स या ब्राउज़र असिस्टेंट्स की समस्या है। Anthropic के ब्राउज़र-उपयोग अनुसंधान और OWASP की प्रॉम्प्ट इंजेक्शन सामग्री इसके विपरीत कहती है। कोई भी सिस्टम जो अविश्वसनीय सामग्री का उपभोग करता है और जुड़े उपकरणों पर कार्रवाई कर सकता है, दायरे में आता है। एक AI पेंटस्ट हार्नेस ठीक उसी दुनिया में मौजूद है।मानवजनित)
एक परिपक्व परिचालन मॉडल कैसा दिखता है
एक परिपक्व एआई पेनेटस्ट हार्नेस मानव को मिटाने की कोशिश नहीं करता। यह वहाँ बदलाव करता है जहाँ मानव की भूमिका सबसे अधिक मायने रखती है।
Anthropic का सार्वजनिक विश्वसनीय-एजेंट फ्रेमवर्क इसे इस तरह से परिभाषित करता है कि यह एजेंट स्वायत्तता को सक्षम करते हुए भी मनुष्यों को नियंत्रण में रखता है। यह ठीक उसी तरह पेनेटस्टिंग से मेल खाता है। मनुष्य को हर हेडर को हर रिप्ले अनुरोध में मैन्युअल रूप से कॉपी नहीं करना चाहिए। मनुष्य को यह तय करना चाहिए कि कौन सी जोखिम श्रेणी की कार्रवाई स्वीकार्य है, क्या रिपोर्ट करने योग्य परिणाम माना जाएगा, और कब कोई संभावित परिणाम इतना महत्वपूर्ण होता है कि उसे उच्च स्तर पर भेजा जाए।मानवजनित)
व्यवहार में, एक परिपक्व संचालन मॉडल आमतौर पर इस तरह दिखता है।
ऑपरेटर मैनिफेस्ट और लक्ष्य सेट को अनुमोदित करता है।
हार्नेस केवल-पठन पुनर्प्राप्ति करता है और पहला एसेट ग्राफ़ बनाता है।
परिकल्पना संकलक सीमित अनुबंध उत्पन्न करता है।
कार्यकारी कर्मचारी स्वचालित रूप से कम-जोखिम की जाँच करते हैं।
प्रमाणीकरणकर्ता केवल स्वतंत्र रूप से पुनरुत्पादित किए जा सकने वाले परिणामों को बढ़ावा देता है।
उच्च-जोखिम परीक्षण ऑपरेटर की मंजूरी के लिए स्थगित कर दिए गए हैं।
रिपोर्ट को पोषित करते हैं साक्ष्य संकलन, न कि वर्णन।
सुधार के बाद, उन्हीं अनुबंधों को प्रतिगमन परीक्षण के लिए पुनः चलाया जाता है।
यह ऑपरेटिंग मॉडल एक पक्ष चुनने के बजाय टूल्स को संयोजित करना भी आसान बनाता है। Claude Code, Anthropic की अपनी दस्तावेज़ों के अनुसार, रिपो-अवेयर रीज़निंग, लोकल टूलिंग, और लचीले सबएजेंट वर्कफ़्लो के लिए एक मजबूत, नियंत्रित वर्कबेंच है। वर्कफ़्लो-नेटिव पेनटेस्ट सिस्टम, जिनमें Penligent भी शामिल है, सार्वजनिक दस्तावेज़ों में, लक्ष्य-सामना सत्यापन, प्रमाण संरक्षण, और रिपोर्ट पैकेजिंग के इर्द-गिर्द अनुकूलित होते हैं। परिपक्व दृष्टिकोण उन कार्यों को भ्रमित नहीं करना है। यह समझना है कि प्रत्येक कहाँ संबंधित है। (क्लाउड एपीआई दस्तावेज़)
चक्र पूरा करना
क्लॉड कोड का एआई पेनेट्रेशन टेस्टिंग में सबसे उपयोगी योगदान कमांड्स का एक बैग नहीं है। यह एजेंट्स को प्रणालियों के रूप में सोचने का एक तरीका है।
Anthropic के सार्वजनिक हार्नेस कार्य से पता चलता है कि जब संदर्भ को जानबूझकर प्रबंधित किया जाता है, कार्य को विभाजित किया जाता है, मूल्यांकनकर्ताओं को अलग किया जाता है, और सफलता को ठोस परीक्षणों से जोड़ा जाता है, तो लंबे कार्य बेहतर होते हैं। PentestGPT कहता है कि स्वचालित पेनेटस्टिंग तब बेहतर होती है जब संदर्भ हानि को प्रॉम्प्ट समस्या के बजाय एक डिज़ाइन समस्या के रूप में लिया जाता है। NIST और OWASP हमें याद दिलाते हैं कि सुरक्षा परीक्षण एक अनुशासित प्रक्रिया है जिसमें योजना, निष्पादन, विश्लेषण और रिपोर्टिंग शामिल हैं, न कि अनुमानों का एक चतुर क्रम। Langflow में वास्तविक CVEs और Claude Code के अपने रेपो-स्तर के निष्पादन सतह पर वास्तविक शोध यह दर्शाता है कि जब एजेंटिक प्रणालियाँ सुविधा और नियंत्रण के बीच की रेखा को धुंधला करती हैं तो क्या होता है। (मानवजनित)
तो सही महत्वाकांक्षा यह नहीं है कि "मॉडल को अधिक स्वायत्त महसूस कराएं।" सही महत्वाकांक्षा एक ऐसा हार्नेस बनाने की है जो स्थिति को बनाए रख सके, दायरे को संरक्षित रख सके, योजना को क्रिया से अलग कर सके, क्रिया को सत्यापन से अलग कर सके, और साक्ष्य को वर्णन से अलग कर सके।
यही अंतर है एक ऐसे एआई के बीच जो पेनेट्रेशन टेस्टिंग में मदद करता है और एक ऐसे पेनेट्रेशन टेस्ट वर्कफ़्लो के बीच जिस पर वास्तव में भरोसा किया जा सकता है।
अधिक पठन और संदर्भ
- एन्थ्रोपिक, दीर्घकालिक एजेंटों के लिए प्रभावी हार्नेस। (मानवजनित)
- एन्थ्रोपिक, लंबे समय तक चलने वाले अनुप्रयोग विकास के लिए हार्नेस डिज़ाइन। (मानवजनित)
- एन्थ्रोपिक, एआई एजेंट्स के लिए मूल्यांकनों को सुलभ बनाना।मानवजनित)
- एन्थ्रोपिक, एजेंट SDK अवलोकन। (क्लाउड एपीआई दस्तावेज़)
- एन्थ्रोपिक, क्लॉड कोड के लिए सर्वोत्तम प्रथाएँ। (क्लॉड)
- एन्थ्रोपिक, कस्टम उप-एजेंट बनाएँ। (क्लाउड एपीआई दस्तावेज़)
- एंट्रॉपिक, हुक्स संदर्भ। (क्लाउड एपीआई दस्तावेज़)
- एन्थ्रोपिक, अनुमति प्रॉम्प्ट्स से परे, क्लॉड कोड को अधिक सुरक्षित और स्वायत्त बनाना।मानवजनित)
- एन्थ्रोपिक, क्लॉड कोड ऑटो मोड, अनुमतियों को छोड़ने का एक सुरक्षित तरीका।मानवजनित)
- एन्थ्रोपिक, ब्राउज़र उपयोग में प्रॉम्प्ट इंजेक्शन के जोखिम को कम करना। (मानवजनित)
- पेंटस्टजीपीटी, यूज़निक्स सिक्योरिटी 2024 प्रस्तुति। (यूज़ेनिक्स)
- PentestGPT पेपर, arXiv HTML संस्करण। (arXiv)
- NIST SP 800-115, सूचना सुरक्षा परीक्षण और मूल्यांकन के लिए तकनीकी मार्गदर्शिका। (एनआईएसटी सीएसआरसी)
- OWASP वेब सुरक्षा परीक्षण गाइड। (ओवास्प)
- OWASP एआई परीक्षण गाइड। (ओवास्प)
- OWASP एजेंटिक सुरक्षा पहल और एजेंटिक अनुप्रयोगों के लिए शीर्ष 10 2026। (OWASP जेन एआई सुरक्षा परियोजना)
- OWASP LLM01 प्रॉम्प्ट इंजेक्शन। (OWASP जेन एआई सुरक्षा परियोजना)
- मॉडल संदर्भ प्रोटोकॉल, सुरक्षा सर्वोत्तम प्रथाएँ। (मॉडल संदर्भ प्रोटोकॉल)
- मॉडल संदर्भ प्रोटोकॉल, प्राधिकरण विनिर्देश। (मॉडल संदर्भ प्रोटोकॉल)
- एनवीडी, सीवीई-2025-3248।एनवीडी)
- एनवीडी, सीवीई-2026-33017।एनवीडी)
- CVE-2026-33017 के लिए लैंगफ्लो गिटहब एडवाइजरी। (गिटहब)
- चेक पॉइंट रिसर्च, Caught in the Hook, Claude Code प्रोजेक्ट फ़ाइलों के माध्यम से RCE और API टोकन की चोरी। (चेक पॉइंट रिसर्च)
- चेक पॉइंट रिसर्च, क्लॉड कोड की कमियों का सारांश। (चेक पॉइंट ब्लॉग)
- एआई पेनटेस्ट टूल, 2026 में वास्तविक स्वचालित आक्रमण कैसा दिखता है।पेनलिजेंट)
- एआई पेंटस्ट कॉपायलट, स्मार्ट सुझावों से सत्यापित निष्कर्षों तक।पेनलिजेंट)
- पेंटस्ट कॉपायलट के लिए क्लॉड एआई, क्लॉड कोड के साथ सबूत-प्रथम वर्कफ़्लो का निर्माण।पेनलिजेंट)
- क्लाउड कोड पेनटेस्टिंग बनाम पेनलिजेंट के लिए, जहाँ एक कोडिंग एजेंट रुकता है और एक पेनटेस्ट वर्कफ़्लो शुरू होता है।पेनलिजेंट)
- क्लाउड कोड सुरक्षा और पेनलिजेंट, व्हाइट-बॉक्स निष्कर्षों से ब्लैक-बॉक्स प्रमाण तक।पेनलिजेंट)
- पेनलिजेंट होमपेज। (पेनलिजेंट)

