Why “openclaw internal reasoning leaking” is a real incident class, not a meme
“openclaw internal reasoning leaking” sounds like a single bug report. In practice it’s a recurring failure mode: OpenClaw ends up shipping internal planning text or “thinking” traces to user-visible surfaces—sometimes as normal messages inside Discord or Telegram, sometimes rendered in the web UI, and sometimes emitted as a separate message that precedes the final answer.
That matters because “reasoning” content is not harmless filler. In agent runtimes, verbose planning frequently includes tool intent, URLs, file paths, intermediate results, and occasionally tokens or identifiers—the same artifacts security teams spend years trying to keep out of chat logs, ticket systems, and support bundles.
The good news is you can treat this like any other security engineering problem: define what must never cross an output boundary, enforce it in code and configuration, and continuously test for regressions. The rest of this article is structured around exactly that.
What is internal reasoning in OpenClaw terms, and what counts as leaking
OpenClaw sits between messaging channels and one or more LLM providers. In that pipeline, you can see a few different “internal” payload types:
- Thinking blocks / internal reasoning: model-produced planning that should stay internal.
- Tool narration: “Let me check X… now I will run Y…”
- System prompts / greeting prompts: hidden instructions and policies that should never render as user content.
- Verbose tool output: raw stdout, tool args, URLs, and data retrieved during actions.
A leak happens when any of those are emitted as user-visible content in a channel that’s supposed to receive only the final response.
OpenClaw’s own security guidance explicitly calls out that reasoning and verbose output can expose internal details and should be treated as debug-only, especially in groups. (OpenClaw)
Verified evidence that the leak is happening across channels
This is not a theoretical fear. Multiple public issue reports show internal reasoning and even system prompt content being surfaced to users.
Discord, thinking content posted as regular messages
A GitHub issue documents internal reasoning/thinking being transmitted directly to Discord messages across different models. It also notes two suspected components: a “thinking=low” parameter being set even for non-reasoning models, and a failure to filter the reasoning field before sending to the channel. (GitHub)
Webchat, system prompt and thinking blocks rendered in the UI
Another issue reports that starting a new session can display the system greeting prompt as if it were sent by the user, and that thinking blocks are also visible in the chat interface. (GitHub)
Telegram, separate “Reasoning:” messages appear
A Telegram-specific report describes intermittent leakage where an extra message appears starting with “Reasoning:” and is confirmed to be user-visible in Telegram rather than internal logs. (GitHub)
WhatsApp, “[openclaw] Reasoning:” arrives before the response
A WhatsApp issue describes a user-visible message containing internal reasoning text (prefixed with “[openclaw] Reasoning:”) before the assistant’s final response. (GitHub)
Why this spread so fast in the security community
Once this starts appearing in external chat platforms, two forces amplify it:
- It becomes a privacy and trust breach that non-technical stakeholders notice immediately.
- It becomes a searchable incident signature—engineers can paste the exact phrase “openclaw internal reasoning leaking” and land on the relevant issues and mitigation threads.
That’s why this phrase behaves like an “IOC for operational failure,” not a niche curiosity.
Risk model, what can leak and why defenders should care
Security teams should treat reasoning leakage as information exposure with compounding blast radius. It’s not just about the text itself; it’s about what the text reveals about your environment and control plane.
What leaks commonly contain in agent runtimes
Even when models try to be careful, reasoning and verbose traces frequently include:
- tool and action intent, including what it is about to read or execute
- URLs, hostnames, internal endpoints, and query parameters
- file paths, directory structure hints, and workspace names
- “I will fetch the config / check env vars / open the session history”
- partial tool outputs or structured intermediate data
OpenClaw’s security documentation warns that verbose output can include tool args, URLs, and data the model saw, and recommends keeping reasoning/verbose disabled in public rooms. (OpenClaw)
Why this is worse than a normal chatbot leak
In an agentic runtime, the model is not only answering questions. It’s embedded in a system that:
- routes across chat apps
- maintains session memory
- can run tools and interact with host resources
That means a leak can expose not just content, but how to influence future actions. OpenClaw’s own security model stresses that it is designed around a single trusted operator boundary, and it is not intended as a hostile multi-tenant boundary for adversarial users sharing one gateway. (OpenClaw)
A practical impact table
| Leak artifact | Why it’s sensitive | Typical downstream risk |
|---|---|---|
| system prompt fragments | reveals policies, tool permissions, control logic | prompt injection becomes easier, policy bypass attempts become targeted |
| tool args and URLs | exposes internal endpoints, tokens in query strings, request shapes | SSRF-style probing, credential reuse, lateral movement hypotheses |
| file paths and filenames | reveals where secrets likely live | targeted exfil attempts, “go read ~/.ssh/…” style coercion |
| intermediate outputs | exposes data retrieved from tools | unintentional PII/IP leakage into third-party chat logs |
| channel/session identifiers | reveals how routing works | social engineering and replay attempts against operations |

Root causes, the leak usually comes from one of five engineering gaps
You’ll see different symptoms depending on provider, channel adapter, and UI path, but the root causes cluster into a small set.
1) Provider returns a reasoning field, and the adapter forwards it
The Discord issue explicitly describes a failure to filter the reasoning field before sending output to Discord. (GitHub)
This is the simplest failure: the pipeline correctly receives separate structured fields, but fails to enforce “final-only” at the channel boundary.
2) Streaming paths treat “thinking” as normal tokens
Even if your non-streaming response path strips reasoning, streaming often has a different code path. If the system assembles chunks and forwards them, it may accidentally forward the wrong chunk type to a channel.
You can see the operational reality in the Discord report: reasoning content appears “before or instead of the actual response,” which is typical of streaming or multi-message assembly bugs. (GitHub)
3) UI rendering bugs, system prompt becomes user content
The webchat issue is a clean example of a rendering failure: system greeting prompt text is displayed in the chat as if sent by the user, and thinking blocks are visible. (GitHub)
This is not “model behavior.” It’s a front-end or message formatting boundary failure.
4) Debug affordances used in public rooms
OpenClaw’s security guidance explicitly warns that /reasoning and /verbose can expose internal reasoning or tool output not meant for public channels, and recommends keeping them disabled in public rooms. (OpenClaw)
Even if the leak you’re seeing is unintended, it often gets worse when debug features are enabled broadly.
5) Misconfiguration plus exposure, the internet finds the footguns fast
Even if you fix reasoning leakage, the broader OpenClaw posture matters because exposed gateways attract immediate probing. Bitsight describes observing tens of thousands of exposed instances and notes that probes can arrive quickly when a gateway is reachable. (Bitsight)
This is where “reasoning leak” becomes part of a larger failure chain: debug output leaks details, exposure brings attackers, and the attacker now has context.
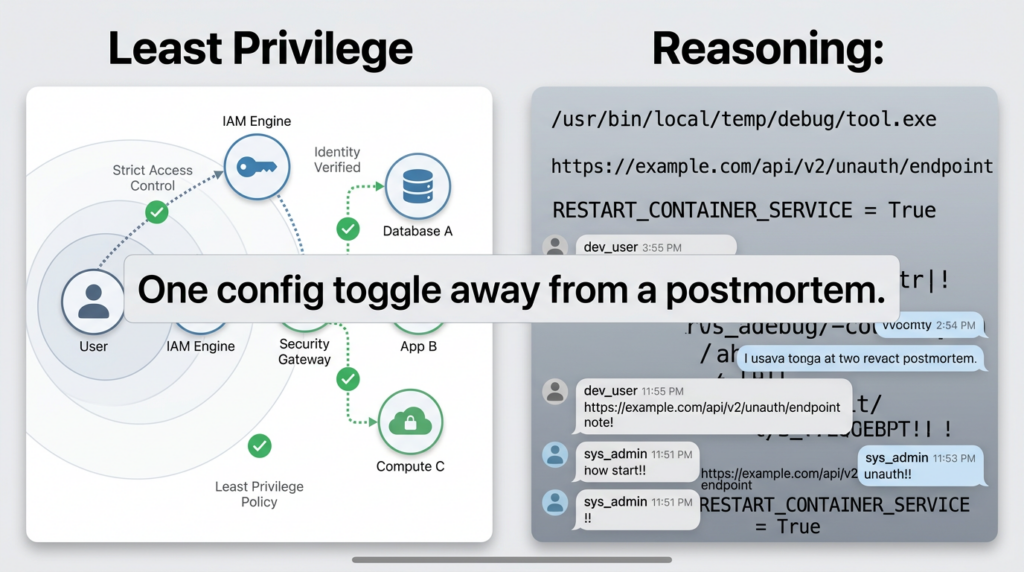
A 15-minute containment plan, stop the bleeding before you debug everything
If you are actively seeing “openclaw internal reasoning leaking” in any channel, do the following first. These steps are designed to reduce harm even if you have not identified the exact bug.
1) Treat it as a boundary breach, rotate what might have been exposed
Assume that anything the agent could see may be present in chat logs. Rotate or invalidate:
- bot tokens for the affected messaging platform
- provider API keys used by the agent
- OAuth refresh tokens and app approvals the agent might have had access to
- any secrets stored on the host that the agent could reference
If you need a reminder that token exposure can be operationally catastrophic, OpenClaw advisories include cases where tokens can appear in logs or error traces without redaction. (GitHub)
2) Disable reasoning and verbose in group contexts
OpenClaw’s security guidance is explicit: keep /reasoning and /verbose disabled in public rooms. (OpenClaw)
Even if your leak is “unintended,” disabling debug-like surfaces reduces the chance that the platform will echo internal traces.
3) Reduce network exposure, keep the gateway off untrusted networks
OpenClaw’s documentation calls out the gateway port, bind modes, and the risk of expanding the attack surface when binding to non-loopback interfaces. (OpenClaw)
If you must access remotely, prefer a solution that preserves loopback binding and adds an access control layer rather than exposing the gateway directly.
4) Upgrade to fixed versions for known high-severity issues
Even if your immediate incident is reasoning leakage, running known-vulnerable versions makes every other control weaker. ClawJacked-class issues and other vulnerabilities have had rapid patch cycles, with multiple reports advising immediate upgrades to patched releases. (BleepingComputer)
The durable fix, enforce “final-only” output at the channel boundary
Containment buys you time. The fix that scales is a simple rule:
No matter what the model returns, and no matter what the UI renders, only “final response content” is allowed to cross from OpenClaw into external messaging channels.
That means you need a sanitizer that runs after model output is assembled and before it is emitted to a channel adapter.
A reference sanitizer design
A robust sanitizer should handle all of these:
- remove structured
reasoningfields if present - remove “Reasoning:” prefixed lines that appear as separate messages
- block known system prompt fragments (high confidence patterns)
- prevent tool narration from being emitted in channels that require clean output
- optionally redact secrets by pattern (AWS keys, Slack tokens, GitHub tokens, etc.)
Below is an example in TypeScript-style pseudocode. Adapt it to your actual OpenClaw adapter architecture, but keep the idea: sanitize at the last possible moment, close to the output boundary.
// Defensive output sanitizer for messaging channels.
// Goal: ensure only final, user-intended content is emitted.
type ModelResponse = {
content?: string; // final user-facing content
reasoning?: string; // internal-only reasoning field (provider-specific)
tool_calls?: any[];
raw?: any; // provider raw payload (optional)
};
const RE_REASONING_PREFIX = /^\\s*(?:\\[openclaw\\]\\s*)?Reasoning:\\s*/i;
const RE_SYSTEM_PROMPT_HINTS = /(A new session was started|Do not mention internal steps|system prompt)/i;
// Minimal secret patterns (extend carefully; avoid false positives in normal text).
const RE_SECRETS = [
/AKIA[0-9A-Z]{16}/g, // AWS access key id
/xox[baprs]-[0-9A-Za-z-]{10,}/g, // Slack tokens
/ghp_[0-9A-Za-z]{30,}/g, // GitHub PAT (classic)
];
export function sanitizeForExternalChannel(input: ModelResponse | string): string {
let text = typeof input === "string" ? input : (input.content ?? "");
// If the provider returned a separate reasoning field, ignore it completely.
// Never append it to user content.
// (If your pipeline currently merges reasoning->content, stop doing that.)
// Drop stray "Reasoning:" lines if they slipped into content.
text = text
.split("\\n")
.filter(line => !RE_REASONING_PREFIX.test(line))
.join("\\n");
// Block obvious system-prompt leakage patterns.
if (RE_SYSTEM_PROMPT_HINTS.test(text)) {
text = "I can’t display internal instructions. Please rephrase your request.";
}
// Redact common secret formats.
for (const re of RE_SECRETS) text = text.replace(re, "[REDACTED]");
// Trim to avoid empty / whitespace-only posts.
text = text.trim();
// As a last resort, ensure something safe is returned.
if (!text) text = "Done.";
return text;
}
This is not a substitute for upstream fixes, but it prevents a whole class of regressions—especially the kind described in the Discord issue, where reasoning appears before the final output because the adapter fails to filter it. (GitHub)
Add a regression test that simulates the exact failure mode
The fastest way to prevent this from coming back is a tiny test that injects a response object containing a reasoning field and a “Reasoning:” prefixed message.
import { sanitizeForExternalChannel } from "./sanitize";
test("does not leak reasoning field or Reasoning: lines", () => {
const resp = {
content: "Reasoning: I will search internal logs\\nHere is the final answer.",
reasoning: "internal chain-of-thought that must never leak",
};
const out = sanitizeForExternalChannel(resp);
expect(out).toBe("Here is the final answer.");
});
If you operate multiple channel adapters, run the same test suite against each adapter path. The Telegram and WhatsApp reports show that leakage can manifest as extra messages or prefixes depending on the adapter. (GitHub)

Operational detection, catch leaks in logs before users report them
You want an early warning system that tells you “reasoning is escaping” before it lands in a public channel.
A lightweight approach is to tail outgoing message logs (or webhook payload logs) and alert on high-confidence patterns.
# Example: scan outgoing message logs for reasoning leakage markers
# Adjust log path to your deployment.
LOG=/var/log/openclaw/outgoing.log
grep -E -n "(\\[openclaw\\]\\s*Reasoning:|^Reasoning:|internal monologue|Do not mention internal steps)" "$LOG" \\
| tail -n 50
This will never be perfect, but it catches the most common visible forms seen in public issue reports: “Reasoning:” prefixes and explicit “do not mention internal steps” style prompt leakage. (GitHub)
Hardening the environment, assume the agent is privileged and isolate it
Even with perfect output sanitization, you should harden the runtime because OpenClaw is a high-privilege control plane by design.
OpenClaw’s own security documentation is direct about its trust model: it assumes a personal assistant deployment with one trusted operator boundary, and it is not designed as a hostile multi-tenant security boundary. (OpenClaw)
External security reporting echoes the same practical recommendation: treat OpenClaw as untrusted code execution with persistent credentials and run it in isolated environments rather than on standard enterprise workstations. (TechRadar)
Minimum viable hardening moves
- keep the gateway bound to loopback unless you have strong access controls
- use a dedicated host or VM for the agent runtime
- minimize credentials and rotate them frequently
- keep channel access allowlisted and avoid open public DMs
- treat extensions and skills as a supply-chain boundary
Bitsight’s analysis of exposed instances underscores why: once the gateway is reachable, probing can happen quickly, and attackers can skip the “AI layer” entirely and target the control plane. (Bitsight)
CVEs and advisories that make reasoning leaks more dangerous
Reasoning leakage is often filed as a “bug,” not a CVE. But the security impact is amplified when you combine it with known vulnerabilities that affect token handling, local file access, and gateway connectivity.
CVE-2026-25253, token exfil via gatewayUrl auto-connect
NVD describes CVE-2026-25253 as an issue where OpenClaw obtains a gatewayUrl from a query string and automatically makes a WebSocket connection without prompting, sending a token value. (NVD)
Why it matters for reasoning leaks:
- reasoning and verbose traces often include URLs and routing context
- any leak that reveals how your gateway URL and token are handled can shorten an attacker’s path to token theft
- it reinforces the policy: tokens must never appear in logs, chat, or UI
CVE-2026-25475, MEDIA path handling enables arbitrary local file read
NVD describes CVE-2026-25475 as a flaw where prior to 2026.1.30, a function allows arbitrary file paths and an agent can read any file on the system by outputting a MEDIA path, enabling exfiltration to the user/channel. (NVD)
This interacts with reasoning leakage in a nasty way:
- a reasoning leak can reveal file paths worth targeting
- a channel leak can become an exfiltration mechanism if file-read primitives exist
- it strengthens the case for output sanitization plus strict tool permissions
CISA also lists this CVE in its vulnerability summary, which is a useful signal for defenders tracking authoritative prioritization. (CISA)
CVE-2026-26329, browser tool upload path traversal and local file read, note on NVD sync
There is a CVE record for CVE-2026-26329 describing a path traversal in the browser tool upload action that allows authenticated attackers to read arbitrary files from the gateway host prior to version 2026.2.14. (OpenCVE)
At the time of writing, NVD’s page may show “CVE ID Not Found,” which typically reflects database synchronization timing rather than absence of the underlying record. (NVD)
Again, the tie-in is straightforward: if your system can read files and you leak internal operational context into a chat surface, you’ve blurred confidentiality boundaries at both the tool layer and the output layer.
ClawJacked, websites hijacking local agents, patch urgency
Multiple security outlets report a high-severity issue dubbed ClawJacked that allowed malicious websites to take over local OpenClaw instances, with fixes released in the 2026.2.26 timeframe. (BleepingComputer)
This is not “reasoning leakage,” but it changes how you should think about the whole runtime:
- if a browser-originating attack can seize control, your agent’s outputs and traces become attacker-controlled
- reasoning leakage then becomes a vehicle for social engineering and data extraction, even if it started as a bug
Log and token exposure advisories
OpenClaw advisories also describe cases where tokens can be exposed in error messages and stack traces if logs are not redacted. (GitHub)
That reinforces an uncomfortable truth: you have to defend every surface where text can escape—chat, UI, logs, crash reports, and support bundles.
Continuous assurance, make “no reasoning leakage” a property you test
If you operate OpenClaw in any serious environment, treat “no internal reasoning leaking” as a regression-tested property.
Use OpenClaw’s built-in security audit regularly
OpenClaw’s security docs explicitly recommend running openclaw security audit (including deep and fix modes) especially after changing config or exposing network surfaces. (OpenClaw)
At a minimum, build a routine like:
openclaw security audit
openclaw security audit --deep
Then wire the output into your operational workflow, just like you would for infrastructure drift.
A simple channel-level test matrix
Build a basic test matrix and run it after every upgrade:
| Channel | Test prompt | Expected | Failure signature |
|---|---|---|---|
| Discord | prompt that triggers multi-step tool usage | only final answer | “The user is…”, “Reasoning:…”, tool narration |
| Telegram | prompt that triggers planning | only final answer | separate “Reasoning:” message (GitHub) |
| prompt that triggers planning | only final answer | “[openclaw] Reasoning:” message (GitHub) | |
| Webchat | /new or /reset | no system prompt shown | system greeting prompt visible (GitHub) |
Add a secret redaction layer, even if you “don’t log secrets”
The point is not to rely on perfect upstream hygiene. The point is to have a final failsafe that blocks secrets when they accidentally appear.
Be conservative with patterns, measure false positives, and ensure you redact before sending to third-party platforms.
Where Penligent fits, only when it’s natural
If you’re a security team validating an OpenClaw deployment, the hardest part is rarely “finding a bug.” It’s proving a control still holds after upgrades, model swaps, and configuration drift. A practical way to reduce that verification load is to treat the agent runtime like any other high-value target and continuously test its exposure: gateway reachability, known CVE boundaries, and whether sensitive artifacts can escape into chat surfaces.
Penligent can be used in that verification posture: automate checks around OpenClaw’s externally reachable surfaces, confirm patch boundaries for publicly documented issues, and generate evidence-grade outputs that answer “are we still safe after this change” rather than relying on gut feel. If you’re already tracking OpenClaw’s security boundary shifts, Penligent’s prior writeups on marketplace hardening and security-boundary interpretation provide useful context for building those tests into a repeatable practice. (Penligent)
Conclusion, what to do next if you searched “openclaw internal reasoning leaking”
- Confirm which channel paths are leaking and whether it’s structured
reasoningforwarding, UI rendering, or multi-message assembly. (GitHub) - Contain immediately: disable reasoning/verbose in public rooms, reduce exposure, rotate what might be compromised. (OpenClaw)
- Fix durably: enforce final-only output at the last boundary, add regression tests, and monitor for leak signatures. (GitHub)
- Harden like a privileged service: isolate the runtime, keep the gateway off untrusted networks, and assume drift will happen. (OpenClaw)
- Patch beyond “leak bugs”: keep up with CVEs that affect token handling and local file reads, because they amplify the consequences of any leak. (NVD)
Authoritative links and further reading
- OpenClaw security documentation, trust model, audit commands, reasoning and verbose guidance (OpenClaw)
- Discord reasoning leak issue report, root cause hypotheses about
reasoningfield forwarding (GitHub) - Webchat system prompt and thinking blocks rendered as user-visible text (GitHub)
- Telegram reasoning leakage report (GitHub)
- WhatsApp reasoning leakage report (GitHub)
- Bitsight analysis of exposed OpenClaw instances and probing reality (Bitsight)
- Zscaler architectural overview of OpenClaw gateway and channel surfaces (Zscaler)
- Microsoft-linked warning coverage about isolation and treating agent runtimes as untrusted code execution (TechRadar)
- NVD entry for CVE-2026-25253, token sent during auto WebSocket connection (NVD)
- NVD entry for CVE-2026-25475, MEDIA path handling enables arbitrary local file read (NVD)
- CVE record for CVE-2026-26329, browser tool upload path traversal and local file read, plus NVD sync note (OpenCVE)
- ClawJacked reporting and patch-version context (BleepingComputer)
- Penligent, OpenClaw + VirusTotal and ClawHub supply-chain boundary context (Penligent)
- Penligent, OpenClaw 2026.2.23 security boundary interpretation (Penligent)