El Código Claude es más fácil de malinterpretar cuando la gente lo trata como un mejor prompt box con acceso shell. El propio material público de Anthropic describe algo más específico. Un arnés, o andamio, es el sistema que permite a un modelo actuar como un agente procesando entradas, orquestando llamadas a herramientas, gestionando el contexto y devolviendo resultados. Anthropic es explícito en que cuando se evalúa un agente, se está evaluando el arnés y el modelo juntos, no el modelo aislado. Su SDK de agentes está enmarcado de la misma manera: Claude Code como una biblioteca programable con las mismas herramientas, bucle de agente y gestión de contexto que el propio Claude Code. (Antrópico)
Esa distinción importa más en la seguridad ofensiva que en casi cualquier otro ámbito de aplicación. Las pruebas de penetración no son un problema de charla. Es un problema de planificación, un problema de gestión de estados, un problema de verificación, un problema de informes y un problema de seguridad al mismo tiempo. NIST SP 800-115 define las pruebas técnicas como un proceso que incluye la planificación, la realización de pruebas, el análisis de los resultados y el desarrollo de estrategias de mitigación. La Guía de Pruebas de Seguridad Web de la OWASP sigue tratando las pruebas web como una disciplina amplia que abarca la recopilación de información, la autenticación, la autorización, la gestión de sesiones, la validación de entradas, la lógica empresarial y las pruebas de API. La Guía de Pruebas de IA de OWASP, publicada a finales de 2025, extiende esa mentalidad a las pruebas de fiabilidad de los sistemas de IA. (NIST CSRC)
El documento PentestGPT planteaba la misma cuestión desde el punto de vista de la investigación. Sus autores descubrieron que los grandes modelos lingüísticos solían ser buenos en subtareas como el uso de herramientas de seguridad, la interpretación de resultados y la propuesta de próximas acciones, pero tenían dificultades para mantener todo el contexto de la prueba a lo largo del tiempo. Su respuesta no fue una indicación más larga. Se trataba de una arquitectura tripartita con módulos separados para el razonamiento, la generación y el análisis sintáctico, diseñada específicamente para mitigar la pérdida de contexto. (arXiv)
Ahí es donde la idea del arnés de Claude Code resulta útil para el pentesting de IA. La lección más importante no es que un agente de codificación pueda ejecutar comandos. Muchos sistemas pueden ejecutar comandos. La lección es que el comportamiento serio de un agente proviene del sistema que lo rodea: la capa de planificación, el límite de la herramienta, el modelo de aprobación, los artefactos de transferencia, el verificador y la cadena de pruebas. El largo trabajo de Anthropic en materia de arneses lo deja claro. Sus publicaciones públicas sobre ingeniería describen la deriva del contexto, la "ansiedad del contexto", los traspasos estructurados, los roles planificador-generador-evaluador, los contratos de sprints y el valor de un evaluador independiente que sea más escéptico que el generador. (Antrópico)
Si se traslada esto al pentesting, la cuestión cambia. Deja de ser "¿Puede Claude Code hacer pentesting?" y se convierte en "¿Qué aspecto tendría un arnés de pentesting si tomara prestadas las ideas correctas de Claude Code y las adaptara al trabajo de seguridad orientado a objetivos y centrado en las pruebas?". Esa es la arquitectura que merece la pena construir.
Del estímulo al andamiaje
La forma más rápida de explicar el cambio es la siguiente: un estímulo pide un comportamiento, mientras que un arnés rige el comportamiento.
En una configuración ingenua de pentest de IA, el modelo obtiene un objetivo, tal vez algunas herramientas, y una instrucción suelta como "encontrar vulnerabilidades". A veces funciona para tareas de juguete. En un compromiso real suele producir uno de los cuatro malos resultados. El primero es el "tool thrash", en el que el modelo sigue invocando el reconocimiento superficial sin converger en una hipótesis concreta. El segundo es el estado frágil, en el que se olvida lo que importaba hace tres llamadas a la herramienta. La tercera es la inflación narrativa, en la que "esto parece vulnerable" se escribe como un hallazgo confirmado. El cuarto es la deriva insegura, donde el sistema expande el alcance o ejecuta acciones que nunca fueron explícitamente autorizadas. Los hallazgos de PentestGPT sobre la pérdida de contexto y los escritos públicos de Anthropic sobre agentes de larga duración apuntan al mismo modo de fallo central: el problema no es sólo la calidad del razonamiento, sino si el sistema que rodea al modelo preserva la dirección y el control. (arXiv)
La propia guía de mejores prácticas de Anthropic es notablemente contundente aquí. Dice que lo mejor que puedes hacer es dar a Claude una forma de verificar su trabajo. Sin criterios claros de éxito, te conviertes en el único bucle de retroalimentación. En el código, eso significa pruebas, capturas de pantalla o resultados esperados. En pentesting, la traducción es más fuerte: sesiones frescas, peticiones reproducibles, cambios de rol, validación del estado del navegador y captura de artefactos. Un agente de pentesting que no puede verificar sus propias afirmaciones no es un probador autónomo. Es un generador de hipótesis con una peligrosa dosis de confianza. (Claude)
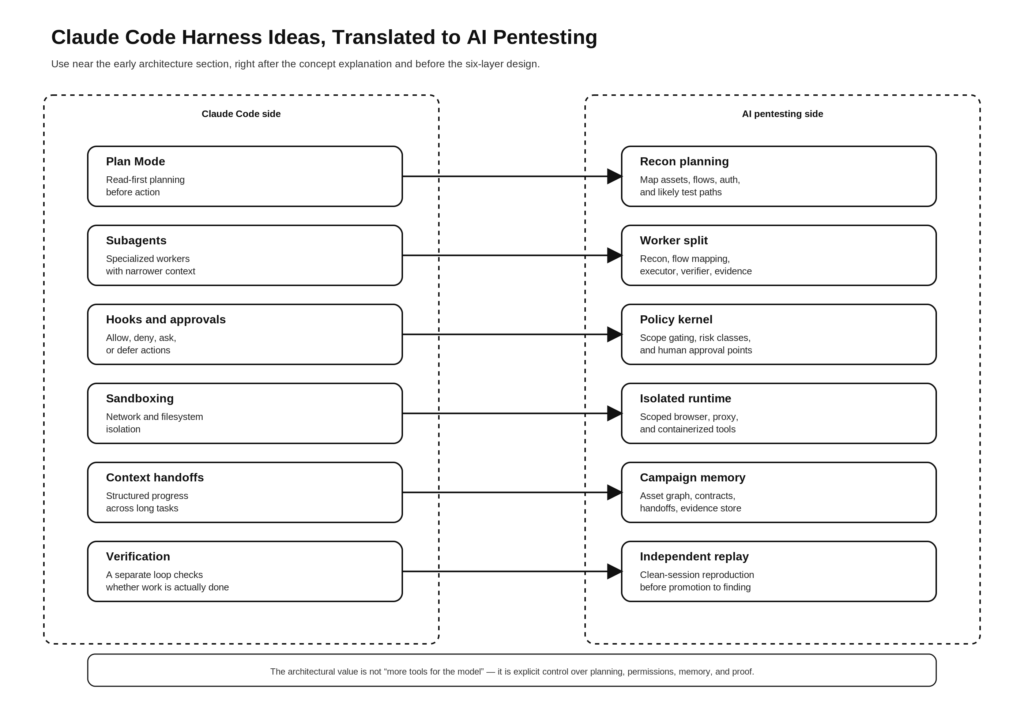
Claude Code también expone un patrón de diseño que los ingenieros de seguridad deberían tomar prestado casi al pie de la letra: utilizar una planificación segura y orientada a la lectura por adelantado, y luego escalar sólo cuando se tenga una razón limitada para hacerlo. El Modo Plan en los documentos públicos está explícitamente diseñado para el análisis de sólo lectura y la recopilación de requisitos antes de realizar cualquier cambio. En una traducción de pentest, esto se convierte en planificación recon-first: rastrear, mapear, agrupar, correlacionar y decidir qué merece una comprobación activa antes de intentar cualquier acción que cambie el estado. (Claude API Docs)
La misma lógica se aplica a los subagentes. Los documentos de Anthropic describen los subagentes personalizados como asistentes especializados con sus propios avisos, su propio acceso a herramientas y sus propias ventanas contextuales. Esto no es sólo una conveniencia de codificación. Es un buen modelo mental para el pentesting de IA, porque el reconocimiento, la comprensión del flujo de negocio, la validación de exploits, y la presentación de informes no son el mismo trabajo y no deben compartir permisos idénticos o contexto idéntico. (Claude API Docs)
Por lo tanto, el arnés que figura a continuación no es un clon del Código Claude. Es una traducción.
En qué se convierten las primitivas públicas de Claude Code en el pentesting de IA
La asignación es sencilla una vez que la forma de la tarea está clara.
| Claude Código primitivo | Qué significa en Claude Code | AI pentesting traducción |
|---|---|---|
| Modo Plan | Análisis de sólo lectura antes de las ediciones | Reconocimiento de sólo lectura, asignación de activos y planificación de objetivos |
| Subagentes | Asistentes especializados con distintas funciones y acceso a herramientas | Recon worker, trazador de flujos, ejecutor, verificador, redactor de pruebas |
| Ganchos PreToolUse y PermissionRequest | Controles de políticas antes de la ejecución de la herramienta | Gatekeeper en tiempo de ejecución para el alcance, la clase de riesgo, la tasa y la aprobación |
| Sandboxing | Aislamiento del sistema de archivos y de la red para una autonomía más segura | Contenedor de pruebas, listas de dominios permitidos, controles de salida, navegador aislado y proxy. |
| Compactación de contextos y traspasos | Continuidad en las tareas largas a pesar de los límites del contexto | Memoria de campaña, resúmenes de sesiones, compromisos resumibles |
| Dar a Claude una forma de verificar su trabajo | Las pruebas y los resultados previstos mejoran la fiabilidad | Repetición, diffing, confirmación multisesión, pruebas reproducibles |
| Modo automático negar-y-continuar | Si se bloquea, recupérate e intenta un camino más seguro | Si se deniega una prueba activa, vuelva a la validación pasiva o de menor riesgo. |
Esto es una síntesis, pero cada fila se basa en el material público de Anthropic. Sus documentos y publicaciones de ingeniería describen el Modo Plan como un análisis de sólo lectura, los subagentes como contextos especializados, los ganchos como puntos de control de permitir-denegar-pedir-deferir, el sandboxing como aislamiento del sistema de archivos y de la red, los arneses de larga duración como sistemas multiagente estructurados con traspasos, y la verificación como la única mejora de la fiabilidad de los agentes de mayor aprovechamiento. (Claude API Docs)
El resto de este artículo desarrolla la versión pentest de esa tabla.
Por qué el pentesting de IA necesita algo más que un modelo
Una prueba de penetración es una de las peores tareas posibles para un agente individual libre. El objetivo cambia bajo observación. El estado de autenticación importa. La lógica de negocio importa. Las suposiciones del entorno importan. Un "éxito" puede ser falso si sólo funciona en una sesión contaminada, sólo funciona con cookies de administrador ya presentes, sólo funciona contra un artefacto CDN, o sólo aparece porque el agente interpretó una respuesta ruidosa como prueba.
El OWASP WSTG sigue siendo útil aquí porque obliga a la persona que realiza las pruebas a pensar en amplias categorías de ataques en lugar de en aciertos aislados del escáner. La Guía de Pruebas de IA extiende esa disciplina a los sistemas de IA tratando la evaluación como una prueba de confianza práctica y estructurada más que como una comprobación de vibraciones. PentestGPT empuja en la misma dirección desde otro ángulo: el progreso real viene de descomponer el trabajo y mantener una representación del estado. (OWASP)
El largo trabajo de aprovechamiento de Anthropic añade una lección complementaria. La arquitectura planificador-generador-evaluador mejoró los resultados porque los agentes no hacían todos lo mismo. El planificador ampliaba las indicaciones cortas para convertirlas en especificaciones más completas. El generador construyó de forma incremental. El evaluador interactuaba directamente con la aplicación en ejecución y aplicaba umbrales estrictos. Antes de cada sprint, el generador y el evaluador negociaban un contrato sobre el significado de "hecho". Ese patrón exacto es casi vergonzosamente adecuado para el pentesting. (Antrópico)
En términos de pentesting, la traducción es obvia. El planificador se convierte en un compilador de hipótesis. El generador se convierte en un trabajador de ejecución. El evaluador se convierte en un verificador independiente. El contrato sprint se convierte en un contrato de ataque. El sistema de compactación y transferencia se convierte en una memoria de campaña. El resultado no es "más agentic pentesting" en abstracto. Es un sistema que puede pasar de la señal a la prueba sin convertir silenciosamente las conjeturas en hallazgos.
Las seis capas de un arnés de pentesting de IA
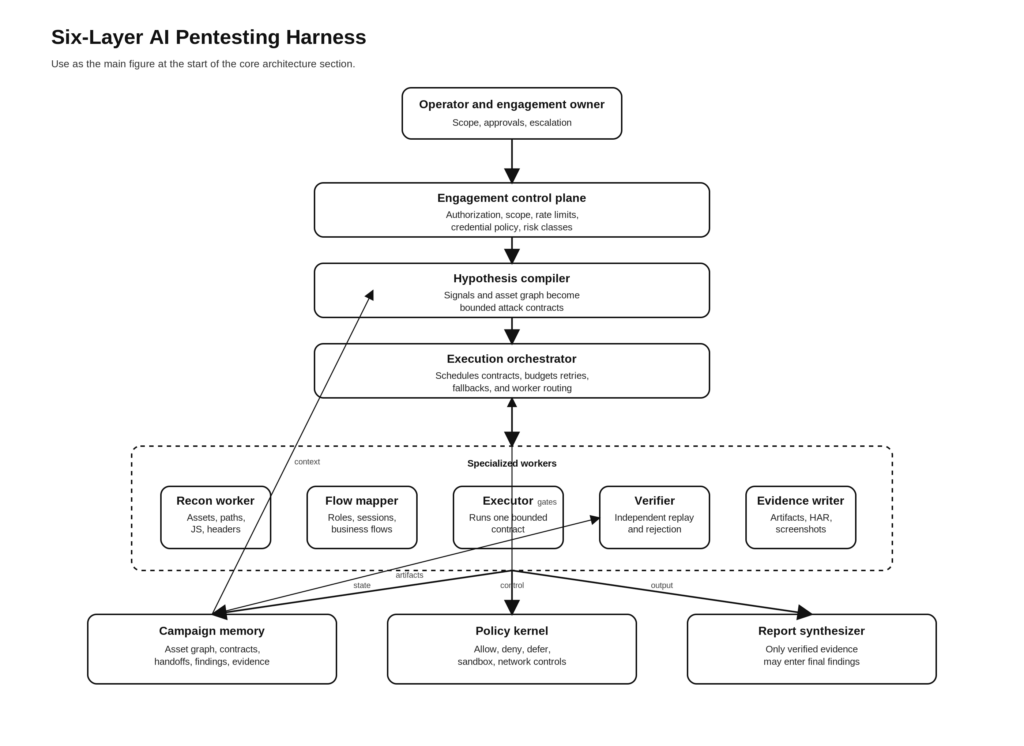
La arquitectura que sigue es el diseño que yo construiría si el objetivo fuera tomar prestadas las ideas más sólidas de Claude Code y adaptarlas a un pentesting de IA autorizado y basado en pruebas.
Capa uno, plano de control del compromiso
El arnés empieza antes de la primera llamada a la herramienta. Comienza con el propio compromiso.
NIST SP 800-115 hace hincapié en la planificación como parte de las pruebas técnicas, no como papeleo ajeno al sistema. El marco de agentes de confianza de Anthropic dice más o menos lo mismo con otro vocabulario: mantener a los humanos bajo control, especialmente antes de acciones de alto riesgo, y tratar la autonomía como algo que debe limitarse. Claude Code se describe como de sólo lectura por defecto y con aprobación para modificar los sistemas. Para el pentesting, esa misma lógica debe codificarse en un manifiesto de compromiso legible por la máquina que el tiempo de ejecución consuma en cada turno. (NIST CSRC)
Un plano de control de compromiso adecuado incluye alcance, ventanas de autorización, categorías de prueba, acciones no permitidas, presupuestos de tráfico, etiquetas de destino, límites de credenciales, restricciones de navegador, enrutamiento proxy y reglas de retención de pruebas. También necesita una clasificación de acciones por riesgo. Las lecturas pasivas y la recopilación de metadatos son una clase. La enumeración activa de bajo impacto es otra. Las acciones que cambian el estado, el uso de credenciales, la carga de archivos o cualquier validación similar a un exploit deberían estar detrás de puertas separadas. El plano de control es donde "pentest autorizado" deja de ser una frase en un prompt y empieza a convertirse en una política en tiempo de ejecución.
Un manifiesto mínimo podría tener este aspecto:
compromiso:
id: acme-web-2026-q2
authorized_by: equipo_seguridad
window_start: 2026-04-10T09:00:00Z
window_end: 2026-04-17T23:00:00Z
ámbito:
dominios:
- app.ejemplo.com
- api.ejemplo.com
exclude_paths:
- /payments/live/*
- /admin/facturación/*
identidades_permitidas:
- anonymous
- usuario_privado_bajo
objetivos_prohibidos:
- terceros.ejemplo.net
- *.internal.ejemplo.com
tiempo de ejecución:
max_rps: 2
browser_allowed: true
upload_tests_allowed: false
credential_rotation_required: true
network_allowlist:
- app.ejemplo.com
- api.ejemplo.com
- auth.ejemplo.com
risk_policy:
passive_recon: auto
validación_de_bajo_impacto: auto
state_changing_actions: human_approval
exploit_like_execution: prohibido
external_callbacks: prohibido
informes:
capture_har: true
capture_screenshots: true
redact_secrets: true
Ese ejemplo es sencillo, pero el punto arquitectónico es mayor. Un agente de pentest nunca debería tener que inferir el alcance del compromiso sólo a partir del inglés. El plano de control debe ser analizado en tiempo de ejecución decisiones duras. El modelo de ganchos de Anthropic es una inspiración útil aquí porque formaliza los puntos de decisión antes de la ejecución de la herramienta, mientras que su marco de seguridad insiste en que los humanos mantengan el control antes de las acciones de alto riesgo. (Claude API Docs)
Capa dos, compilador de hipótesis y contratos sprint
La siguiente capa traduce las observaciones en trabajo acotado.
El arnés de aplicaciones de Claude Code, de larga duración, utilizaba un planificador para ampliar las breves indicaciones y convertirlas en especificaciones de producto más completas, y luego utilizaba la negociación generador-evaluador para decidir lo que contaba como un sprint completado. En pentesting, el equivalente no es un plan de características. Es una hipótesis de ataque con condiciones de prueba explícitas. (Antrópico)
Esto es importante porque las pruebas de penetración no son sólo ejecución de herramientas. Es gestión de hipótesis. Un probador ve un comportamiento, forma una teoría, se pregunta qué tendría que ser cierto para que esa teoría importe, y luego diseña una comprobación. El arnés debe hacerlo explícito. En lugar de decirle al modelo "prueba auth", el sistema debe crear un contrato como: "Este objetivo parece aceptar identificadores de objetos controlados por el usuario en tres puntos finales. Pruebe si la autorización se aplica en el servidor a través de las transiciones de rol, utilizando sólo credenciales de bajo privilegio, sin mutar los registros protegidos". Eso es trabajo que el modelo puede ejecutar. "Encontrar algo interesante" no lo es.
Un contrato de ataque práctico tiene al menos estos campos:
{
"contract_id": "idor-orders-001",
"target": "",
"goal": "Verificar si la autorización a nivel de objeto se aplica en todos los roles de usuario",
"preconditions": [
"Dos cuentas de bajo privilegio con acceso a conjuntos de órdenes diferentes",
"Sesión limpia para cada repetición"
],
"allowed_actions": [
"Peticiones GET",
"Navegación del navegador",
"Reinicio de sesión",
"Difusión de respuestas"
],
"forbidden_actions": [
"Modificación de registro",
"Enumeración masiva",
"Devoluciones de llamada externas"
],
"success_signals": [
"Acceso cruzado de cuentas a datos de órdenes protegidas",
"Reproducción estable a través de dos sesiones limpias"
],
"failure_signals": [
"Denegación de autorización consistente",
"Comportamiento sólo aparece en estado de sesión contaminada"
],
"required_evidence": [
"Par de solicitud y respuesta",
"Role mapping",
"Replay transcript",
"Captura de pantalla si el navegador es visible"
],
"risk_class": "medio",
"budget": {
"max_requests": 20,
"max_duration_seconds": 600
},
"exit_condition": "Verificado o rechazado con razones"
}
El contrato hace dos cosas a la vez. Reduce el espacio de búsqueda y eleva el listón probatorio. El arnés público de Anthropic señala que el generador y el evaluador negociaron un contrato sprint antes de empezar a trabajar precisamente porque el evaluador necesitaba una definición comprobable de "hecho". La misma disciplina es aún más valiosa en el ámbito de la seguridad, donde "hecho" es peligrosamente fácil de falsificar. (Antrópico)
Capa tres, trabajadores de ejecución especializados
Los subagentes son una de las ideas más transferibles de la pila de Claude Code. Anthropic los describe como asistentes especializados para flujos de trabajo de tareas específicas y una mejor gestión del contexto. Esto debería sonar inmediatamente a verdad a cualquiera que haya hecho pentesting real. Recon, auth-flow mapping, exploit validation, y la redacción de informes son trabajos diferentes. No deberían compartir las mismas indicaciones, herramientas o autoridad. (Claude API Docs)
Un arnés de pentest maduro debe separar como mínimo cinco roles de ejecución.
El primero es un trabajador de reconocimiento. Su trabajo consiste en descubrir y normalizar la superficie: hosts, rutas, puntos finales, parámetros, rutas JavaScript, variantes de inicio de sesión, cabeceras, almacenes de objetos, superficies de administración y dependencias de terceros. Debe utilizar muchas herramientas, pero con pocos privilegios. No se le debe permitir "validar" hallazgos en el sentido de informar.
El segundo es un mapeador de flujos. Este trabajador está más cerca de un analista de modelado de amenazas que de un escáner. Convierte las listas de puntos finales en comportamientos. ¿Qué identidades existen? ¿Dónde hay transiciones? ¿Qué acciones tienen estado? ¿Qué tipos de objetos aparecen en el tráfico del navegador? ¿Qué campos ocultos determinan las decisiones del flujo de trabajo? El resultado no es una declaración de vulnerabilidad. Es un gráfico estructurado del comportamiento empresarial.
El tercero es un ejecutor de hipótesis. Este es el trabajador que realmente ejecuta comprobaciones activas limitadas basadas en un contrato. Sólo debe obtener las herramientas y permisos requeridos por ese contrato. Nada más. La documentación pública de Anthropic sobre subagentes, permisos y ganchos apoya firmemente este estilo de delegación limitada: utilizar contextos especializados y restringir el acceso a las herramientas a lo que cada unidad realmente necesita. (Claude API Docs)
El cuarto es un verificador. Este trabajador no debe ser la misma entidad que ejecutó la verificación inicial. El largo trabajo de arnés de Anthropic es especialmente útil aquí porque argumenta que la autoevaluación es débil y que un evaluador separado es más fácil de afinar hacia el escepticismo. Para el pentesting, ese principio no es una optimización. Es un requisito de validez. (Antrópico)
El quinto es un redactor de pruebas. Su trabajo consiste en convertir el rastro en bruto en artefactos que otro ingeniero pueda reproducir. Esto significa pares de solicitud-respuesta, fragmentos de HAR, capturas de pantalla, notas de entorno, asignación de roles, casos negativos y notas de limpieza. Si su arnés fusiona este trabajador en el ejecutor, la captura de pruebas tiende a ser selectiva y desordenada.
Puedes añadir más funciones más adelante, pero estas cinco son suficientes para crear una sana separación de tareas.
Capa cuatro, bucles verificadores independientes
Esta es la capa que decide si el sistema es un arnés de pentest o una máquina cuentacuentos.
En la página de buenas prácticas de Anthropic se dice que la mejora más importante que se puede hacer es establecer criterios de verificación claros. Su arnés de aplicación de larga duración se lo tomó en serio dando al evaluador acceso Playwright y umbrales duros. El evaluador podía suspender un sprint si no se cumplía algún criterio clave. En seguridad, el equivalente es sencillo de describir y difícil de falsificar: un hallazgo no está completo hasta que un verificador independiente puede reproducir el comportamiento relevante en condiciones controladas. (Claude)
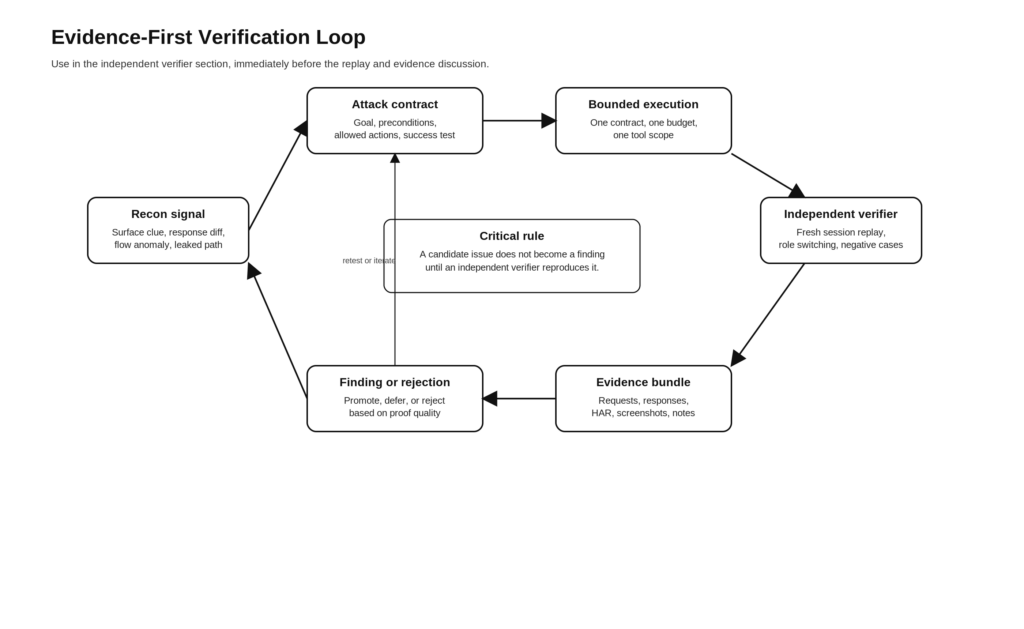
En el caso de las pruebas web y de API, un verificador independiente suele tener que hacer una combinación de lo siguiente:
- Reinicie la sesión y reproduzca desde el estado limpio.
- Cambia de papel o de identidad y compara comportamientos.
- Confirme que el resultado no está causado por el estado del cliente en caché o por cookies contaminadas.
- Confirme que el resultado no es un problema transitorio del flujo ascendente, un artefacto del proxy o una anomalía del WAF.
- Capture los casos negativos para que el informe pueda explicar cuál no es el problema.
- Captura pruebas suficientes para que un humano pueda reproducirlas sin fiarse de la narración del modelo.
Un pequeño andamio de repetición puede tener este aspecto:
from dataclasses import dataclass
from tipificación import List, Dict
@dataclass
clase ReplayCase:
nombre: str
perfil_sesión: str
especific_solicitud: Dict
señal_esperada: str
@clase_datos
clase VerificationResult:
nombre_caso: str
señal_observada: str
coincidente: bool
artefactos: Lista[str]
notas: str
def ejecutar_verificacion(casos: List[ReplayCase], ejecutor) -> List[VerificacionResultado]:
resultados = []
para case en cases:
runner.reset_session(case.session_profile)
response = runner.send(case.request_spec)
observado = runner.classify_signal(respuesta)
artefactos = []
artifacts.append(runner.save_request_response(case.name, response))
if runner.browser_visible(response):
artifacts.append(runner.save_screenshot(case.name))
results.append(
VerificaciónResultado(
nombre_caso=nombre.caso
señal_observada=observed,
matched=(observada ==señal_esperada.caso),
artefactos=artefactos,
notas=runner.explain_difference(señal_esperada_caso, observada)
)
)
devolver resultados
El código es intencionadamente sencillo. Lo importante es el procedimiento. La verificación es un paso aparte, no una ocurrencia tardía. Los propios escritos públicos de Anthropic sobre agentes de confianza también refuerzan el lado de control de esto: los agentes son valiosos porque pueden actuar, pero los seres humanos deben mantener el control antes de las decisiones o acciones de alto riesgo. Un arnés de pentest debe tratar la promoción de "problema candidato" a "hallazgo notificable" como una de esas transiciones de alto riesgo. (Antrópico)
Este es también el punto en el que una plataforma ofensiva nativa del flujo de trabajo resulta más fácil de justificar que un montón de herramientas conectadas ad hoc. Los materiales públicos de Penligent siguen volviendo a la misma norma: la señal no es suficiente, y un flujo de trabajo útil es aquel que convierte los hallazgos en impacto verificado, conserva una cadena de pruebas y empaqueta el resultado en informes editables. Su página de inicio hace hincapié en el bloqueo del alcance, las acciones personalizables, la ejecución guiada de la señal a la prueba y la elaboración de informes, mientras que las publicaciones técnicas recientes hacen hincapié en las pruebas adaptativas, el estado preservado y los hallazgos verificados en lugar de las conjeturas narradas. Tanto si un equipo utiliza esa plataforma específica como si no, el principio operativo es exactamente el correcto: el informe debe ser el final de la cadena de pruebas, no su sustituto. (Penligente)
Capa cinco, memoria persistente y traspasos
Uno de los silenciosos puntos fuertes de la larga labor de Anthropic en materia de arneses es que trata el estado como un problema de ingeniería de primer orden. Sus posts describen dos técnicas relacionadas. Una es la compactación del contexto, que mantiene una sesión acortando el historial. La otra es el restablecimiento del contexto más el traspaso estructurado, que proporciona a un nuevo agente suficiente estado de artefacto para continuar trabajando de forma coherente. Señalan que la compactación por sí sola no siempre resuelve la deriva y que los traspasos estructurados pueden ser esenciales. (Antrópico)
Esto se corresponde casi perfectamente con el pentesting. Un enfrentamiento real rara vez es un único bucle ininterrumpido. Los objetivos cambian. Las sesiones caducan. Los operadores paran y vuelven a empezar. Las credenciales rotan. Por lo tanto, un arnés significativo necesita una memoria persistente y estructurada que sea más rica que el historial de chat.
Como mínimo, el modelo de memoria debe contener:
- un manifiesto de compromiso,
- un gráfico de activos,
- una lista de contratos y su estado,
- un registro de hallazgos,
- un almacén de pruebas,
- un traspaso de progreso,
- y un registro de resumen de sesión.
A menudo basta con un simple diseño del directorio:
campaña/
engagement.yaml
activos/
asset_graph.json
rutas.json
identidades.json
contratos/
001-flujo-autentico.json
002-idor-pedidos.json
resultados/
candidatos.jsonl
verificado.jsonl
rechazados.jsonl
pruebas/
002-idor-orders/
replay_case_a.har
replay_case_b.har
browser.png
notas.md
progreso/
handoff.md
latest_summary.json
sesiones/
2026-04-11T0100Z.jsonl
2026-04-11T0900Z.jsonl
La clave del diseño es que el modelo nunca tiene que reconstruir toda la campaña a partir de la memoria de prosa. En su lugar, el arnés le proporciona un estado tipificado. Esa es exactamente la lección que PentestGPT apuntó con su Árbol de Tareas de Pentesting y exactamente el tipo de flujo de artefactos estructurado en el que se basó Anthropic en un trabajo de larga duración. (arXiv)
Esta capa también es importante para la auditabilidad. Un revisor humano debería poder responder a preguntas sencillas sin pedir al modelo que recuerde nada. ¿Qué hipótesis se probaron y rechazaron? ¿Cuáles se promovieron? ¿Cuáles fueron bloqueadas por la política? ¿Cuáles necesitan todavía la aprobación humana? ¿Qué identidades se han utilizado? ¿Qué conjuntos de pruebas están completos? Si la respuesta a estas preguntas sólo existe en la transcripción de un agente, el arnés aún no está maduro.
Capa seis, núcleo de políticas y controles en tiempo de ejecución
El modelo de seguridad pública de Claude Code es una de las razones más claras de su utilidad como referencia arquitectónica. Anthropic no presenta el uso de herramientas como una mera cuestión de confianza. Presenta el uso de herramientas como algo gobernado por aprobaciones, ganchos, sandboxing y políticas. La documentación de los ganchos dice que PreToolUse puede permitir, denegar, solicitar o aplazar llamadas a herramientas e incluso modificar la entrada de herramientas antes de su ejecución. La referencia a los hooks también advierte que los hooks de comandos se ejecutan con todos los permisos del usuario del sistema. Su post sobre sandboxing es igualmente claro en que un sandboxing efectivo requiere tanto el aislamiento del sistema de archivos como el aislamiento de la red. Sin aislamiento de red, un agente comprometido puede filtrar archivos sensibles; sin aislamiento del sistema de archivos, puede escapar y recuperar el acceso a la red. (Claude API Docs)
Para el pentesting, esto significa que el arnés necesita un núcleo de políticas que se sitúe fuera del modelo y tome las decisiones finales sobre lo que puede ocurrir. Un patrón útil es clasificar las acciones en cuatro categorías.
Las acciones automáticas son las lecturas de bajo riesgo y las sondas limitadas.
Las acciones con aprobación son comprobaciones activas que pueden cambiar de estado o generar ruido.
Las acciones diferidas son comprobaciones legítimas que necesitan que un humano responda primero a una pregunta, como si una prueba de carga de bajo impacto es aceptable para este objetivo.
Las acciones prohibidas son todo aquello que queda fuera de lo autorizado.
Un pequeño archivo de políticas puede expresar esto limpiamente:
políticas:
- nombre: passive-read
coincidir:
herramienta: [Read, WebFetch, BrowserNavigate]
ámbito_objetivo: en_ámbito
action_class: pasivo
decisión: allow
- nombre: low-impact-api-validation
coincidencia:
tool: [HttpRequest]
método: [GET, HEAD]
target_scope: in_scope
rate_limit_ok: true
decisión: allow
- nombre: state-changing-checks
coincidencia:
tool: [HttpRequest, BrowserAction]
método: [POST, PUT, PATCH, DELETE]
ámbito_objetivo: ámbito_in
decisión: aplazar
pregunta: "Esta acción puede cambiar el estado de la aplicación. ¿Aprueba?"
- nombre: external-callbacks
coincidencia:
ámbito_destino: externo
decisión: denegar
reason: "La infraestructura de devolución de llamada fuera de alcance está bloqueada"
- nombre: exploit-like-execution
coincidencia:
action_class: exploit_validation
decisión: denegar
reason: "La ejecución tipo exploit queda fuera de este perfil de compromiso"
Aquí es donde la idea de "negar y continuar" de Anthropic resulta valiosa. Su descripción pública del modo automático dice que cuando el clasificador bloquea una acción, Claude no debe simplemente detenerse; debe recuperarse e intentar un camino más seguro si existe. En un arnés de pentest, eso significa que una acción destructiva denegada debería desencadenar un retroceso a la confirmación pasiva, el análisis de la ruta del código, la comparación de roles o la escalada humana en lugar de una parada en seco. (Antrópico)
El núcleo de la política también necesita comprender el riesgo específico de MCP. La guía oficial de seguridad MCP es inusualmente relevante para los equipos de seguridad porque no habla en términos vagos. Nombra como superficies de ataque reales los problemas de adjunto confuso, el paso de token, el SSRF, el secuestro de sesión, el compromiso del servidor MCP local y la minimización del alcance. La especificación de autorización MCP también requiere la validación de la audiencia y rechaza explícitamente los patrones de uso indebido de tokens que difuminarían los límites de seguridad entre servicios. (Modelo de Protocolo de Contexto)
Un arnés de pentest que se conecta a las herramientas MCP pero no valida de forma independiente las audiencias de token, impone la minimización del alcance y separa las credenciales ascendentes y descendentes está construyendo sobre arena.
Por qué los objetivos deben tratarse como entradas adversas
El error más profundo que la gente comete con el agentic pentesting es asumir que el objetivo es la única cosa bajo prueba. En realidad, todo lo que toca el arnés puede convertirse en una superficie de ataque.
La investigación de Anthropic sobre inyecciones rápidas en navegadores lo dice claramente. Cuando un agente navega por Internet, cada página es un vector de ataque potencial. La inyección inmediata sigue siendo un gran reto sin resolver, especialmente cuando los agentes realizan acciones en el mundo real, y Anthropic dice explícitamente que el problema no está resuelto incluso con defensas mejoradas. El material GenAI de OWASP dice lo mismo en términos más generales: la inyección indirecta puede exponer datos sensibles, conceder acceso no autorizado a funciones, ejecutar comandos en sistemas conectados y manipular la toma de decisiones. La inyección indirecta de prompt es especialmente relevante cuando el modelo consume datos externos como páginas, documentos o archivos. (Antrópico)
Esto tiene una implicación directa en el pentesting de IA. El cuerpo de la respuesta de destino no son sólo datos. Un paquete JavaScript, un nodo DOM, un PDF, un campo de comentarios o una página de documentación pueden contener instrucciones diseñadas para dirigir el modelo. Lo mismo puede ocurrir con un repositorio, un léame, un archivo de salida de una herramienta o una respuesta de API simulada. Por lo tanto, el arnés debe tratar el objetivo como una entrada adversa en cada capa.
Esto cambia la forma de diseñar los trabajadores. El recon worker no debería poder reinterpretar contenido arbitrario de la página como instrucciones de confianza. El mapeador de flujo debe separar las observaciones extraídas de las directivas del agente. El verificador no debe confiar en los comentarios proporcionados por el ejecutor. El redactor de pruebas debe anotar de dónde proceden los artefactos y si se generaron a partir de fuentes fiables o no fiables. La inyección de instrucciones no es un caso extremo opcional. Forma parte del modelo de amenaza normal de las pruebas con agentes. (Antrópico)
También cambia la forma de pensar sobre las herramientas. La guía de seguridad MCP no sólo habla de tokens. Nombra el compromiso del servidor local y la minimización del alcance porque el plano de la herramienta es parte de la superficie de ataque. La documentación de los hooks de Anthropic advierte de forma similar que los hooks de comandos se ejecutan con todos los permisos del usuario. Una vez que combinas el acceso a la herramienta, la ejecución de comandos, el acceso al navegador, la memoria y la configuración repo-local, la vieja línea entre "datos" y "ejecución" comienza a disolverse. (Modelo de Protocolo de Contexto)
Una forma útil de razonar sobre esto es modelar cuatro clases de entrada.
| Clase de entrada | Ejemplos | Riesgo primario | Control necesario |
|---|---|---|---|
| Instrucciones de confianza | Manifiesto de compromiso, autorizaciones de los operadores, normas políticas | Autorización demasiado amplia o política obsoleta | Política de versiones, revisión, control de cambios |
| Contexto interno semiconfiable | Notas, resúmenes de entrega, pruebas previas | Envenenamiento de la memoria, suposiciones rancias | Esquemas estructurados, etiquetas de procedencia, caducidad |
| Contenido de destino no fiable | HTML, JS, documentos, PDF, respuestas API | Inyección indirecta, despiste, prueba falsa | Etiquetado de entradas, análisis sintáctico "sandboxed", sin seguimiento implícito de instrucciones |
| Contenido del plano de herramientas | MCP outputs, hook inputs, repo config, scripts locales | Ejecución de órdenes, robo de fichas, diputado confundido, SSRF | Listas de herramientas, validación de audiencias, aislamiento de contenedores, modelo de confianza de repositorios |
La tabla es una síntesis, pero sigue los patrones de amenazas documentados por Anthropic, OWASP y la propia guía oficial de seguridad de MCP. (Antrópico)
Las CVE que hacen que esta arquitectura no sea opcional
El diseño de alto nivel se vuelve mucho menos abstracto cuando se observa lo que ya ha ocurrido en sistemas de agentes adyacentes.
Langflow CVE-2025-3248 y el mito de los helper endpoints inofensivos
NVD describe CVE-2025-3248 como un problema de inyección de código en versiones de Langflow anteriores a la 1.3.0. El endpoint vulnerable era /api/v1/validar/códigoy el fallo permitía a un atacante remoto no autenticado enviar peticiones que ejecutaban código arbitrario. CISA añadió posteriormente el problema a su flujo de trabajo de Vulnerabilidades Explotadas Conocidas. (NVD)
¿Por qué es importante para un artículo sobre el arnés de pentest? Porque es un ejemplo claro de un fallo que muchos equipos siguen subestimando. Los productos de flujo de trabajo de IA a menudo contienen rutas de "ayuda" o "validación" que parecen funciones de apoyo en lugar de superficies de ejecución principales. En la práctica, la cosa llamada validar puede ser exactamente donde ocurre la ejecución insegura. Un arquitecto de arneses debería aprender dos lecciones de esto. En primer lugar, las capacidades internas de ayuda deben ser modeladas contra amenazas como límites de ejecución, no como características de conveniencia. En segundo lugar, la política y la verificación deben cubrir los puntos finales de apoyo tan agresivamente como los obvios. (NVD)
Para los defensores, la historia de la mitigación es igualmente instructiva. NVD apunta a versiones reparadas y referencias de proveedores. A nivel de arquitectura, la reparación no es sólo "añadir auth". También es "dejar de asumir que las funciones de validación de código pueden procesar de forma segura entradas controladas por atacantes". Eso es una corrección de diseño, no sólo un parche. (NVD)
Langflow CVE-2026-33017 y el peligro de las correcciones parciales
El problema posterior de Langflow es aún más revelador. NVD describe CVE-2026-33017 como un fallo de ejecución remota de código no autenticado en versiones anteriores a la 1.9.0. El endpoint vulnerable, POST /api/v1/build_public_tmp/{flow_id}/flowera intencionadamente no autenticado para los flujos públicos, pero aceptaba datos de flujo controlados por atacantes que contenían código Python arbitrario en las definiciones de los nodos y los pasaba a exec() con sandboxing cero. NVD señala explícitamente que este problema es distinto de CVE-2025-3248. No era el mismo error resurgiendo en el mismo endpoint. Se trataba de un modelo de ejecución más amplio que aparecía en otro lugar. NVD también registra que el fallo entró en el Catálogo de Vulnerabilidades Explotadas Conocidas de CISA en marzo de 2026. (NVD)
Este es exactamente el tipo de lección que los creadores de arneses de pentest de IA deberían tener en cuenta. Un sistema puede arreglar un punto final peligroso y seguir conservando el patrón subyacente en otro lugar. Si su arnés tiene múltiples rutas de código que pueden transformar datos no fiables en invocaciones de herramientas, acciones del navegador o comandos de shell, parchear una superficie no es suficiente. Necesitas un límite arquitectónico. En el lenguaje de Anthropic, eso significa sandboxing real y capas de permisos. En el lenguaje de pentest-harness, significa un núcleo de políticas fuera del modelo y un tiempo de ejecución que nunca trata las superficies "públicas" o "de ayuda" como automáticamente de bajo riesgo. (Antrópico)
Claude Code problemas de configuración a nivel de repositorio y el nuevo límite de ejecución
El caso de precaución más relevante para el propio Claude Code vino de Check Point Research en febrero de 2026. Su escrito dice que las configuraciones de proyectos maliciosos podrían abusar de ganchos, integraciones MCP y variables de entorno para lograr la ejecución remota de código y el robo de credenciales API cuando los usuarios clonaban y abrían repositorios no confiables. Su resumen afirma que los problemas fueron parcheados antes de su publicación, pero la lección arquitectónica es mayor que el parche. Argumentan que los archivos de configuración a nivel de repositorio se convirtieron en una capa de ejecución activa en lugar de metadatos operativos inofensivos. Check Point asoció esta investigación con CVE-2025-59536 y CVE-2026-21852. (Investigación de Check Point)
Este hallazgo se alinea incómodamente bien con la propia documentación de Anthropic. La referencia de hooks dice que los hooks de comandos se ejecutan con todos los permisos del usuario del sistema. El post sobre sandboxing dice que la protección efectiva requiere tanto el aislamiento del sistema de archivos como de la red. Una vez que una herramienta agentic puede leer archivos, ejecutar comandos, conectar herramientas y cargar la configuración local del proyecto, el contenido del repositorio se convierte en parte del límite de ejecución. (Claude API Docs)
Para el pentesting de IA, esto es importante por dos razones. En primer lugar, su arnés interactuará a menudo con objetivos no fiables, repositorios no fiables, documentos no fiables o contenido de navegador no fiable. En segundo lugar, los equipos de pentesting son especialmente propensos a conectar scripts locales, integraciones de proxy, servidores MCP y automatización específica del proyecto. Esto significa que un arnés mal diseñado puede ser atacado por el mismo ecosistema que está utilizando para probar otros. Si tomas prestada una lección del caso Claude Code, que sea ésta: la configuración forma parte del tiempo de ejecución. Modélala como amenaza.
Qué significan estos casos en la práctica
Los tres casos anteriores apuntan a una conclusión común. El riesgo en los sistemas agénticos no es sólo que el modelo razone mal. El riesgo es que una ruta de ejecución en alguna parte del arnés acepte una entrada no fiable como si fuera seguro ejecutarla, seguro autorizarla o seguro confiar en ella.
Por eso el diseño de seis capas no es una ceremonia. El plano de compromiso impide la extralimitación accidental. El compilador de hipótesis estrecha la ejecución. La especialización de los trabajadores reduce la propagación de privilegios. El verificador suprime las pruebas falsas. La memoria persistente impide que la pérdida de estado se convierta en deriva narrativa. El núcleo de políticas mantiene el plano de herramientas bajo control externo. Sin estas capas, usted está apostando la integridad de un flujo de trabajo pentest en un modelo de permanecer coherente y benevolente en condiciones adversas. El registro público ya dice que eso no es suficiente. (NVD)
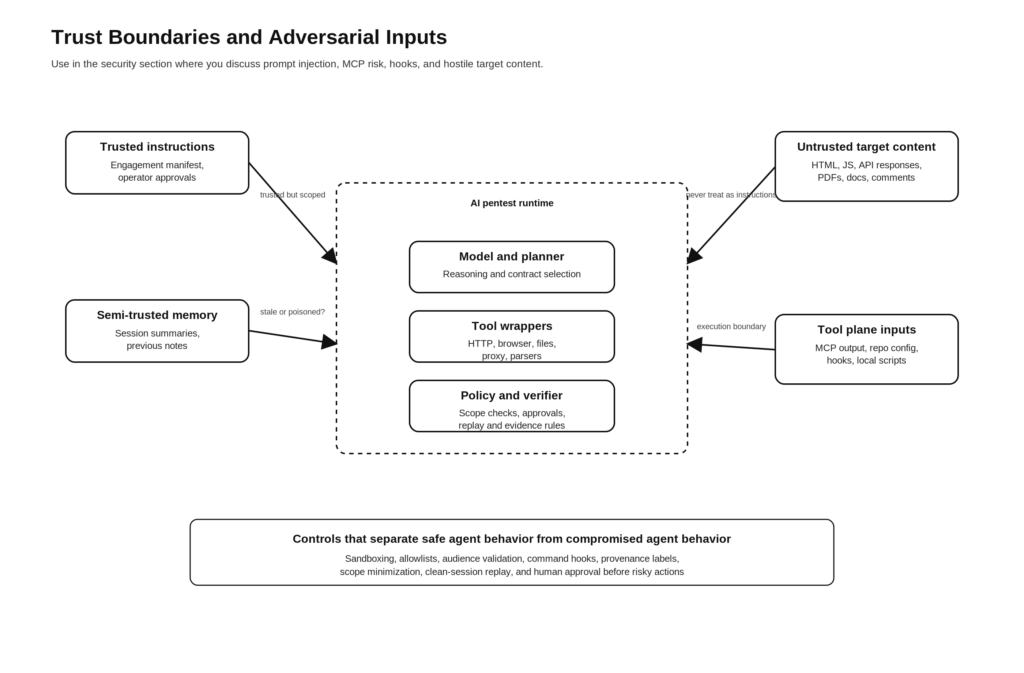
Arquitectura de referencia para un arnés de pentest de IA basado en pruebas
El sistema completo puede representarse de forma compacta:
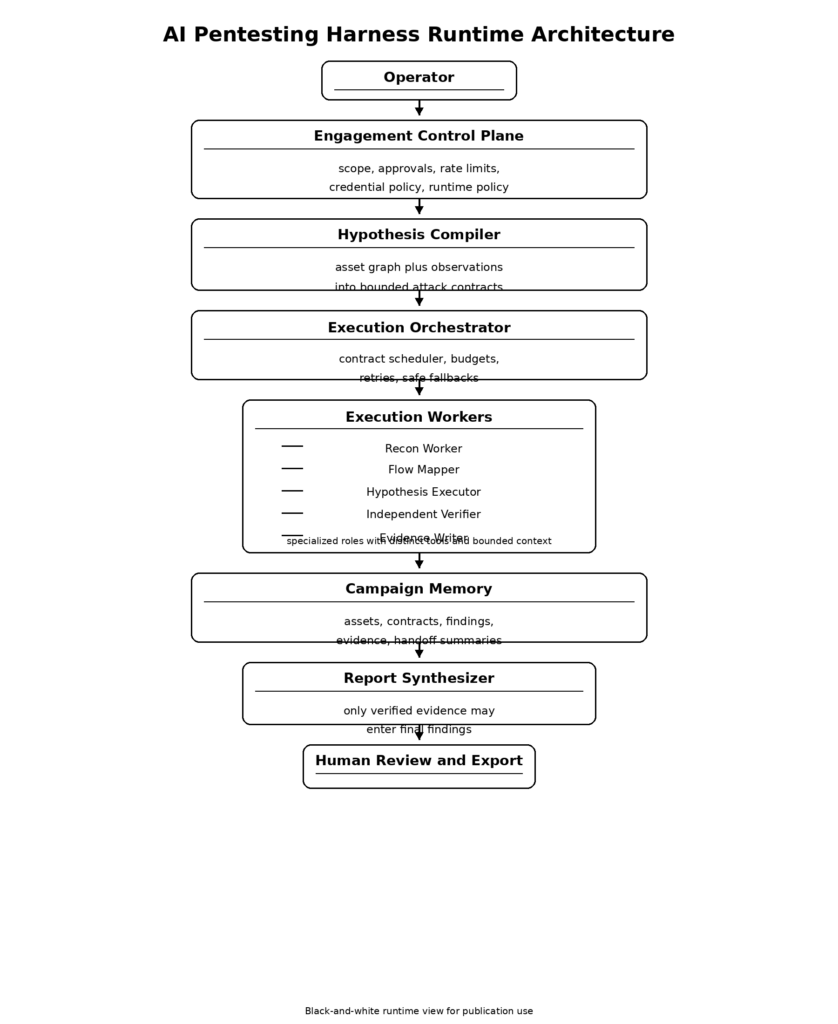
Hay dos razones por las que esta forma funciona.
La primera es que coincide con el desarrollo de las pruebas reales. El reconocimiento genera posibilidades. El análisis de flujo convierte las posibilidades en ideas de ataque. La ejecución prueba una idea limitada cada vez. La verificación decide si el resultado merece confianza. Los informes sólo se elaboran después. NIST SP 800-115 y OWASP WSTG son documentos muy diferentes, pero ambos refuerzan que las pruebas son un proceso, no una única fase del resultado de la herramienta. (NIST CSRC)
La segunda es que coincide con las observaciones públicas de Anthropic sobre los agentes. Las tareas largas mejoran cuando el trabajo se descompone, cuando los artefactos de traspaso preservan el estado y cuando un evaluador escéptico se sitúa fuera del generador. Los asistentes especializados mejoran la gestión del contexto. Los criterios de verificación mejoran los resultados. El sandboxing y los límites de las políticas hacen que la autonomía sea más segura. (Antrópico)
Una primera versión fuerte de este sistema no necesita una explotación autónoma. Necesita una progresión disciplinada. El arnés mínimo viable debe ser capaz de:
- ámbito y política de ingesta,
- construir un gráfico de activos,
- compilar un contrato cada vez,
- ejecutar comprobaciones limitadas,
- reproducirlos de forma independiente,
- persisten las pruebas,
- y exportar un artefacto notificable.
Eso es suficiente para probar la arquitectura antes de añadir comportamientos más atrevidos.
Modelo de datos, gráfico de activos, contrato de ataque, conjunto de pruebas
La opción de ingeniería más importante en este tipo de sistemas es dejar de centrarlo todo en la charla de forma libre y empezar a centrarlo todo en los objetos de datos.
El primer objeto es el gráfico de activos. No se trata sólo de una lista de URL. Es un gráfico de dominios, puntos finales, parámetros, cookies, cabeceras, identidades, roles, rutas JavaScript, almacenes de objetos, superficies de administración y transiciones observadas entre ellos. Su propósito no es sólo la visualización. Es dar al arnés un modelo utilizable por la máquina de dónde pueden existir límites de confianza y bordes de ataque.
Un esquema simplificado puede tener este aspecto:
from dataclasses import dataclass, field
from tipificación import List, Dict
@dataclass
clase AssetNode:
id: str
tipo: str
etiquetas: lista[str]
atributos: Dict[str, str] = field(default_factory=dict)
@clase_datos
clase AssetEdge:
origen: str
destino: str
relación: str
evidence_refs: Lista[str] = campo(default_factory=lista)
El segundo objeto es el contrato de ataque. Es la unidad de trabajo y la unidad de evaluación. Debe ser duradero, tipificado, resumible y auditable. Si el sistema no puede decirle qué contrato está ejecutando, qué significa el éxito, y qué pruebas se requieren, todavía está operando como un agente conversacional en lugar de como un arnés de pentest.
El tercer objeto es el conjunto de pruebas. A partir de él se construye un hallazgo notificable. No un párrafo. No un resumen. Un conjunto.
{
"finding_id": "idor-orders-001",
"status": "verified",
"severity_candidate": "high",
"contracts": ["idor-orders-001"],
"artefactos": {
"requests": ["req-1.json", "req-2.json"],
"responses": ["res-1.json", "res-2.json"],
"screenshots": ["browser-1.png"],
"har": ["session-a.har"],
"logs": ["verifier-notes.md"]
},
"reproducción": {
"identities": ["usuario_a", "usuario_b"],
"pasos": [
"Iniciar sesión como usuario_a",
"Capturar id de pedido",
"Iniciar sesión como usuario_b",
"Reproducir GET contra id de pedido de usuario_a"
],
"negative_case": "ID aleatorio inexistente devuelve 404"
},
"confidence": "high",
"review_required": true
}
Aquí es donde encaja de forma natural otra observación de producto comedido. El material reciente de Penligent sobre Claude como copiloto de pentest señala un punto con el que es fácil estar de acuerdo incluso si se elimina la marca por completo: un sistema sólido debería hacer hincapié en la elaboración de informes editables, material de prueba de concepto reproducible y hallazgos verificados en lugar de narraciones de IA no verificables. Las plataformas públicas de pentest nativas del flujo de trabajo que centran esos resultados apuntan al extremo correcto del problema. Lo difícil no es conseguir que un modelo suene inteligente. Es conseguir que el flujo de trabajo conserve la verdad lo suficiente como para que otra persona pueda volver a ejecutarlo. (Penligente)
Patrones de aplicación y código
La lógica central del orquestador no tiene por qué ser misteriosa. Sólo tiene que ser disciplinada.
Un bucle mínimo podría funcionar así:
def ejecutar_campaña(campaña):
while True:
contract = campaign.next_ready_contract()
si contrato es None
break
if not campaign.policy.allows(contrato):
campaign.defer(contract, reason="policy gate")
continuar
resultado_ejecución = campaign.executor.run(contrato)
if resultado_ejecucion.status == "rechazado":
campaign.record_rejection(contract, execution_result)
continuar
resultado_verificación = campaign.verifier.run(contrato, resultado_ejecución)
if resultado_verificacion.status == "verificado":
paquete = campaign.evidence_writer.build_bundle(
contrato, resultado_ejecución, resultado_verificación
)
campaign.promote_finding(contrato, paquete)
elif verification_result.status == "needs_review":
campaign.queue_human_review(contrato, resultado_verificación)
else:
campaign.record_rejection(contract, verification_result)
campaign.write_handoff()
Lo que importa no es la sintaxis. Es la estructura. El bucle obliga a cada candidato a pasar por la misma progresión: programar, política, ejecutar, verificar, persistir. Ese patrón es la traducción ofensiva-seguridad del bucle generador-evaluador de Anthropic y su énfasis en los criterios de verificación. (Antrópico)
El verificador también puede imponer la disciplina de repetición con la generación explícita de casos:
def build_replay_cases(contrato, candidato):
casos = []
for identidad en contrato["identidades_requeridas"]:
cases.append({
"name": f"{contrato['contrato_id']}-{identidad}-limpio",
"session_profile": identidad,
"request_spec": candidato["request_spec"],
"expected_signal": candidato["señal_esperada"]
})
si contract.get("caso_negativo"):
cases.append({
"name": f"{contrato['contract_id']}-negativo",
"session_profile": contract["negative_case"]["identity"],
"request_spec": contract["negative_case"]["request_spec"],
"expected_signal": contract["negative_case"]["expected_signal"].
})
devolver casos
Un verificador que tenga en cuenta el navegador puede añadir instantáneas del DOM o capturas de pantalla como pruebas de apoyo, lo que es conceptualmente similar a la forma en que el evaluador de Anthropic utilizó Playwright para inspeccionar la aplicación en ejecución en lugar de basarse únicamente en la salida estática. (Antrópico)
Por último, el motor de políticas puede situarse detrás de envoltorios de herramientas en lugar de vivir dentro de los avisos:
def guarded_http_request(política, petición):
decision = policy.evaluate_http(request)
if decision.kind == "deny":
raise PermissionError(decision.reason)
if decision.kind == "defer":
raise RuntimeError("Se requiere aprobación humana")
return send_http(solicitud)
Esta elección es más importante de lo que parece. Si el modelo sólo puede "prometer" respetar el ámbito, pero el tiempo de ejecución no puede hacerlo cumplir, el arnés es frágil por construcción.
Evaluar el arnés, no sólo el modelo
El artículo de Anthropic "Demystifying evals for AI agents" lo explica directamente: cuando evalúas un agente, evalúas el arnés y el modelo trabajando juntos. Esa debería ser también una suposición fundamental para el pentesting de IA. (Antrópico)
La pregunta de evaluación equivocada es: "¿Sugirió el modelo el siguiente paso correcto?". Las preguntas de evaluación correctas son más parecidas a estas
| Métrica | Por qué es importante |
|---|---|
| Porcentaje de ejecución de los contratos | Muestra si el arnés puede convertir las observaciones en unidades de prueba acabadas |
| Porcentaje de aprobados en la verificación | Mide cuántos temas de los candidatos sobreviven a la repetición independiente |
| Tasa de supresión de falsos positivos | Muestra si el verificador está realizando un trabajo real |
| Exhaustividad de las pruebas | Mide si los hallazgos son realmente notificables |
| Porcentaje de infracciones | Revela comportamientos inseguros o fuera del ámbito de aplicación |
| Tasa de crecimiento humano | Ayuda a calibrar la autonomía frente a la supervisión |
| Tasa de éxito de los currículos | Prueba si las campañas largas sobreviven a la interrupción |
| Precisión de la repetición de la prueba del parche | Mide si el sistema puede validar correcciones sin desviarse |
La tabla es arquitectónica más que de fuentes, pero se desprende directamente del marco de evaluación de Anthropic y de lo que normas como NIST SP 800-115 y OWASP WSTG esperan de un trabajo de pruebas real. Un sistema que obtiene muchos candidatos pero produce pruebas débiles e infracciones frecuentes de las políticas no es mejor que un sistema más lento con menos resultados, más limpios y reproducibles. (Antrópico)
La metodología de referencia de PentestGPT también es útil en este caso, ya que no reduce el rendimiento a un resultado binario final de explotación. El documento hace hincapié en el progreso de las subtareas y el logro progresivo. Se trata de un buen instinto para la evaluación de arneses. Una campaña debe recibir crédito por la precisión en el mapeo de activos, el rechazo correcto de hipótesis y el manejo fiel de casos negativos, no sólo por los momentos de "explotación encontrada". (arXiv)
Modos habituales de fallo
La mayoría de los sistemas de pentest de IA no fallan porque el modelo sea demasiado débil. Fallan porque la arquitectura permite que lo incorrecto cuente como éxito.
Un fallo común es dejar que el mismo trabajador ejecute y valide. El trabajo público de Anthropic en arneses de larga duración dice que los evaluadores separados son más fáciles de sintonizar hacia el escepticismo que los generadores. En el pentesting, combinar esas funciones es una invitación a inflar la confianza. (Antrópico)
Otro fallo es tratar la memoria como política. El marco de confianza-agente de Anthropic hace hincapié en que los humanos deben mantener el control y que los permisos importan. La memoria ayuda a la continuidad, pero la memoria no impone el alcance. Si tu único control de alcance es una nota que el modelo leyó antes, no tienes control de alcance. (Antrópico)
Un tercer fallo es dar acceso al shell o a la red demasiado pronto. El propio material de sandboxing de Anthropic es explícito en que tanto el sistema de archivos como el aislamiento de red son importantes. Los documentos de los hooks son igualmente explícitos en que los hooks de comandos se ejecutan con todos los permisos del usuario del sistema. Si un arnés pentest comienza con un shell con todos los privilegios y una ruta de red global, está a una entrada comprometida de convertirse en parte del problema. (Antrópico)
Un cuarto fallo es redactar informes a partir de la narración del agente en lugar de paquetes de pruebas. Este es el camino más corto para obtener falsos positivos que parezcan profesionales. Cuanto más pulido es el modelo lingüístico, más peligroso resulta esto, porque el informe se lee como certeza incluso cuando la prueba subyacente es escasa.
Un quinto fallo es creer que la inyección de comandos es principalmente un problema para los chatbots de consumo o los asistentes de navegación. La investigación de Anthropic sobre el uso de navegadores y el material de OWASP sobre la inyección inmediata dicen lo contrario. Cualquier sistema que consuma contenido no fiable y pueda realizar acciones en herramientas conectadas está en el punto de mira. Un arnés pentest AI vive exactamente en ese mundo. (Antrópico)
Cómo es un modelo operativo maduro
Un arnés de pruebas de inteligencia artificial maduro no intenta borrar al ser humano. Cambia allí donde el ser humano es más importante.
El marco de agentes de confianza pública de Anthropic lo enmarca en el mantenimiento del control humano al tiempo que permite la autonomía de los agentes. Esto se corresponde perfectamente con el pentesting. El humano no debería tener que copiar manualmente cada encabezado en cada solicitud de reproducción. El humano debe decidir qué clase de riesgo de acción es aceptable, lo que cuenta como un resultado notificable, y cuando un resultado candidato es lo suficientemente importante como para escalar. (Antrópico)
En la práctica, un modelo operativo maduro suele tener este aspecto.
El operador aprueba el manifiesto y el objetivo fijado.
El arnés realiza un reconocimiento de sólo lectura y construye un primer gráfico de activos.
El compilador de hipótesis genera contratos limitados.
Los trabajadores de ejecución realizan comprobaciones de bajo riesgo automáticamente.
El verificador sólo promueve resultados reproducibles de forma independiente.
Las pruebas de mayor riesgo se aplazan para la aprobación del operador.
Los paquetes de pruebas, no la narración, alimentan el informe.
Tras la corrección, se reproducen los mismos contratos para las pruebas de regresión.
Ese modelo operativo también facilita la combinación de herramientas en lugar de elegir un campo. Claude Code, según la propia documentación de Anthropic, es un potente banco de trabajo gobernado para el razonamiento consciente de los repositorios, las herramientas locales y los flujos de trabajo de subagentes flexibles. Los sistemas de pentest nativos del flujo de trabajo, incluido Penligent en sus materiales públicos, están optimizados en torno a la verificación orientada al objetivo, la conservación de pruebas y el empaquetado de informes. La postura madura no es confundir esos trabajos. Se trata de entender cuál es el lugar de cada uno. (Claude API Docs)
Cerrar el círculo
Lo más útil que Claude Code aporta al pentesting de IA no es una bolsa de comandos. Es una forma de pensar en los agentes como sistemas.
El trabajo de arnés público de Anthropic dice que las tareas largas mejoran cuando el contexto se gestiona deliberadamente, el trabajo se descompone, los evaluadores se separan y el éxito se vincula a pruebas concretas. PentestGPT dice que el pentesting automatizado mejora cuando la pérdida de contexto se trata como un problema de diseño en lugar de como un problema puntual. NIST y OWASP nos recuerdan que las pruebas de seguridad son un proceso disciplinado con planificación, ejecución, análisis e informes, no una secuencia ingeniosa de conjeturas. CVEs reales en Langflow y la investigación real en la propia superficie de ejecución a nivel de repositorio de Claude Code muestran lo que sucede cuando los sistemas agénticos difuminan la línea entre conveniencia y control. (Antrópico)
Así que la ambición correcta no es "hacer que el modelo se sienta más autónomo". La ambición correcta es construir un arnés que pueda mantener el estado, preservar el alcance, separar la planificación de la acción, separar la acción de la validación y separar la evidencia de la narración.
Esa es la diferencia entre una IA que ayuda con el pentesting y un flujo de trabajo de pentesting en el que realmente se puede confiar.
Lecturas complementarias y referencias
- Antrópico, arneses eficaces para agentes de larga duración. (Antrópico)
- Anthropic, Diseño de arneses para el desarrollo de aplicaciones de larga duración. (Antrópico)
- Anthropic, Desmitificando las evals para agentes de IA. (Antrópico)
- Anthropic, Visión general del SDK de Agente. (Claude API Docs)
- Anthropic, Buenas prácticas para el código Claude. (Claude)
- Antrópico, Crear subagentes personalizados. (Claude API Docs)
- Antrópico, referencia de Hooks. (Claude API Docs)
- Antrópico, Más allá de las peticiones de permiso, haciendo que Claude Code sea más seguro y autónomo. (Antrópico)
- Anthropic, Claude Code modo automático, una forma más segura de saltarse los permisos. (Antrópico)
- Anthropic, Mitigación del riesgo de inyecciones puntuales en el uso del navegador. (Antrópico)
- PentestGPT, presentación USENIX Security 2024. (USENIX)
- Documento PentestGPT, versión arXiv HTML. (arXiv)
- NIST SP 800-115, Guía técnica de pruebas y evaluación de la seguridad de la información. (NIST CSRC)
- Guía de pruebas de seguridad web de OWASP. (OWASP)
- Guía de pruebas de IA de OWASP. (OWASP)
- Iniciativa de Seguridad Agentica OWASP y Top 10 para Aplicaciones Agenticas 2026. (Proyecto OWASP Gen AI Security)
- Inyección de aviso OWASP LLM01. (Proyecto OWASP Gen AI Security)
- Modelo de Protocolo de Contexto, Mejores Prácticas de Seguridad. (Modelo de Protocolo de Contexto)
- Modelo de protocolo de contexto, especificación de autorización. (Modelo de Protocolo de Contexto)
- NVD, CVE-2025-3248. (NVD)
- NVD, CVE-2026-33017. (NVD)
- Aviso de Langflow en GitHub para CVE-2026-33017. (GitHub)
- Check Point Research, Caught in the Hook, RCE and API Token Exfiltration Through Claude Code Project Files. (Investigación de Check Point)
- Check Point Research, resumen de los fallos de Claude Code. (Blog de Check Point)
- AI Pentest Tool, cómo será la verdadera ofensiva automatizada en 2026. (Penligente)
- AI Pentest Copilot, de las sugerencias inteligentes a los hallazgos verificados. (Penligente)
- Claude AI para Pentest Copilot, Construyendo un Flujo de Trabajo de Evidencia-Primero con Claude Code. (Penligente)
- Claude Code for Pentesting vs Penligent, Dónde se detiene un agente de codificación y comienza un flujo de trabajo de Pentest. (Penligente)
- Claude Code Security y Penligent, de los hallazgos de caja blanca a las pruebas de caja negra. (Penligente)
- Página de inicio de Penligent. (Penligente)

