
Claude Code is easiest to misunderstand when people treat it as a better prompt box with shell access. Anthropic’s own public material describes something more specific. A harness, or scaffold, is the system that lets a model act as an agent by processing inputs, orchestrating tool calls, managing context, and returning results. Anthropic is explicit that when you evaluate an agent, you are evaluating the harness and the model together, not the model in isolation. Its Agent SDK is framed the same way: Claude Code as a programmable library with the same tools, agent loop, and context management that power Claude Code itself. (Anthropic)
That distinction matters more in offensive security than in almost any other application domain. Penetration testing is not a chat problem. It is a planning problem, a state-management problem, a verification problem, a reporting problem, and a safety problem at the same time. NIST SP 800-115 defines technical testing as a process that includes planning, conducting tests, analyzing findings, and developing mitigation strategies. The OWASP Web Security Testing Guide still treats web testing as a broad discipline covering information gathering, authentication, authorization, session management, input validation, business logic, and API testing. The OWASP AI Testing Guide, published in late 2025, extends that mindset into trustworthiness testing for AI systems. (معهد NIST CSRC)
The PentestGPT paper made the same point from the research side. Its authors found that large language models were often good at sub-tasks such as using security tools, interpreting outputs, and proposing next actions, but struggled to maintain the whole testing context over time. Their answer was not a longer prompt. It was a tripartite architecture with separate modules for reasoning, generation, and parsing, designed specifically to mitigate context loss. (arXiv)
That is where the Claude Code harness idea becomes useful for AI pentesting. The most important lesson is not that a coding agent can run commands. Plenty of systems can run commands. The lesson is that serious agent behavior comes from the surrounding system: the planning layer, the tool boundary, the approval model, the handoff artifacts, the verifier, and the evidence chain. Anthropic’s own long-running harness work makes this plain. Their public engineering posts describe context drift, “context anxiety,” structured handoffs, planner-generator-evaluator roles, sprint contracts, and the value of a separate evaluator that is more skeptical than the generator. (Anthropic)
If you carry that into pentesting, the question changes. It stops being “Can Claude Code do pentesting?” and becomes “What would a pentest harness look like if it borrowed the right ideas from Claude Code and adapted them to target-facing, evidence-first security work?” That is the architecture worth building.
From prompting to scaffolding
The fast way to explain the shift is this: a prompt asks for behavior, while a harness governs behavior.
In a naive AI pentest setup, the model gets a target, maybe a few tools, and a loose instruction like “find vulnerabilities.” Sometimes that works for toy tasks. On a real engagement it usually produces one of four bad outcomes. The first is tool thrash, where the model keeps invoking surface-level recon without converging on a concrete hypothesis. The second is brittle state, where it forgets what mattered three tool calls ago. The third is narrative inflation, where “this looks vulnerable” gets written up like a confirmed finding. The fourth is unsafe drift, where the system expands scope or executes actions that were never explicitly authorized. PentestGPT’s benchmark findings on context loss and Anthropic’s public writing on long-running agents point to the same core failure mode: the problem is not just reasoning quality, but whether the system around the model preserves direction and control. (arXiv)
Anthropic’s own best-practices guidance is remarkably blunt here. It says the highest-leverage thing you can do is give Claude a way to verify its work. Without clear success criteria, you become the only feedback loop. In code, that means tests, screenshots, or expected outputs. In pentesting, the translation is stronger: fresh sessions, replayable requests, role changes, browser state validation, and artifact capture. A pentest agent that cannot verify its own claims is not an autonomous tester. It is a hypothesis generator with a dangerous amount of confidence. (كلود)
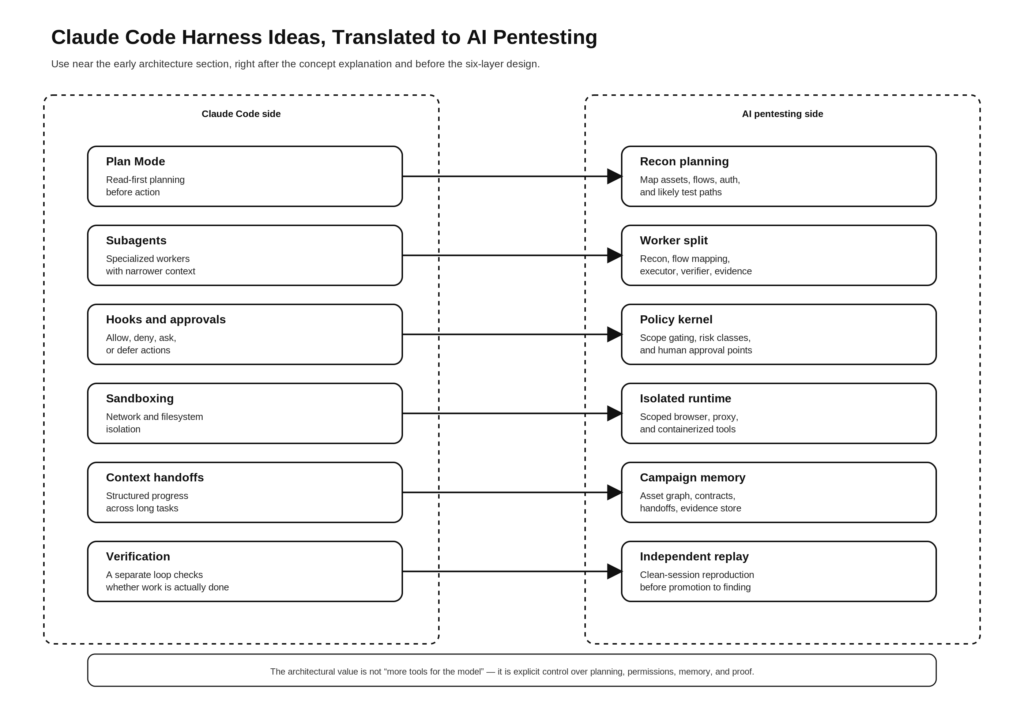
Claude Code also exposes a design pattern that security engineers should borrow almost verbatim: use safe, read-oriented planning up front, then escalate only when you have a bounded reason to do so. Plan Mode in the public docs is explicitly designed for read-only analysis and requirement gathering before any changes are made. In a pentest translation, that becomes recon-first planning: crawl, map, cluster, correlate, and decide what deserves an active check before any state-changing action is attempted. (مستندات كلود API)
The same logic applies to subagents. Anthropic’s docs describe custom subagents as specialized assistants with their own prompts, their own tool access, and their own context windows. That is not just a coding convenience. It is a good mental model for AI pentesting, because recon, business-flow understanding, exploit validation, and reporting are not the same job and should not share identical permissions or identical context. (مستندات كلود API)
The harness below is therefore not a clone of Claude Code. It is a translation.
What Claude Code public primitives become in AI pentesting
The mapping is straightforward once the task shape is clear.
| Claude Code primitive | What it means in Claude Code | AI pentesting translation |
|---|---|---|
| Plan Mode | Read-only analysis before edits | Read-only recon, asset mapping, and target planning |
| Subagents | Specialized assistants with distinct roles and tool access | Recon worker, flow mapper, executor, verifier, evidence writer |
| PreToolUse and PermissionRequest hooks | Policy controls before tool execution | Runtime gatekeeper for scope, risk class, rate, and approval |
| Sandboxing | Filesystem and network isolation for safer autonomy | Contained test runner, domain allowlists, egress controls, isolated browser and proxy |
| Context compaction and handoffs | Long-task continuity despite context limits | Campaign memory, session summaries, resumable engagements |
| Give Claude a way to verify its work | Tests and expected outputs improve reliability | Replay, diffing, multi-session confirmation, reproducible evidence |
| Auto mode deny-and-continue | If blocked, recover and try a safer path | If an active test is denied, fall back to passive or lower-risk validation |
This is a synthesis, but every row is grounded in Anthropic’s public material. Their docs and engineering posts describe Plan Mode as read-only analysis, subagents as specialized contexts, hooks as allow-deny-ask-defer control points, sandboxing as filesystem and network isolation, long-running harnesses as structured multi-agent systems with handoffs, and verification as the single highest-leverage improvement to agent reliability. (مستندات كلود API)
The rest of this article builds out the pentest version of that table.
Why AI pentesting needs more than a model
A penetration test is one of the worst possible tasks for a free-roaming single agent. The target changes under observation. Authentication state matters. Business logic matters. Environmental assumptions matter. A “success” can be false if it only works in a polluted session, only works with admin cookies already present, only works against a CDN artifact, or only appears because the agent interpreted a noisy response as proof.
The OWASP WSTG remains useful here because it forces the tester to think in broad attack categories rather than in isolated scanner hits. The AI Testing Guide extends that discipline to AI systems by treating evaluation as practical, structured trust testing rather than a vibe check. PentestGPT pushes in the same direction from another angle: real progress comes from decomposing the job and keeping a representation of state. (OWASP)
Anthropic’s long-running harness work adds a complementary lesson. The planner-generator-evaluator architecture improved outputs because the agents did not all do the same thing. The planner expanded short prompts into fuller specs. The generator built incrementally. The evaluator used direct interaction with the running app and enforced hard thresholds. Before each sprint, the generator and evaluator negotiated a contract for what “done” meant. That exact pattern is almost embarrassingly well suited to pentesting. (Anthropic)
In pentesting terms, the translation is obvious. The planner becomes a hypothesis compiler. The generator becomes an execution worker. The evaluator becomes an independent verifier. The sprint contract becomes an attack contract. The compaction and handoff system becomes campaign memory. The result is not “more agentic pentesting” in the abstract. It is a system that can move from signal to proof without quietly converting guesses into findings.
The six layers of an AI pentesting harness
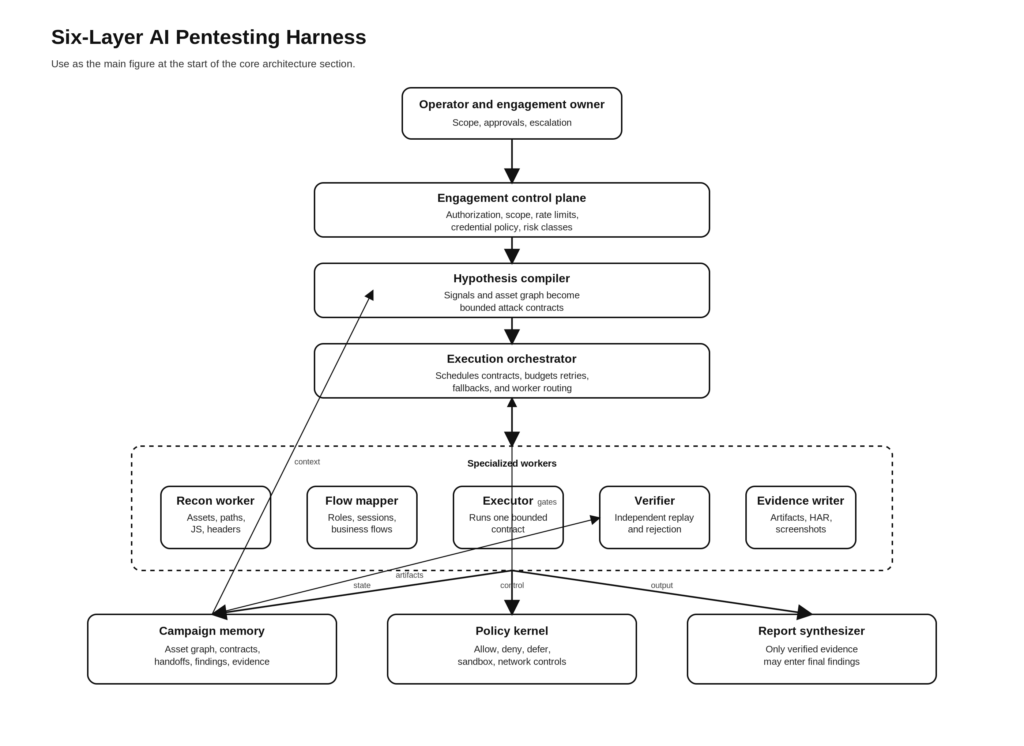
The architecture that follows is the design I would build if the goal were to borrow the strongest ideas from Claude Code and adapt them to authorized, evidence-first AI pentesting.
Layer one, engagement control plane
The harness begins before the first tool call. It begins with the engagement itself.
NIST SP 800-115 emphasizes planning as part of technical testing, not as paperwork outside the system. Anthropic’s trustworthy-agents framework says much the same thing in another vocabulary: keep humans in control, especially before high-stakes actions, and treat autonomy as something that must be bounded. Claude Code is described as read-only by default and approval-gated for modifying systems. For pentesting, that same logic should be encoded in a machine-readable engagement manifest that the runtime consumes on every turn. (معهد NIST CSRC)
A proper engagement control plane includes scope, authorization windows, test categories, disallowed actions, traffic budgets, target labels, credential boundaries, browser restrictions, proxy routing, and evidence retention rules. It also needs a classification of actions by risk. Passive reads and metadata collection are one class. Low-impact active enumeration is another. State-changing actions, credential use, file uploads, or any exploit-like validation should sit behind separate gates. The control plane is where “authorized pentest” stops being a sentence in a prompt and starts becoming runtime policy.
A minimal manifest might look like this:
engagement:
id: acme-web-2026-q2
authorized_by: security-team
window_start: 2026-04-10T09:00:00Z
window_end: 2026-04-17T23:00:00Z
scope:
domains:
- app.example.com
- api.example.com
exclude_paths:
- /payments/live/*
- /admin/billing/*
allowed_identities:
- anonymous
- low_priv_user
forbidden_targets:
- thirdparty.example.net
- *.internal.example.com
runtime:
max_rps: 2
browser_allowed: true
upload_tests_allowed: false
credential_rotation_required: true
network_allowlist:
- app.example.com
- api.example.com
- auth.example.com
risk_policy:
passive_recon: auto
low_impact_validation: auto
state_changing_actions: human_approval
exploit_like_execution: forbidden
external_callbacks: forbidden
reporting:
capture_har: true
capture_screenshots: true
redact_secrets: true
That example is simple, but the architectural point is larger. A pentest agent should never have to infer the scope of the engagement from English alone. The control plane should be parsed into hard runtime decisions. Anthropic’s hooks model is useful inspiration here because it formalizes decision points before tool execution, while their safety framework insists that humans retain control before high-stakes actions. (مستندات كلود API)
Layer two, hypothesis compiler and sprint contracts
The next layer translates observations into bounded work.
Claude Code’s long-running application harness used a planner to expand brief prompts into fuller product specs, then used generator-evaluator negotiation to decide what counted as a completed sprint. In pentesting, the equivalent is not a feature plan. It is an attack hypothesis with explicit test conditions. (Anthropic)
This matters because penetration testing is not just tool execution. It is hypothesis management. A tester sees a behavior, forms a theory, asks what would have to be true for that theory to matter, and then designs a check. The harness should make that explicit. Instead of telling the model “test auth,” the system should create a contract like: “This target appears to accept user-controlled object identifiers on three endpoints. Test whether authorization is enforced server-side across role transitions, using only low-privilege credentials, without mutating protected records.” That is work the model can execute. “Find something interesting” is not.
A practical attack contract has at least these fields:
{
"contract_id": "idor-orders-001",
"target": "<https://api.example.com/v1/orders/{id}>",
"goal": "Verify whether object-level authorization is enforced across user roles",
"preconditions": [
"Two low-privilege accounts with access to different order sets",
"Clean session for each replay"
],
"allowed_actions": [
"GET requests",
"Browser navigation",
"Session reset",
"Response diffing"
],
"forbidden_actions": [
"Record modification",
"Mass enumeration",
"External callbacks"
],
"success_signals": [
"Cross-account access to protected order data",
"Stable reproduction across two clean sessions"
],
"failure_signals": [
"Consistent authorization denial",
"Behavior only appears in polluted session state"
],
"required_evidence": [
"Request and response pair",
"Role mapping",
"Replay transcript",
"Screenshot if browser-visible"
],
"risk_class": "medium",
"budget": {
"max_requests": 20,
"max_duration_seconds": 600
},
"exit_condition": "Verified or rejected with reasons"
}
The contract does two things at once. It narrows the search space and raises the evidentiary bar. Anthropic’s public harness notes that the generator and evaluator negotiated a sprint contract before work began precisely because the evaluator needed a testable definition of done. The same discipline is even more valuable in security, where “done” is otherwise dangerously easy to fake. (Anthropic)
Layer three, specialized execution workers
Subagents are one of the most transferable ideas in the Claude Code stack. Anthropic describes them as specialized assistants for task-specific workflows and improved context management. That should immediately ring true to anyone who has done real pentesting. Recon, auth-flow mapping, exploit validation, and report writing are different jobs. They should not share the same prompts, tools, or authority. (مستندات كلود API)
A mature pentest harness should at minimum separate five execution roles.
The first is a recon worker. Its job is to discover and normalize surface area: hosts, paths, endpoints, parameters, JavaScript routes, login variants, headers, object stores, admin surfaces, and third-party dependencies. It should be heavily tool-using but low-privilege. It should not be allowed to “validate” findings in the reporting sense.
The second is a flow mapper. This worker is closer to a threat-modeling analyst than a scanner. It turns endpoint lists into behaviors. What identities exist? Where are transitions? Which actions are stateful? What object types appear in browser traffic? What hidden fields shape workflow decisions? The output is not a vulnerability claim. It is a structured graph of business behavior.
The third is a hypothesis executor. This is the worker that actually runs bounded active checks based on a contract. It should only get the tools and permissions required by that contract. Nothing more. Anthropic’s public documentation around subagents, permissions, and hooks strongly supports this style of limited delegation: use specialized contexts and restrict tool access to what each unit actually needs. (مستندات كلود API)
The fourth is a verifier. This worker must not be the same entity that executed the initial check. Anthropic’s long-running harness work is especially useful here because it argues that self-evaluation is weak and that a separate evaluator is easier to tune toward skepticism. For pentesting, that principle is not an optimization. It is a validity requirement. (Anthropic)
The fifth is an evidence writer. Its job is to convert the raw trace into artifacts another engineer can replay. That means request-response pairs, HAR snippets, screenshots, environment notes, role assignments, negative cases, and cleanup notes. If your harness merges this worker into the executor, evidence capture tends to become selective and messy.
You can add more roles later, but these five are enough to create a healthy separation of duties.
Layer four, independent verifier loops
This is the layer that decides whether the system is a pentest harness or a storytelling machine.
Anthropic’s best-practices page says clear verification criteria are the single highest-leverage improvement you can make. Their long-running application harness took that seriously by giving the evaluator Playwright access and hard thresholds. The evaluator could fail a sprint if any key criterion was not met. In security, the equivalent is simple to describe and hard to fake: a finding is not complete until an independent verifier can reproduce the relevant behavior under controlled conditions. (كلود)
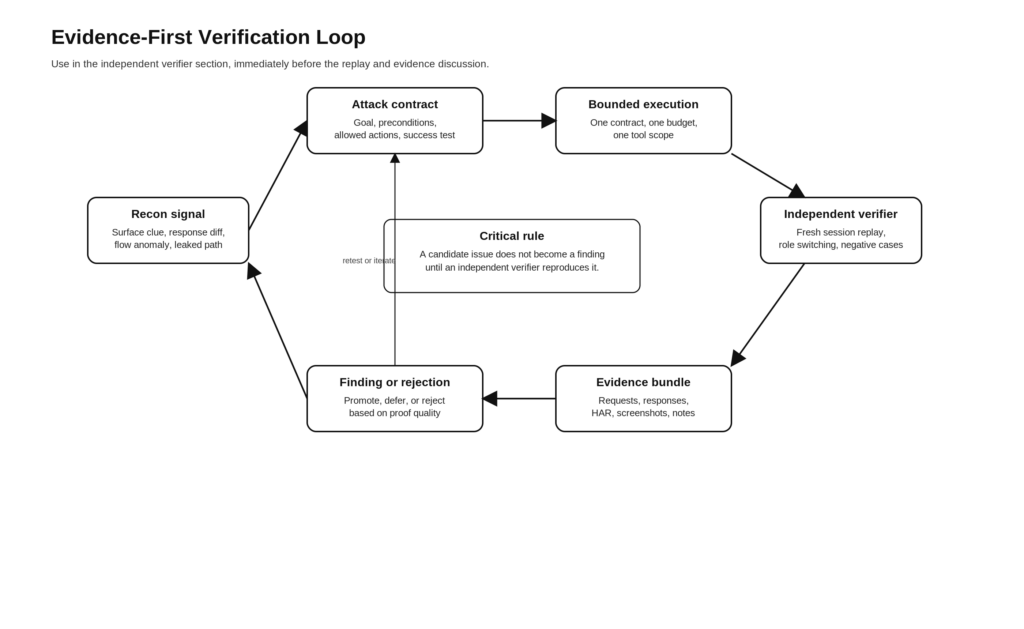
For web and API testing, an independent verifier usually needs to do some mix of the following:
- Reset the session and replay from clean state.
- Switch roles or identities and compare behavior.
- Confirm the result is not caused by cached client state or polluted cookies.
- Confirm the result is not a transient upstream issue, proxy artifact, or WAF anomaly.
- Capture negative cases so the report can explain what the issue is not.
- Capture enough evidence for a human to replay without trusting the model’s narration.
A small replay scaffold may look like this:
from dataclasses import dataclass
from typing import List, Dict
@dataclass
class ReplayCase:
name: str
session_profile: str
request_spec: Dict
expected_signal: str
@dataclass
class VerificationResult:
case_name: str
observed_signal: str
matched: bool
artifacts: List[str]
notes: str
def run_verification(cases: List[ReplayCase], runner) -> List[VerificationResult]:
results = []
for case in cases:
runner.reset_session(case.session_profile)
response = runner.send(case.request_spec)
observed = runner.classify_signal(response)
artifacts = []
artifacts.append(runner.save_request_response(case.name, response))
if runner.browser_visible(response):
artifacts.append(runner.save_screenshot(case.name))
results.append(
VerificationResult(
case_name=case.name,
observed_signal=observed,
matched=(observed == case.expected_signal),
artifacts=artifacts,
notes=runner.explain_difference(case.expected_signal, observed)
)
)
return results
The code is intentionally plain. The important point is procedural. Verification is a separate pass, not an afterthought. Anthropic’s own public writing on trustworthy agents also reinforces the control side of this: agents are valuable because they can act, but humans should remain in control before high-stakes decisions or actions. A pentest harness should treat promotion from “candidate issue” to “reportable finding” as one of those high-stakes transitions. (Anthropic)
This is also the point where a workflow-native offensive platform becomes easier to justify than a pile of tools wired together ad hoc. Penligent’s public materials keep returning to the same standard: signal is not enough, and a useful workflow is one that turns findings into verified impact, preserves a proof chain, and packages the result into editable reporting. Its homepage emphasizes scope locking, customizable actions, guided execution from signal to proof, and reporting, while recent technical posts emphasize adaptive testing, preserved state, and verified findings rather than narrated guesses. Whether a team uses that specific platform or not, the operating principle is exactly right: the report should be the end of the evidence chain, not the substitute for it. (بنليجنت)
Layer five, persistent memory and handoffs
One of the quiet strengths of Anthropic’s long-running harness work is that it treats state as a first-class engineering problem. Their posts describe two related techniques. One is context compaction, which keeps a session going by shortening history. The other is context reset plus structured handoff, which gives a fresh agent enough artifact state to continue work coherently. They note that compaction alone does not always solve drift and that structured handoffs can be essential. (Anthropic)
That maps almost perfectly to pentesting. A real engagement is rarely a single uninterrupted loop. Targets change. Sessions expire. Operators stop and resume. Credentials rotate. A meaningful harness therefore needs persistent, structured memory that is richer than chat history.
At minimum, the memory model should contain:
- an engagement manifest,
- an asset graph,
- a list of contracts and their status,
- a finding registry,
- an evidence store,
- a progress handoff,
- and a session summary log.
A simple directory layout is often enough:
campaign/
engagement.yaml
assets/
asset_graph.json
routes.json
identities.json
contracts/
001-auth-flow.json
002-idor-orders.json
findings/
candidates.jsonl
verified.jsonl
rejected.jsonl
evidence/
002-idor-orders/
replay_case_a.har
replay_case_b.har
browser.png
notes.md
progress/
handoff.md
latest_summary.json
sessions/
2026-04-11T0100Z.jsonl
2026-04-11T0900Z.jsonl
The key design choice is that the model never has to reconstruct the entire campaign from prose memory. Instead, the harness gives it typed state. That is exactly the lesson PentestGPT pointed toward with its Pentesting Task Tree and exactly the kind of structured artifact flow Anthropic relied on in long-running work. (arXiv)
This layer matters for auditability as well. A human reviewer should be able to answer simple questions without asking the model to remember anything. Which hypotheses were tested and rejected? Which ones were promoted? Which ones were blocked by policy? Which ones still need human approval? Which identities were used? Which evidence bundles are complete? If the answer to those questions only exists inside an agent transcript, the harness is not mature yet.
Layer six, policy kernel and runtime controls
Claude Code’s public security model is one of the clearest reasons it is useful as an architectural reference. Anthropic does not present tool use as a matter of trust alone. It presents tool use as something governed by approvals, hooks, sandboxing, and policy. The docs for hooks say PreToolUse can allow, deny, ask, or defer tool calls and can even modify tool input before execution. The hooks reference also warns that command hooks run with the full permissions of the system user. Their sandboxing post is equally clear that effective sandboxing requires both filesystem isolation and network isolation. Without network isolation, a compromised agent can exfiltrate sensitive files; without filesystem isolation, it can escape and regain network access. (مستندات كلود API)
For pentesting, this means the harness needs a policy kernel that sits outside the model and makes final decisions about what may happen. A useful pattern is to classify actions into four buckets.
Automatic actions are low-risk, in-scope reads and bounded probes.
Approval-gated actions are active checks that may change state or create noise.
Deferred actions are legitimate checks that need a human to answer a question first, such as whether a low-impact upload test is acceptable for this target.
Forbidden actions are everything outside the authorized envelope.
A small policy file can express this cleanly:
policies:
- name: passive-read
match:
tool: [Read, WebFetch, BrowserNavigate]
target_scope: in_scope
action_class: passive
decision: allow
- name: low-impact-api-validation
match:
tool: [HttpRequest]
method: [GET, HEAD]
target_scope: in_scope
rate_limit_ok: true
decision: allow
- name: state-changing-checks
match:
tool: [HttpRequest, BrowserAction]
method: [POST, PUT, PATCH, DELETE]
target_scope: in_scope
decision: defer
question: "This action may change application state. Approve?"
- name: external-callbacks
match:
destination_scope: external
decision: deny
reason: "Out-of-scope callback infrastructure is blocked"
- name: exploit-like-execution
match:
action_class: exploit_validation
decision: deny
reason: "Exploit-style execution is outside this engagement profile"
This is where Anthropic’s “deny-and-continue” idea becomes valuable. Their public description of auto mode says that when the classifier blocks an action, Claude should not simply halt; it should recover and try a safer path where one exists. In a pentest harness, that means a denied destructive action should trigger a fallback to passive confirmation, code-path analysis, role comparison, or human escalation rather than a dead stop. (Anthropic)
The policy kernel also needs to understand MCP-specific risk. The official MCP security guidance is unusually relevant to security teams because it does not talk in vague terms. It names confused deputy issues, token passthrough, SSRF, session hijacking, local MCP server compromise, and scope minimization as real attack surfaces. The MCP authorization spec also requires audience validation and explicitly rejects token misuse patterns that would blur security boundaries between services. (بروتوكول سياق النموذج)
A pentest harness that plugs into MCP tools but does not independently validate token audiences, enforce scope minimization, and separate upstream and downstream credentials is building on sand.
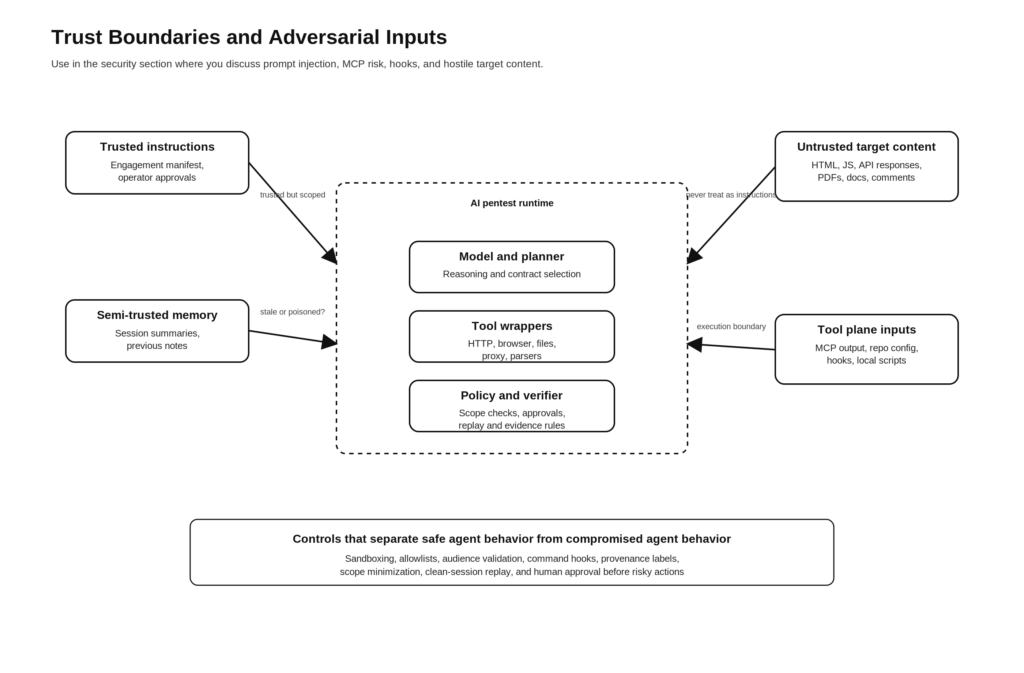
Why targets must be treated as adversarial inputs
The deepest mistake people make with agentic pentesting is assuming the target is the only thing under test. In reality, everything touching the harness can become an attack surface.
Anthropic’s browser prompt injection research says this plainly. When an agent browses the internet, every page is a potential attack vector. Prompt injection remains a major unsolved challenge, especially as agents take real-world actions, and Anthropic explicitly says the problem is not solved even with improved defenses. OWASP’s GenAI material says the same in more general terms: prompt injection can expose sensitive data, grant unauthorized access to functions, execute commands in connected systems, and manipulate decision-making. Indirect prompt injection is especially relevant when the model consumes external data such as pages, documents, or files. (Anthropic)
That has a direct implication for AI pentesting. The target response body is not just data. A JavaScript bundle, a DOM node, a PDF, a comment field, or a documentation page can all contain instructions designed to steer the model. So can a repository, a readme, a tool output file, or a mocked API response. The harness must therefore treat the target as adversarial input at every layer.
This changes how you design workers. The recon worker should not be allowed to reinterpret arbitrary page content as trusted instructions. The flow mapper should separate extracted observations from agent directives. The verifier should not trust executor-supplied commentary. The evidence writer should annotate where artifacts came from and whether they were generated from trusted or untrusted sources. Prompt injection is not an optional edge case. It is part of the normal threat model for agentic testing. (Anthropic)
It also changes how you think about tools. The MCP security guide does not just discuss tokens. It names local server compromise and scope minimization because the tool plane is part of the attack surface. Anthropic’s hooks documentation similarly warns that command hooks execute with the user’s full permissions. Once you combine tool access, command execution, browser access, memory, and repo-local configuration, the old line between “data” and “execution” starts to dissolve. (بروتوكول سياق النموذج)
A useful way to reason about this is to model four input classes.
| Input class | أمثلة | Primary risk | Required control |
|---|---|---|---|
| Trusted instructions | Engagement manifest, operator approvals, policy rules | Over-broad authorization or stale policy | Versioned policy, review, change control |
| Semi-trusted internal context | Notes, handoff summaries, prior evidence | Memory poisoning, stale assumptions | Structured schemas, provenance tags, expiry |
| Untrusted target content | HTML, JS, docs, PDFs, API responses | Indirect prompt injection, misdirection, false proof | Input labeling, sandboxed parsing, no implicit instruction following |
| Tool plane content | MCP outputs, hook inputs, repo config, local scripts | Command execution, token theft, confused deputy, SSRF | Tool allowlists, audience validation, container isolation, repo trust model |
The table is a synthesis, but it follows the threat patterns documented by Anthropic, OWASP, and MCP’s own official security guidance. (Anthropic)
The CVEs that make this architecture non-optional
High-level design becomes much less abstract when you look at what has already happened in adjacent agent systems.
Langflow CVE-2025-3248 and the myth of harmless helper endpoints
NVD describes CVE-2025-3248 as a code injection issue in Langflow versions prior to 1.3.0. The vulnerable endpoint was /api/v1/validate/code, and the flaw allowed a remote unauthenticated attacker to send crafted requests that execute arbitrary code. CISA later added the issue to its Known Exploited Vulnerabilities workstream. (NVD)
Why does that matter to a pentest harness article? Because it is a clean example of a failure many teams still underestimate. AI workflow products often contain “helper” or “validation” paths that feel like support functions rather than core execution surfaces. In practice, the thing named validate may be exactly where unsafe execution happens. A harness architect should learn two lessons from this. First, internal helper capabilities must be threat-modeled as execution boundaries, not convenience features. Second, policy and verification must cover supporting endpoints just as aggressively as the obvious ones. (NVD)
For defenders, the mitigation story is equally instructive. NVD points to fixed versions and vendor references. At the architecture level, the repair is not just “add auth.” It is also “stop assuming that code-validation features can safely process attacker-controlled inputs.” That is a design correction, not just a patch. (NVD)
Langflow CVE-2026-33017 and the danger of partial fixes
The later Langflow issue is even more revealing. NVD describes CVE-2026-33017 as an unauthenticated remote code execution flaw in versions prior to 1.9.0. The vulnerable endpoint, POST /api/v1/build_public_tmp/{flow_id}/flow, was intentionally unauthenticated for public flows, but accepted attacker-controlled flow data containing arbitrary Python code in node definitions and passed it to تنفيذ() with zero sandboxing. NVD explicitly notes that this issue is distinct from CVE-2025-3248. It was not the same bug resurfacing in the same endpoint. It was the broader execution model showing up somewhere else. NVD also records that the flaw entered CISA’s Known Exploited Vulnerabilities Catalog in March 2026. (NVD)
This is exactly the kind of lesson AI pentest harness builders should care about. A system can fix one dangerous endpoint and still retain the underlying pattern somewhere else. If your harness has multiple code paths that can transform untrusted data into tool invocations, browser actions, or shell commands, patching one surface is not enough. You need an architectural boundary. In Anthropic’s language, that means actual sandboxing and permission layers. In pentest-harness language, it means a policy kernel outside the model and a runtime that never treats “public” or “helper” surfaces as automatically low risk. (Anthropic)
Claude Code repo-level configuration issues and the new execution boundary
The most relevant cautionary case for Claude Code itself came from Check Point Research in February 2026. Their write-up says malicious project configurations could abuse hooks, MCP integrations, and environment variables to achieve remote code execution and API credential theft when users cloned and opened untrusted repositories. Their summary states that the issues were patched before publication, but the architectural lesson is larger than the patch. They argue that repository-level configuration files became an active execution layer rather than harmless operational metadata. Check Point associated this research with CVE-2025-59536 and CVE-2026-21852. (Check Point Research)
That finding lines up uncomfortably well with Anthropic’s own documentation. The hooks reference says command hooks run with the full permissions of the system user. The sandboxing post says effective protection requires both filesystem and network isolation. Put those together and the implication is hard to miss: once an agentic tool can read files, run commands, connect tools, and load project-local configuration, repository content becomes part of the execution boundary. (مستندات كلود API)
For AI pentesting, this matters for two reasons. First, your harness will often interact with untrusted targets, untrusted repos, untrusted documents, or untrusted browser content. Second, pentesting teams are especially likely to wire together local scripts, proxy integrations, MCP servers, and project-specific automation. That means a poorly designed harness can be attacked by the very ecosystem it is using to test others. If you borrow one lesson from the Claude Code case, let it be this: configuration is part of runtime. Threat-model it that way.
What these cases mean in practice
The three cases above point to one shared conclusion. The risk in agentic systems is not only that the model will reason badly. The risk is that an execution path somewhere in the harness will accept untrusted input as if it were safe to run, safe to authorize, or safe to trust.
That is why the six-layer design is not ceremony. The engagement plane prevents accidental overreach. The hypothesis compiler narrows execution. Worker specialization reduces privilege spread. The verifier suppresses false proof. Persistent memory stops state loss from becoming narrative drift. The policy kernel keeps the tool plane under external control. Without those layers, you are betting the integrity of a pentest workflow on a model staying coherent and benevolent under adversarial conditions. The public record already says that is not enough. (NVD)
Reference architecture for an evidence-first AI pentest harness
The full system can be represented compactly:
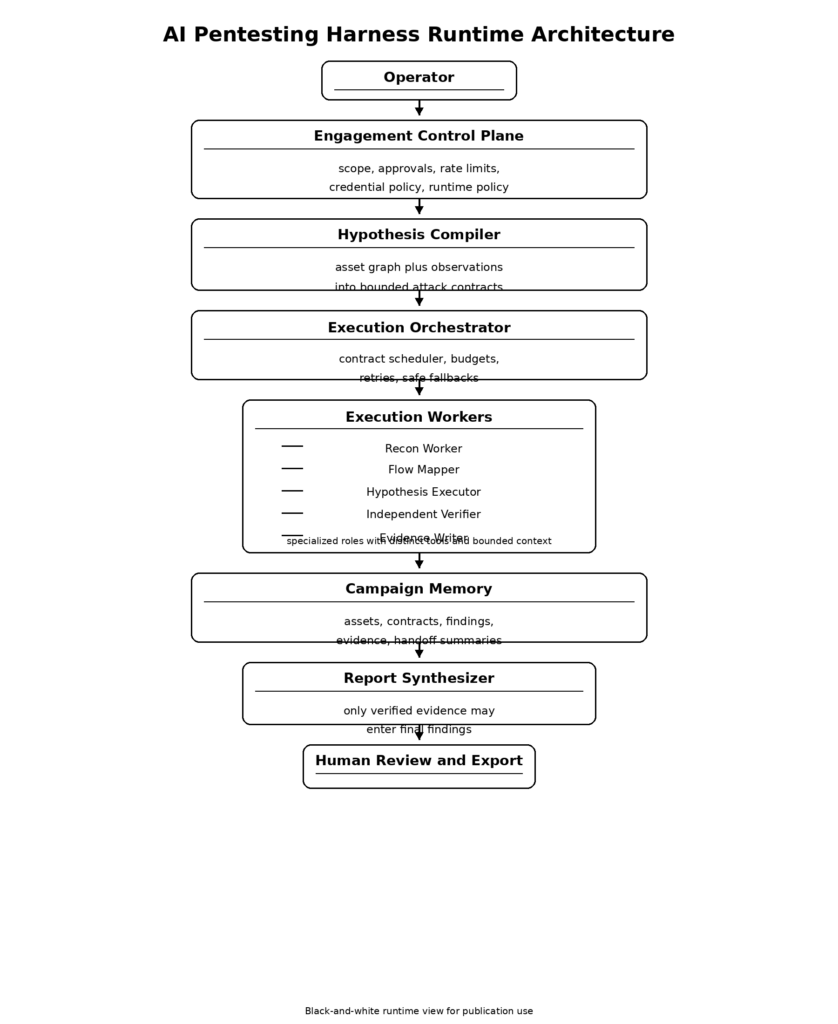
There are two reasons this shape works.
The first is that it matches how real testing unfolds. Recon produces possibilities. Flow analysis turns possibilities into attack ideas. Execution tests one bounded idea at a time. Verification decides whether the result deserves trust. Reporting happens only after that. NIST SP 800-115 and OWASP WSTG are very different documents, but both reinforce that testing is a process, not a single phase of tool output. (معهد NIST CSRC)
The second is that it matches Anthropic’s public observations about agents. Long tasks improve when work is decomposed, when handoff artifacts preserve state, and when a skeptical evaluator sits outside the generator. Specialized assistants improve context management. Verification criteria improve results. Sandboxing and policy boundaries make autonomy safer. (Anthropic)
A strong first version of this system does not need autonomous exploitation. It needs disciplined progression. The minimum viable harness should be able to:
- ingest scope and policy,
- build an asset graph,
- compile one contract at a time,
- execute bounded checks,
- replay them independently,
- persist evidence,
- and export a reportable artifact.
That is enough to prove the architecture before you add more daring behavior.
Data model, asset graph, attack contract, evidence bundle
The most important engineering choice in this kind of system is to stop centering everything on free-form chat and start centering everything on data objects.
The first object is the asset graph. This is not just a list of URLs. It is a graph of domains, endpoints, parameters, cookies, headers, identities, roles, JavaScript routes, object stores, admin surfaces, and observed transitions between them. Its purpose is not visualization alone. It is to give the harness a machine-usable model of where trust boundaries and attack edges might exist.
A stripped-down schema can look like this:
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class AssetNode:
id: str
type: str
labels: List[str]
attributes: Dict[str, str] = field(default_factory=dict)
@dataclass
class AssetEdge:
source: str
target: str
relation: str
evidence_refs: List[str] = field(default_factory=list)
The second object is the attack contract. That is the unit of work and the unit of evaluation. It should be durable, typed, resumable, and auditable. If the system cannot tell you which contract it is executing, what success means, and what evidence is required, it is still operating as a conversational agent rather than as a pentest harness.
The third object is the evidence bundle. This is what a reportable finding is built from. Not a paragraph. Not a summary. A bundle.
{
"finding_id": "idor-orders-001",
"status": "verified",
"severity_candidate": "high",
"contracts": ["idor-orders-001"],
"artifacts": {
"requests": ["req-1.json", "req-2.json"],
"responses": ["res-1.json", "res-2.json"],
"screenshots": ["browser-1.png"],
"har": ["session-a.har"],
"logs": ["verifier-notes.md"]
},
"reproduction": {
"identities": ["user_a", "user_b"],
"steps": [
"Login as user_a",
"Capture order id",
"Login as user_b",
"Replay GET against user_a order id"
],
"negative_case": "Random non-existent ID returns 404"
},
"confidence": "high",
"review_required": true
}
This is where another restrained product observation fits naturally. Recent Penligent material on Claude as a pentest copilot makes a point that is easy to agree with even if you remove the brand entirely: a strong system should emphasize editable reporting, reproducible proof of concept material, and verified findings rather than unverifiable AI narration. Public workflow-native pentest platforms that center those outputs are aiming at the right end of the problem. The hard part is not getting a model to sound smart. It is getting the workflow to preserve enough truth that somebody else can rerun it. (بنليجنت)
Implementation patterns and code
The core orchestrator logic does not need to be mysterious. It only needs to be disciplined.
A minimal loop might work like this:
def run_campaign(campaign):
while True:
contract = campaign.next_ready_contract()
if contract is None:
break
if not campaign.policy.allows(contract):
campaign.defer(contract, reason="policy gate")
continue
execution_result = campaign.executor.run(contract)
if execution_result.status == "rejected":
campaign.record_rejection(contract, execution_result)
continue
verification_result = campaign.verifier.run(contract, execution_result)
if verification_result.status == "verified":
bundle = campaign.evidence_writer.build_bundle(
contract, execution_result, verification_result
)
campaign.promote_finding(contract, bundle)
elif verification_result.status == "needs_review":
campaign.queue_human_review(contract, verification_result)
else:
campaign.record_rejection(contract, verification_result)
campaign.write_handoff()
What matters is not the syntax. It is the structure. The loop forces every candidate through the same progression: schedule, policy, execute, verify, persist. That pattern is the offensive-security translation of Anthropic’s generator-evaluator loop and their emphasis on verification criteria. (Anthropic)
The verifier can also enforce replay discipline with explicit case generation:
def build_replay_cases(contract, candidate):
cases = []
for identity in contract["required_identities"]:
cases.append({
"name": f"{contract['contract_id']}-{identity}-clean",
"session_profile": identity,
"request_spec": candidate["request_spec"],
"expected_signal": candidate["expected_signal"]
})
if contract.get("negative_case"):
cases.append({
"name": f"{contract['contract_id']}-negative",
"session_profile": contract["negative_case"]["identity"],
"request_spec": contract["negative_case"]["request_spec"],
"expected_signal": contract["negative_case"]["expected_signal"]
})
return cases
A browser-aware verifier can then add DOM snapshots or screenshots as supporting evidence, which is conceptually similar to how Anthropic’s evaluator used Playwright to inspect the running application rather than relying on static output alone. (Anthropic)
Finally, the policy engine can sit behind tool wrappers rather than living inside prompts:
def guarded_http_request(policy, request):
decision = policy.evaluate_http(request)
if decision.kind == "deny":
raise PermissionError(decision.reason)
if decision.kind == "defer":
raise RuntimeError("Human approval required")
return send_http(request)
That one choice is more important than it looks. If the model can only “promise” to respect scope but the runtime cannot enforce it, the harness is fragile by construction.
Evaluating the harness, not just the model
Anthropic’s “Demystifying evals for AI agents” makes the point directly: when you evaluate an agent, you evaluate the harness and the model working together. That should be a foundational assumption for AI pentesting too. (Anthropic)
The wrong evaluation question is “Did the model suggest the right next step?” The right evaluation questions are closer to these:
| متري | ما أهمية ذلك |
|---|---|
| Contract completion rate | Shows whether the harness can convert observations into finished test units |
| Verification pass rate | Measures how many candidate issues survive independent replay |
| False-positive suppression rate | Shows whether the verifier is doing real work |
| اكتمال الأدلة | Measures whether findings are actually reportable |
| Policy violation rate | Reveals unsafe or out-of-scope behavior |
| Human escalation rate | Helps calibrate autonomy versus oversight |
| Resume success rate | Tests whether long campaigns survive interruption |
| Patch retest accuracy | Measures whether the system can validate fixes without drifting |
The table is architectural rather than sourced, but it follows directly from Anthropic’s eval framing and from what standards like NIST SP 800-115 and OWASP WSTG expect from real testing work. A system that gets many candidate hits but produces weak evidence and frequent policy breaches is not better than a slower system with fewer, cleaner, replayable findings. (Anthropic)
PentestGPT’s benchmark methodology is useful here as well because it did not reduce performance to one final binary exploit result. The paper emphasizes sub-task progress and progressive accomplishment. That is a good instinct for harness evaluation. A campaign should get credit for accurate asset mapping, correct hypothesis rejection, and faithful negative-case handling, not just for “found exploit” moments. (arXiv)
Common failure modes
Most AI pentest systems do not fail because the model is too weak. They fail because the architecture lets the wrong thing count as success.
One common failure is letting the same worker execute and validate. Anthropic’s public work on long-running harnesses says separate evaluators are easier to tune toward skepticism than generators are. In pentesting, combining those roles is an invitation to inflate confidence. (Anthropic)
Another failure is treating memory as policy. Anthropic’s trustworthy-agent framework stresses that humans should retain control and that permissions matter. Memory helps continuity, but memory does not enforce scope. If your only scope control is a note the model read earlier, you do not have scope control. (Anthropic)
A third failure is giving broad shell or network access too early. Anthropic’s own sandboxing material is explicit that both filesystem and network isolation matter. The hooks docs are equally explicit that command hooks run with the full permissions of the system user. If a pentest harness starts with a fully privileged shell and a global network path, it is one compromised input away from becoming part of the problem. (Anthropic)
A fourth failure is writing reports from agent narration instead of evidence bundles. This is the shortest path to false positives that look professional. The more polished the language model is, the more dangerous this becomes, because the report reads like certainty even when the underlying proof is thin.
A fifth failure is believing that prompt injection is mostly an issue for consumer chatbots or browser assistants. Anthropic’s browser-use research and OWASP’s prompt injection material say otherwise. Any system that consumes untrusted content and can take actions on connected tools is in scope. An AI pentest harness lives in exactly that world. (Anthropic)
What a mature operating model looks like
A mature AI pentest harness does not try to erase the human. It changes where the human matters most.
Anthropic’s public trustworthy-agents framework frames this as keeping humans in control while still enabling agent autonomy. That maps cleanly to pentesting. The human should not have to manually copy every header into every replay request. The human should decide what risk class of action is acceptable, what counts as a reportable outcome, and when a candidate result is important enough to escalate. (Anthropic)
In practice, a mature operating model usually looks like this.
The operator approves the manifest and target set.
The harness performs read-only recon and builds a first asset graph.
The hypothesis compiler generates bounded contracts.
Execution workers run low-risk checks automatically.
The verifier promotes only independently reproducible results.
Higher-risk tests are deferred for operator approval.
Evidence bundles, not narration, feed the report.
After remediation, the same contracts are replayed for regression testing.
That operating model also makes it easier to combine tools rather than choosing one camp. Claude Code, per Anthropic’s own docs, is a strong governed workbench for repo-aware reasoning, local tooling, and flexible subagent workflows. Workflow-native pentest systems, including Penligent in its public materials, are optimized around target-facing verification, proof preservation, and report packaging. The mature posture is not to confuse those jobs. It is to understand where each one belongs. (مستندات كلود API)
Closing the loop
The most useful thing Claude Code contributes to AI pentesting is not a bag of commands. It is a way of thinking about agents as systems.
Anthropic’s public harness work says long tasks improve when context is managed deliberately, work is decomposed, evaluators are separated, and success is tied to concrete tests. PentestGPT says automated pentesting improves when context loss is treated as a design problem rather than as a prompt problem. NIST and OWASP remind us that security testing is a disciplined process with planning, execution, analysis, and reporting, not a clever sequence of guesses. Real CVEs in Langflow and real research into Claude Code’s own repo-level execution surface show what happens when agentic systems blur the line between convenience and control. (Anthropic)
So the right ambition is not “make the model feel more autonomous.” The right ambition is to build a harness that can hold state, preserve scope, separate planning from action, separate action from validation, and separate evidence from narration.
That is the difference between an AI that helps with pentesting and a pentest workflow that can actually be trusted.
Further reading and references
- Anthropic, Effective harnesses for long-running agents. (Anthropic)
- Anthropic, Harness design for long-running application development. (Anthropic)
- Anthropic, Demystifying evals for AI agents. (Anthropic)
- Anthropic, Agent SDK overview. (مستندات كلود API)
- Anthropic, Best Practices for Claude Code. (كلود)
- Anthropic, Create custom subagents. (مستندات كلود API)
- Anthropic, Hooks reference. (مستندات كلود API)
- Anthropic, Beyond permission prompts, making Claude Code more secure and autonomous. (Anthropic)
- Anthropic, Claude Code auto mode, a safer way to skip permissions. (Anthropic)
- Anthropic, Mitigating the risk of prompt injections in browser use. (Anthropic)
- PentestGPT, USENIX Security 2024 presentation. (USENIX)
- PentestGPT paper, arXiv HTML version. (arXiv)
- NIST SP 800-115, Technical Guide to Information Security Testing and Assessment. (معهد NIST CSRC)
- OWASP Web Security Testing Guide. (OWASP)
- OWASP AI Testing Guide. (OWASP)
- OWASP Agentic Security Initiative and Top 10 for Agentic Applications 2026. (مشروع OWASP Gen AI Security Project)
- OWASP LLM01 Prompt Injection. (مشروع OWASP Gen AI Security Project)
- Model Context Protocol, Security Best Practices. (بروتوكول سياق النموذج)
- Model Context Protocol, Authorization specification. (بروتوكول سياق النموذج)
- NVD, CVE-2025-3248. (NVD)
- NVD, CVE-2026-33017. (NVD)
- Langflow GitHub advisory for CVE-2026-33017. (جيثب)
- Check Point Research, Caught in the Hook, RCE and API Token Exfiltration Through Claude Code Project Files. (Check Point Research)
- Check Point Research, summary of Claude Code flaws. (Check Point Blog)
- AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (بنليجنت)
- AI Pentest Copilot, From Smart Suggestions to Verified Findings. (بنليجنت)
- Claude AI for Pentest Copilot, Building an Evidence-First Workflow With Claude Code. (بنليجنت)
- Claude Code for Pentesting vs Penligent, Where a Coding Agent Stops and a Pentest Workflow Starts. (بنليجنت)
- Claude Code Security and Penligent, From White-Box Findings to Black-Box Proof. (بنليجنت)
- Penligent homepage. (بنليجنت)

