Meta did not pause work with Mercor because of a noisy bug report or a theoretical weakness. It paused while investigating a breach tied to a company that sits in a sensitive part of the AI production chain, and OpenAI told WIRED it was investigating whether proprietary training data had been exposed, while also saying user data was not affected. That fact pattern matters because Mercor is not just another SaaS vendor in a procurement spreadsheet. WIRED described it as one of the firms AI labs use to generate bespoke, proprietary datasets through large networks of contractors, and Mercor’s own research pages say it develops benchmarks, evaluation environments, and large-scale human datasets for frontier AI work. (WIRED)
That is why the incident changed the conversation. If you still define AI security as prompt injection, jailbreaks, tool abuse, and output filtering, you are looking at the model application layer while a more consequential fight is happening inside the model production layer. Mercor told TechCrunch it was one of thousands of companies affected by the broader LiteLLM compromise. The story is not just that a Python package was poisoned. The story is that a package compromise reached into a company involved in creating and evaluating the data that helps frontier labs improve model behavior. (TechCrunch)
The uncomfortable lesson is simple. Many AI teams are trying to defend the thing users touch while under-defending the chain that makes the thing valuable in the first place. OWASP’s current GenAI risk material treats supply chain risk as broader than libraries alone, extending to training data, models, and deployment platforms. Government guidance from NSA and partner agencies makes the same move from a different angle, calling out trusted revisions, provenance, and trusted infrastructure as core AI data-security practices. The Mercor case makes that abstract guidance feel concrete. (OWASP Gen AI Güvenlik Projesi)
Mercor and LiteLLM exposed the wrong threat model
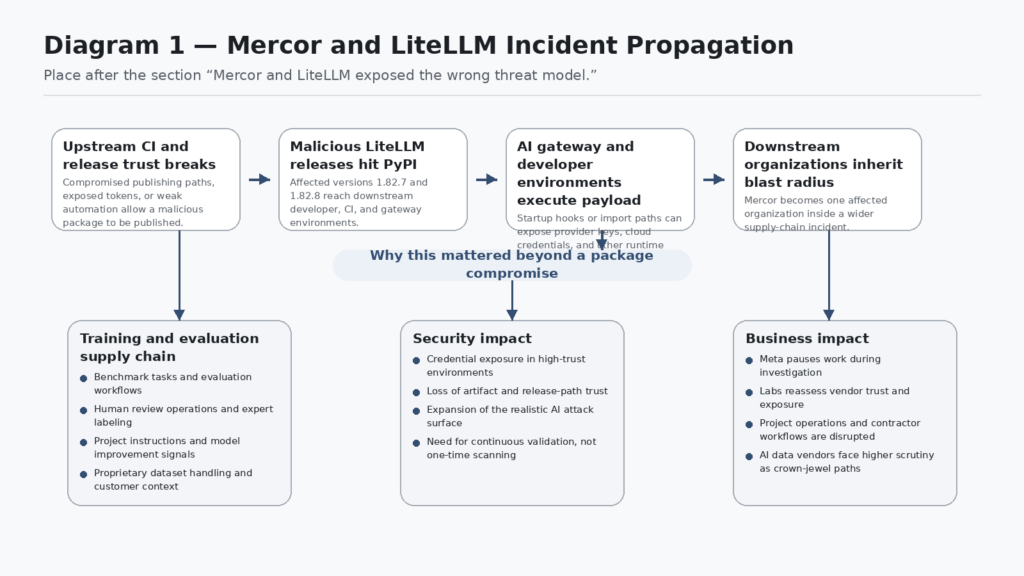
The first mistake is treating Mercor as if it were only a recruiting or staffing brand. Mercor’s own materials say it develops benchmarks, evaluation environments, and large-scale human datasets, and frames those outputs as part of frontier post-training and evaluation work. WIRED reported that Mercor is one of the firms OpenAI, Anthropic, and other labs rely on to generate training data, and that the data involved is kept highly secret because it reveals meaningful details about how models are trained. That makes the company part of an AI lab’s model-manufacturing process, not just an operational vendor on the side. (Mercor)
That distinction is what elevates the breach from a vendor incident to a supply-chain case study. If an attacker lands in a payroll processor, the likely questions are legal exposure, privacy exposure, and business continuity. If an attacker lands in a company handling benchmark design, human evaluation, and proprietary training tasks, the questions become different. What instructions were exposed. Which evaluation tasks were visible. Which customers or internal project names were recoverable. Which model-improvement workflows could be reconstructed. Which future safety or capability priorities could be inferred. WIRED explicitly noted that AI labs worry this kind of data can reveal how they train models, even if it remains unclear how much practical advantage a competitor would gain from the exposed material. (WIRED)
That uncertainty is important. Good security writing should not oversell what is known. Public reporting does not yet establish the full scope of what data Mercor lost, nor does it prove that a rival lab could directly reproduce another lab’s post-training recipe from the breach. But the incident does establish something less dramatic and more actionable: adversaries are now reaching into the ecosystems that create expert data, manage contractor workflows, and power evaluation operations for frontier AI programs. That is enough to change how a serious defender scopes AI red teaming. (WIRED)
The attribution story also deserves restraint. WIRED reported that actors using the Lapsus$ name claimed the Mercor breach, but researchers interviewed there said the LiteLLM link makes TeamPCP or a related actor more likely. Mercor, in its statement to TechCrunch, tied its incident to the LiteLLM supply-chain attack and said it was one of many affected organizations. That is the honest state of the record: the public claims were noisy, but the strongest technical thread leads through the LiteLLM compromise and the broader TeamPCP campaign. (WIRED)
What the LiteLLM compromise actually changed
LiteLLM is not interesting here because it is “an AI thing.” It is interesting because it sits near concentrated access. NHS England’s cyber alert describes it as a widely used API gateway that lets developers access hundreds of large language models. GitHub’s advisory for the incident marks versions 1.82.7 through 1.82.8 as affected and says anyone who installed and ran them should assume credentials in that environment may have been exposed. That is the security meaning of the event: the compromise hit a component that often lives next to provider keys, cloud credentials, logs, and routing logic. (NHS İngiltere Dijital)
The technical details are worth understanding because they explain why the blast radius was broader than a normal bad release. LiteLLM’s GitHub issues show a meaningful shift between the first public alarm and the later official timeline. The early issue focused on litellm==1.82.8 and a malicious litellm_init.pth file that would execute on any Python interpreter startup, with no import litellm required. The later official issue broadened the affected set to both 1.82.7 and 1.82.8, saying 1.82.7 embedded malicious logic in proxy_server.py and triggered on import litellm.proxy, while 1.82.8 added the .pth startup hook and therefore widened the trigger condition. That progression is a reminder that early incident reporting can be incomplete even when it is technically sound. (GitHub)
GitHub’s reviewed advisory adds two more operationally important facts. First, it says the malicious releases were uploaded to PyPI after API-token exposure from an exploited Trivy dependency. Second, it lists no patched versions in the advisory metadata, even though LiteLLM later said it released a safe v1.83.0 through a rebuilt CI/CD pipeline. That mismatch is instructive. Supply-chain response often moves through incident posts, emergency GitHub issues, and registry cleanups before structured advisory metadata fully catches up. A mature defender reads all three, not just one feed. (GitHub)
LiteLLM’s own incident update says the affected versions were removed from PyPI and that the project later released a safe v1.83.0 through a new CI/CD v2 pipeline with isolated environments, stronger security gates, and safer release separation. The follow-up town hall notes three contributing factors in the original failure: a shared CircleCI environment, static release credentials in environment variables, and an unpinned Trivy dependency in the security scanning component. Those are not AI-native mistakes. They are supply-chain mistakes in an AI stack. That is exactly why this case matters beyond LiteLLM itself. (LiteLLM)
NHS guidance summarized the practical outcome with unusual clarity. The compromised LiteLLM packages could exfiltrate secrets, establish persistence, and execute on every Python invocation in the affected environment. That means local laptops, ephemeral CI runners, test boxes, bastion-like shared environments, and centralized AI gateways all belonged in the response scope. If you think only in terms of “did production import the package,” you are already behind. (NHS İngiltere Dijital)
Why AI supply chain security is different from ordinary package hygiene
Traditional software supply-chain thinking usually begins with a dependency tree and ends with a patched version. That is useful, but it is not enough for AI systems. OWASP’s GenAI security project explicitly describes LLM supply-chain risk as spanning the integrity of training data, models, and deployment platforms, not just ordinary code dependencies. The older OWASP LLM Top 10 wording made the same point in a simpler form: compromised components, services, or datasets can undermine system integrity and cause data breaches or system failure. In AI systems, the boundary of “what counts as the software supply chain” is wider because data and human processes shape the behavior of the system itself. (OWASP Gen AI Güvenlik Projesi)
Government and standards guidance now reflects that wider boundary. The NSA’s 2025 AI data-security announcement emphasizes digital signatures for trusted revisions, data provenance, and trusted infrastructure across the AI lifecycle. The joint AI data-security guidance also explicitly calls out the data supply chain during planning and TEVV work. NCSC’s secure AI development guidance goes even further structurally, dividing AI security into secure design, secure development, secure deployment, and secure operation and maintenance, and saying security must be treated as a core requirement throughout the system lifecycle. NIST’s SSDF fills in the software side by defining a core set of high-level secure development practices that can be integrated into existing SDLCs. (National Security Agency)
Put those documents together and a more accurate AI supply-chain model appears. It includes at least five interlocking paths. There is the code path, which includes libraries, container images, actions, build tools, and registries. There is the data path, which includes pretraining data, fine-tuning corpora, eval tasks, prompts, rubrics, and retrieved knowledge sources. There is the control path, which includes gateways, key management, routing logic, tool bridges, and policy enforcement. There is the human path, which includes contractors, annotators, reviewers, ops staff, and vendor admins. And there is the publication path, which includes CI/CD, artifact signing, registry upload, and version pinning. The Mercor case matters because it touched more than one of those paths at once. (WIRED)
That is also why many AI security programs feel oddly incomplete. They spend heavily on model-application abuse cases such as indirect prompt injection and tool misuse, but far less on whether training vendors can leak sensitive task structures, whether gateway dependencies can harvest credentials, whether release paths prove artifact provenance, or whether contractor portals reveal project metadata across customers. Those are all parts of the same trust system. The user-facing model is only the last mile. (OWASP Gen AI Güvenlik Projesi)
AI training data vendors sit on a crown jewel path
A useful way to think about Mercor is as a company that lives where human expertise becomes machine capability. Mercor’s research site says it produces benchmarks, eval environments, and large-scale human datasets for frontier AI work. WIRED reports that AI labs keep those datasets highly secret because they are ingredients in valuable model development. That combination makes the surface unusually attractive. It is not just a place where data exists. It is a place where judgment, task framing, and domain expertise are converted into assets that shape what a model learns to do. (Mercor)
Attackers do not need full weights or direct access to a model-training cluster to gain leverage from that position. Access to project names, task types, scoring criteria, workflow instructions, benchmark design choices, or internal separation between customer programs can already be valuable. It can reveal where a lab is investing, what tasks it thinks matter, which domains are receiving expert attention, or how closely it is trying to align a model with particular enterprise work. Even where the exact competitive value is uncertain, the exposure has immediate business effects. Meta paused work. Other labs reevaluated relationships. Contractors tied to Meta projects reportedly could not log time during the pause. That is operational damage, not just theoretical exposure. (WIRED)
This is one of the places where AI security differs from ordinary SaaS security in practice. A typical back-office vendor might hold invoices, employee records, or product telemetry. A training-data vendor can hold traces of the future capability roadmap of a model organization. The models may still be safe. User data may still be untouched. But the manufacturing process can still be partially revealed. Security programs that measure success only in terms of customer-record exposure are missing the category. (WIRED)
The table below is a synthesis of the Mercor reporting, LiteLLM incident material, OWASP’s supply-chain framing, and AI lifecycle guidance. It is designed as a working map for defenders, not as a taxonomy exercise. (WIRED)
| AI supply chain layer | What it stores or controls | What recent incidents showed | Why ordinary scanning misses it | What to validate continuously |
|---|---|---|---|---|
| Package registries and libraries | Executable artifacts installed by developers and CI | LiteLLM showed malicious releases can run before ordinary application logic even starts | SBOMs and version checks alone do not prove artifact trust | Registry provenance, advisory feeds, wheel inspection, install-path hunting |
| CI actions and security tools | Build, scan, release, and secret access | Trivy and tj-actions showed a single compromised workflow component can expose secrets broadly | Teams trust tags, bots, and “security tooling” by default | SHA pinning, job isolation, least-privilege tokens, secret scope review |
| AI gateways | Provider keys, routing, cost controls, logs, tenant context | LiteLLM concentrated exactly the secrets attackers want | Gateway software often looks like plumbing, not a crown jewel | Key exposure tests, log boundary tests, multi-tenant isolation, egress review |
| Training data vendors | Tasks, rubrics, evals, customer project metadata | Mercor showed model-manufacturing data can create business-level fallout | These surfaces are often scoped as vendor ops, not product security | Project isolation, metadata exposure testing, access separation, evidence handling |
| Contractor and reviewer portals | Human task execution, project instructions, work allocation | A paused AI project can leave a visible trail of who was working on what | Security teams may not treat labor platforms as offensive test targets | Cross-project visibility tests, role-based access review, shared storage checks |
| Release pipelines | Publisher identity, artifact upload, version trust | LiteLLM and Trivy showed repo history can diverge from what gets shipped | Teams often verify source more than publication | Trusted publishing, attestations, artifact-policy enforcement, reproducible release review |
| AI data lifecycle controls | Provenance, trusted revisions, TEVV data quality | Joint AI data-security guidance stresses data supply chain and provenance | AppSec tools rarely model data lineage well | Signature checks, lineage auditing, drift monitoring, access change review |
Continuous AI red teaming starts where package scanners stop
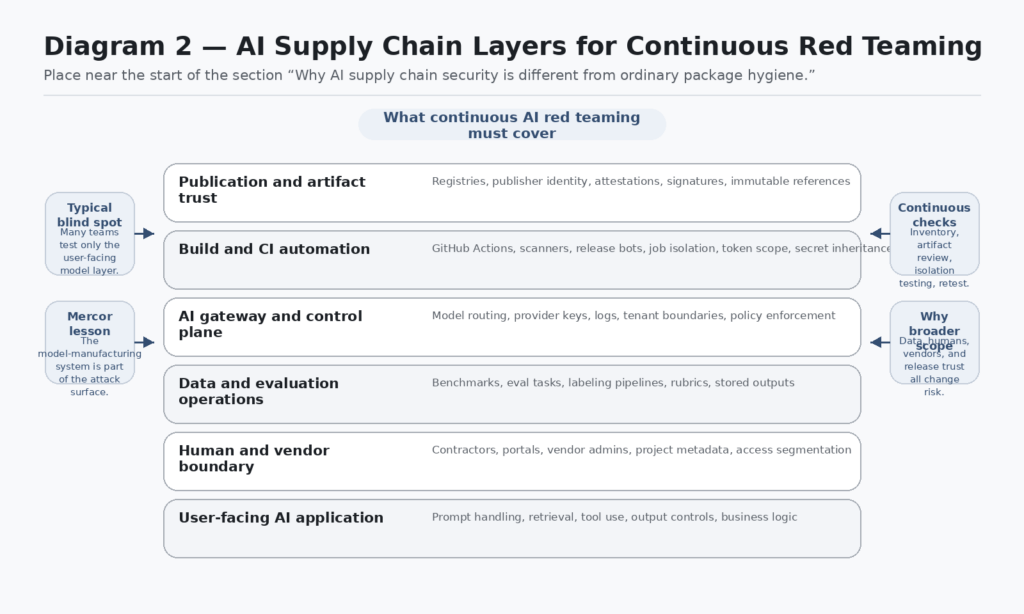
The phrase continuous AI red teaming is often used loosely. In this context, it should mean something precise: a program that repeatedly validates the high-change, high-trust parts of an AI system and its supporting supply chain, rather than running one-time abuse tests against the model interface and calling the result “coverage.” Mercor and LiteLLM both point in that direction. Neither case is well described by a quarterly pentest. The danger window was created by rapid trust decisions inside package installation, build automation, and vendor relationships. (WIRED)
NCSC’s lifecycle framing is useful here because it keeps the discipline honest. Secure design asks what you trust and why. Secure development asks how you build and document it. Secure deployment asks how you release it without compromise. Secure operation and maintenance asks whether you can monitor, update, and respond as the environment changes. A continuous AI red-team program should align to those same stages, because AI systems fail through lifecycle drift more often than through a single static weakness. (NCSC)
That leads to a different red-team objective function. The goal is not only to find an exploit chain. The goal is to falsify unsafe trust assumptions continuously. Can an unpinned dependency become executable in the wrong place. Can a moved action tag change what your CI runs. Can a vendor worker see project metadata outside their scope. Can a shared gateway leak another tenant’s tokens or logs. Can a release path publish something your source-review process never saw. These are red-team questions because they require adversarial validation. But they are also engineering questions because the fixes live in release, identity, and workflow design. (Aqua)
The useful mental shift is from “test my model” to “test my model-manufacturing system.” Prompt injection and unsafe tool use are still important. OWASP keeps them near the top for a reason. But Mercor makes clear that you can lose strategic ground before an attacker ever reaches your model prompt boundary. If the eval vendor, gateway dependency, CI action, or publication path is compromised, the red team should have had those trust edges in scope already. (OWASP)
Build an AI supply chain map before you write another detection rule
Most teams try to detect incidents before they can even describe their AI supply chain in plain language. That is backwards. Your first deliverable should be a map of trust edges, not a dashboard.
Start with the dependency edge. Which package managers, registries, actions, container sources, and scanners participate in your build and runtime environments. For each, note whether the organization trusts tags, digests, attestations, or repository history, and whether installs happen only in CI or also on laptops, notebooks, shared bastions, and ad hoc research boxes. Mercor’s statement to TechCrunch that it was one of thousands affected by the LiteLLM incident is a reminder that downstream victimhood often begins as ordinary dependency consumption. (TechCrunch)
Then map the control edge. Where do model-provider credentials live. Where do routing policies live. Which gateways or proxies hold multi-provider keys, budget rules, or audit logs. The LiteLLM incident mattered because a gateway package often sits where providers, cloud, logs, and tool integrations all meet. GitHub’s advisory explicitly tells anyone who installed and ran the malicious versions to assume available credentials were exposed. That should immediately elevate any gateway-like component into crown-jewel territory during scoping. (GitHub)
After that, map the human edge. Which vendors provide data annotation, eval operations, or expert review. Which contractor systems expose project descriptions, attachments, or client identifiers. Which workflows let one operator infer another program’s existence. The Mercor reporting makes this concrete because the business fallout ran through project staffing and customer reassessment, not just through raw technical IOCs. If you do not red-team those boundary systems, you have left a large share of the AI production chain untested. (WIRED)
Finally, map the publication edge. Which identities are allowed to publish packages, images, models, prompts, workflow definitions, or gateway config. Are those identities short-lived or long-lived. Can release artifacts be pushed outside the visible CI/CD path. LiteLLM’s official issue said the malicious 1.82.7 and 1.82.8 releases were uploaded directly to PyPI and were never part of the official GitHub release flow. That is exactly the kind of gap a supply-chain map should make impossible to ignore. (GitHub)
Hunt the LiteLLM blast radius in repos, environments, and artifacts
The first technical step after scoping is inventory. Not every team needs a full IR platform to answer the first order questions. A read-only sweep that checks lockfiles, requirements, site-packages, and local virtual environments will usually tell you whether you need to escalate.
The shell example below is intentionally conservative. It does not delete anything or modify the environment. It searches for risky version references, suspicious .pth artifacts, and a few obvious indicators that matter because the incident involved automatic execution from a .pth file and credential harvesting at Python startup. The rationale for checking .pth files is grounded in the LiteLLM incident reporting itself. (GitHub)
#!/usr/bin/env bash
set -euo pipefail
echo "== Search for vulnerable LiteLLM pins =="
grep -RInE 'litellm(==|>=|~=|<=)?1\.82\.(7|8)\b' . \
--include='requirements*.txt' \
--include='pyproject.toml' \
--include='poetry.lock' \
--include='Pipfile.lock' \
--include='uv.lock' 2>/dev/null || true
echo
echo "== Search installed packages in common Python locations =="
find "${HOME}" /usr/local /opt -type d \( -name "site-packages" -o -name "dist-packages" \) 2>/dev/null | while read -r pkgdir; do
if ls "${pkgdir}"/litellm-* 1>/dev/null 2>&1; then
echo "[+] Found LiteLLM under ${pkgdir}"
ls -1 "${pkgdir}"/litellm-* || true
fi
done
echo
echo "== Search for suspicious .pth files =="
find "${HOME}" /usr/local /opt -type f -name "*.pth" 2>/dev/null | while read -r f; do
if grep -Eq 'subprocess\.Popen|base64\.b64decode|exec\(' "$f" 2>/dev/null; then
echo "[!] Suspicious .pth candidate: $f"
sed -n '1,5p' "$f"
fi
done
echo
echo "== Search shell history and repo files for known-bad versions =="
grep -RInE 'pip(3)? install .*litellm(==|>=|~=|<=)?1\.82\.(7|8)\b' "${HOME}" 2>/dev/null || true
If you mirror packages internally or preserve wheels in artifact storage, inspect the artifact directly. One of the most valuable technical details in the LiteLLM reporting was the shift from import-triggered behavior to Python-startup-triggered behavior via a .pth file. That means artifact inspection is not optional if you are trying to determine whether your internal mirror ever distributed the malicious release. (GitHub)
import sys
import zipfile
from pathlib import Path
def inspect_wheel(path: str) -> None:
wheel = Path(path)
if not wheel.exists():
raise FileNotFoundError(wheel)
with zipfile.ZipFile(wheel) as zf:
names = zf.namelist()
pth_files = [n for n in names if n.endswith(".pth")]
print(f"Wheel: {wheel.name}")
print(f"PTH files: {pth_files or 'none'}")
for p in pth_files:
data = zf.read(p).decode("utf-8", errors="replace")
print(f"\n--- {p} ---")
print(data[:500])
record_files = [n for n in names if n.endswith("RECORD")]
for record in record_files:
record_data = zf.read(record).decode("utf-8", errors="replace")
suspicious = [
line for line in record_data.splitlines()
if ".pth" in line or "proxy_server.py" in line
]
if suspicious:
print(f"\n--- suspicious RECORD entries from {record} ---")
for line in suspicious:
print(line)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python inspect_wheel.py /path/to/package.whl")
sys.exit(1)
inspect_wheel(sys.argv[1])
A common response failure at this stage is to search only production hosts. Do not do that. GitHub’s advisory says anyone who installed and ran the package should assume credential exposure. The LiteLLM issues and NHS guidance both describe behavior that matters on developer laptops and CI hosts as much as on long-lived services. For this class of incident, your first-order assets often live where engineers test and publish, not where end users connect. (GitHub)
Prove your release path is trustworthy
The most durable lesson from LiteLLM and Trivy is that source review and artifact trust are not the same control.
LiteLLM’s official issue says the malicious PyPI releases never came through the project’s official GitHub CI/CD and that GitHub releases only went up to v1.82.6.dev1. The artifact reached users anyway. In other words, repository history and registry reality diverged. That is exactly the kind of failure defenders tend to underestimate because teams are culturally trained to review commits, pull requests, and tags more than package uploads, registry state, or publisher identity. (GitHub)
PyPI’s own documentation provides a clear direction for fixing part of that problem. It says ordinary API tokens are long-lived and can be abused until manually revoked if stolen, while Trusted Publishing avoids that by minting automatically expiring tokens. PyPI’s attestation documentation adds another important detail: attestations are currently supported for identities such as GitHub Actions, GitLab CI/CD, and Google Cloud. That means Python maintainers now have an increasingly realistic path to make publication trust more machine-verifiable instead of leaving it on the honor system of long-lived secrets. (PyPI Docs)
GitHub’s guidance on third-party actions makes the same philosophy concrete for workflow code. Pinning to a full-length commit SHA is, in GitHub’s words, the only way to use an action as an immutable release. GitHub also warns that tags can be moved or deleted if a bad actor gains access to the repository. The Trivy incident is a near-perfect demonstration of that risk: Aqua says the attacker force-pushed existing version tags and injected malicious code into workflows organizations were already running, precisely because many pipelines used tags instead of immutable SHAs. (GitHub Docs)
A hardened workflow for high-trust AI infrastructure should reflect those facts directly. Pin actions. Restrict token permissions. Use OIDC for cloud access instead of storing long-lived cloud credentials. Keep build, scan, sign, and publish in separated trust zones where possible. Treat “security tools” as dependencies that require the same suspicion as any other third-party code. LiteLLM’s postmortem on shared CI environments and static credentials is the warning label on that whole design space. (GitHub Docs)
A minimal GitHub Actions example looks like this:
name: release-python-package
on:
push:
tags:
- "v*"
permissions:
contents: read
id-token: write
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout source
uses: actions/checkout@8ade135a41bc03ea155e62e844d188df1ea18608
- name: Set up Python
uses: actions/setup-python@42375524f3c5b80b6e5d5f6f8f6d6f0e3dcf7d7d
with:
python-version: "3.12"
- name: Install build tooling
run: |
python -m pip install --upgrade pip
pip install build
- name: Build sdist and wheel
run: python -m build
- name: Publish to PyPI using Trusted Publishing
uses: pypa/gh-action-pypi-publish@c9e8d7b0e6a0c3d30b3d6a1c23cf0b9b95b4c5a6
That YAML is not a silver bullet. It will not save you from every compromised dependency or every registry-side problem. But it does address three concrete weaknesses exposed by the recent incidents: trust in mutable references, overpowered tokens, and overreliance on long-lived publish secrets. (GitHub Docs)

The Trivy case proves that security tools are part of your attack surface
A lot of teams still mentally categorize security tooling as “protective infrastructure,” which leads them to give it excessive privilege and reduced scrutiny. The Trivy compromise should end that habit.
Aqua’s incident update says the attacker force-pushed 76 of 77 trivy-action tags and all setup-trivy tags, and used a compromised service account to publish a malicious Trivy binary. Aqua explicitly notes that the attacker used existing version tags so pipelines already depending on those tags would continue to execute the changed code without an obvious signal. Microsoft’s response blog describes the same campaign as a CI/CD-focused supply-chain attack that weaponized a trusted security scanner and later expanded to KICS and LiteLLM. (Aqua)
Aqua’s GitHub discussion is even more operationally helpful. It provides exposure windows, identifies which references were safe, and says teams using compromised versions should treat pipeline secrets as compromised and rotate them immediately. It also notes that SHA-pinned references were outside the affected set for the GitHub Actions components. That is a rare example of a supply-chain lesson becoming visible in the response guidance itself. When the vendor tells you the immutable reference was the safe path, do not translate that into “best practice when convenient.” Treat it as incident-tested design. (GitHub)
This is where continuous AI red teaming should extend beyond the model again. If your AI program uses vulnerability scanners, code scanners, container-security tooling, policy-as-code runners, or eval orchestration in CI, then your red-team plan should include adversarial validation of those tools’ trust boundaries. What secrets do they inherit. What networks can they reach. Can one job inspect another. Can a moved tag silently alter what runs. Those are not compliance questions. They are pre-breach questions. (Aqua)
Related CVEs and advisories that explain the pattern
The Mercor and LiteLLM story becomes easier to reason about when you place it next to a few other supply-chain cases.
The first is not a CVE at all, but it behaves like one operationally: GitHub’s reviewed advisory GHSA-5mg7-485q-xm76 for LiteLLM. It marks versions 1.82.7 through 1.82.8 as affected, labels the severity critical, and says there is no known CVE for the advisory. The useful lesson is that supply-chain defenders cannot limit themselves to CVE feeds. GitHub advisories, project issues, incident blogs, and downstream scanner content often carry the earliest actionable signal for malicious-package events. (GitHub)
The second is CVE-2025-30066, the tj-actions/changed-files compromise. NVD describes it as a case where malicious code was introduced by moving trusted tags to a malicious commit, allowing attackers to discover secrets through workflow logs. GitHub’s advisory database classifies it under embedded malicious code. The relevance here is direct: this is another incident where the attacker did not need to break your app from the front door. They only needed to manipulate a trusted CI component and let your pipeline deliver the rest. (nvd.nist.gov)
The third is CVE-2024-3094, the XZ Utils backdoor. NVD’s description explains that the malicious code lived in upstream tarballs and build instructions rather than simply in the ordinary repository view teams expected to audit. That made it a classic artifact-versus-source trust gap. The reason it belongs in this discussion is not because XZ was “an AI package.” It belongs because LiteLLM showed the same structural lesson in a different ecosystem. A clean repository history does not prove a clean released artifact. A secure-looking build review is not enough if the thing users install can be altered or published through another path. (nvd.nist.gov)
The table below turns those incidents into a practical comparison.
| Incident | What was compromised | Why it matters here | Exploitation condition | What defenders should learn |
|---|---|---|---|---|
| GHSA-5mg7-485q-xm76 for LiteLLM | Real PyPI releases of a widely used AI gateway package | AI infrastructure often concentrates provider and cloud secrets | Install and run affected package versions | Watch advisory ecosystems beyond CVE, inspect artifacts, rotate by privilege concentration |
| CVE-2025-30066 | A popular GitHub Action with moved tags and malicious code | CI/CD trust can expose secrets without touching app code | Workflow uses compromised action references | Pin full SHAs, reduce workflow privileges, audit logs and token scope |
| CVE-2024-3094 | Upstream release artifacts and build path for XZ | Source review and artifact trust are not the same control | Downstream consumers build or install poisoned artifacts | Verify release provenance, not just source repo state |
These are not identical events, but they rhyme in the ways that matter for defenders. They all exploit the difference between what teams think they are trusting and what they are actually executing. That is why they fit naturally into an AI supply-chain article. Modern AI stacks are dependency-dense, automation-heavy, and unusually likely to concentrate high-value credentials in intermediary layers like gateways, scanners, and build systems. (GitHub)
Why prompt-injection-only AI red teaming is not enough
Prompt injection remains real and dangerous. OWASP keeps prompt injection and output handling near the top because hostile content can influence LLM behavior and compromise downstream systems. None of that changes. What changes after Mercor is the realization that model-behavior abuse is only one slice of AI security, and not always the slice that holds the most concentrated organizational risk. (OWASP)
A team can do beautiful prompt-injection testing on a polished assistant while missing the fact that its eval vendor leaks project metadata, its AI gateway dependency can run arbitrary code at Python startup, its CI uses mutable action tags, and its package publication still depends on a long-lived credential copied into a runner environment months ago. That is not a critique of prompt-injection testing. It is a critique of scoping. The wrong scope can produce a technically competent report on the wrong threat surface. (GitHub Docs)
The better framing is layered. Application-layer AI red teaming should continue to test prompt injection, tool misuse, output handling, privilege boundaries, data leakage, and unsafe automation. Supply-chain-layer AI red teaming should test publication trust, gateway dependencies, action pinning, secret inheritance, vendor project isolation, and contractor workflow exposure. The point is not to choose one over the other. It is to stop pretending one is a substitute for the other. (OWASP)
Test the human and vendor side of the AI supply chain
Mercor is a reminder that human labor systems are part of the AI attack surface. Many offensive programs still treat contractor ecosystems as procurement problems or insider-risk topics, not as first-class red-team targets. That is a mistake whenever human experts are being used to produce proprietary data, scoring decisions, eval traces, or workflow artifacts for model improvement. (WIRED)
The reason is straightforward. Human-facing platforms leak structure. A contractor portal can reveal customer names, project names, task categories, attachment formats, task-routing rules, or access patterns even if raw data exfiltration never occurs. A work-logging interface can reveal which projects are active, which are paused, and which teams are being reshuffled. WIRED’s reporting on Mercor’s paused Meta work and the internal “Chordus” context demonstrates how much sensitivity can sit in project administration alone. (WIRED)
A continuous red-team program should therefore include adversarial tests against the human side of the chain. Can a contractor infer another customer’s project existence or topic through shared UI elements. Can a low-privileged user enumerate task attachments or identifiers across programs. Can a reviewer see rubrics or sample outputs from programs outside their scope. Are cross-project storage locations or shared documents discoverable. Does task metadata reveal the customer, domain, or capability area implicitly. Those are offensive questions with direct strategic value. (WIRED)
This is also one place where scope discipline matters. The goal is not to harass vendors or simulate fraud against workers. The goal is to validate isolation boundaries in systems that are increasingly central to how models are evaluated and improved. If your organization buys expert labeling, eval operations, or RLHF-style data work, that vendor boundary is part of your AI production perimeter whether your architecture diagram admits it or not. (Mercor)
What defenders should change this quarter
The first change is procedural. Stop treating AI infrastructure dependencies as ordinary low-drama middleware. Gateways, agent runtimes, scanning steps, release bots, and eval tooling are high-consequence components because they often inherit the broadest access. Review them the way you review identity infrastructure, not the way you review a logging helper. LiteLLM’s advisory and Trivy’s incident record both justify that elevation. (GitHub)
The second change is architectural. Move publication and deployment toward identities that expire and can be tied back to a verified workflow context. PyPI’s Trusted Publishing model exists for a reason. If your AI-related Python packages still depend on long-lived publish tokens living in CI secrets, you are choosing a weaker control even though a stronger pattern is available. The same principle applies to cloud access from GitHub Actions through OIDC. (PyPI Docs)
The third change is operational. Enforce immutable references for third-party actions and reusable workflows wherever feasible. GitHub’s documentation is explicit that full-length commit SHAs are the immutable option, and Aqua’s Trivy guidance shows what happens when workflows trust mutable tags. Where pinning is difficult operationally, document the exception and treat it as risk acceptance, not as background noise. (GitHub Docs)
The fourth change is contractual and organizational. Add concrete AI supply-chain questions to vendor review and red-team scoping. Ask whether the vendor handles benchmark design, eval environments, expert data generation, project routing, or other artifacts that reveal model-development priorities. Ask how project isolation works. Ask what metadata low-privilege users can enumerate. Ask how contractor access is segmented. Mercor made that class of diligence impossible to dismiss as hypothetical. (WIRED)
The fifth change is analytic. Prioritize secrets by privilege concentration, not by asset owner. In a gateway or CI compromise, the most important question is not “which system was affected first.” It is “which credentials in that environment could unlock the broadest secondary access.” GitHub’s LiteLLM advisory and the incident writeups make that the right mental model. Rotate the keys that unlock the most, first. (GitHub)
Evidence matters more than dashboards
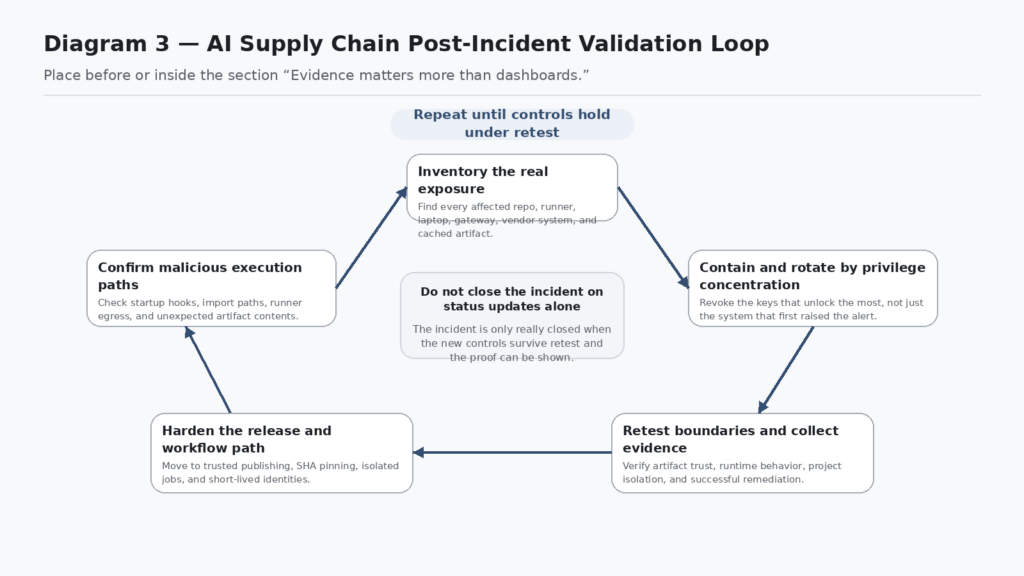
One of the quieter lessons from these incidents is that incident response and validation both fail when teams optimize for status pages over proof. A dashboard can say the package was removed. A ticket can say the secret was rotated. A status update can say a new safe version shipped. None of that proves your environment is clean, your workflow is isolated, or your release path is trustworthy again. (LiteLLM)
That is where an evidence-driven offensive workflow becomes more useful than generic reassurance. In practice, teams need retestable proof that their guardrails actually changed something: immutable references where mutable tags existed, short-lived publisher identities where long-lived secrets existed, vendor isolation that survives enumeration attempts, and gateway boundaries that hold under abuse. Penligent’s public material and writing are most relevant at this stage, where the job is controlled execution, human-reviewed scope, and evidence-backed verification rather than a chatty “AI security assistant” experience. Its homepage emphasizes operator-controlled agentic workflows, and its recent writing on AI red-team assistants and AI pentest reports centers on verifiable findings rather than glossy transcripts. (Penligent)
That distinction matters because AI security teams are under pressure to produce artifacts quickly. The temptation is to let an LLM summarize a breach, generate a remediation checklist, and call that maturity. The better path is slower in one specific sense: preserve the evidence chain. If a supply-chain event touched a gateway, a contractor system, or a release path, the output should include what was tested, what changed, what was revalidated, and what still remains uncertain. Penligent’s reporting-oriented material gets this right in spirit by treating the report as the end of a verifiable workflow rather than as a writing exercise. (Penligent)
The real lesson from Mercor is about model manufacturing security
The Mercor story will be misread if it gets filed under “AI startup got hacked.” That framing misses the bigger point. The incident sits at the intersection of expert data generation, evaluation operations, contractor workflows, gateway dependencies, and release-path trust. It shows that the systems used to manufacture model quality can be just as strategically sensitive as the systems used to serve model outputs. (WIRED)
That is why the phrase AI supply chain security is worth taking seriously now. It is not a fashionable rewrite of AppSec. It describes a real expansion of the trust boundary around AI systems. OWASP’s supply-chain framing, NCSC’s lifecycle model, NSA-led AI data-security guidance, PyPI’s identity and attestation work, GitHub’s SHA-pinning guidance, and the Mercor-LiteLLM-Trivy sequence all point in the same direction. AI security has to account for code, data, humans, workflows, and publication paths at the same time. (OWASP Gen AI Güvenlik Projesi)
The practical consequence is that continuous AI red teaming has to move upstream. Not away from model abuse testing, but upstream from it. Test the eval vendor. Test the gateway. Test the release bot. Test the registry trust path. Test the contractor portal. Test the action references. Test the evidence chain after the fix. If you only red-team the chatbot in front of the house, you will miss the workshop where the dangerous decisions are being made. (WIRED)
Further reading
- WIRED, Meta Pauses Work With Mercor After Data Breach Puts AI Industry Secrets at Risk (WIRED)
- TechCrunch, Mercor says it was hit by cyberattack tied to compromise of open source LiteLLM project (TechCrunch)
- GitHub Advisory Database, GHSA-5mg7-485q-xm76, Two LiteLLM versions published containing credential harvesting malware (GitHub)
- LiteLLM, Security Update, Suspected Supply Chain Incident (LiteLLM)
- LiteLLM, Security Townhall Updates (LiteLLM)
- Aqua Security, Update, Ongoing Investigation and Continued Remediation (Aqua)
- GitHub Docs, Secure use reference for GitHub Actions (GitHub Docs)
- PyPI Docs, Trusted Publishers ve Attestations (PyPI Docs)
- NCSC, Guidelines for secure AI system development (NCSC)
- NSA, AI Data Security guidance announcement (National Security Agency)
- NVD, CVE-2024-3094 (nvd.nist.gov)
- NVD and GitHub Advisory Database, CVE-2025-30066 (nvd.nist.gov)
- Penligent, LiteLLM on PyPI Was Compromised, What the Attack Changed and What Defenders Should Do Now (Penligent)
- Penligent, AI Red Team Assistant, What Holds Up in a Real Engagement (Penligent)
- Penligent, How to Get an AI Pentest Report (Penligent)
- Penligent homepage (Penligent)

